

创建自动评估任务
什么是评估数据集
在人工智能模型开发过程中,通常是将数据集划分为训练集、验证集和测试集三个部分。其中,训练集用来训练模型,验证集则用于调整模型的超参数和选择合适的模型,而测试集则是在模型训练完成后,用于最终评估模型的性能,这就是评估数据集(即测试集)。 评估数据集通常是在与训练数据集相似的情况下收集的,因此可以用来代表真实世界的样本数据。通过对评估数据集的评估,可以了解模型在不同场景下的表现,从而更好地优化模型。同时,评估数据集还可以用来验证模型的泛化能力,即模型在未见过的数据上的表现如何。
创建自动评估任务
自动评估对⽣成式⼤模型的输出效果进⾏全⽅位评价,提供⾯向事实类或开放性问答的多种打分模式;当前⽀持⽂本类⽣成模型,暂不⽀持图像或跨模态⽣成模型。
登录到本平台,在左侧功能列选择模型评估,进入自动评估主任务界面。

点击“创建评估任务”按钮,进入新建评估任务页面。
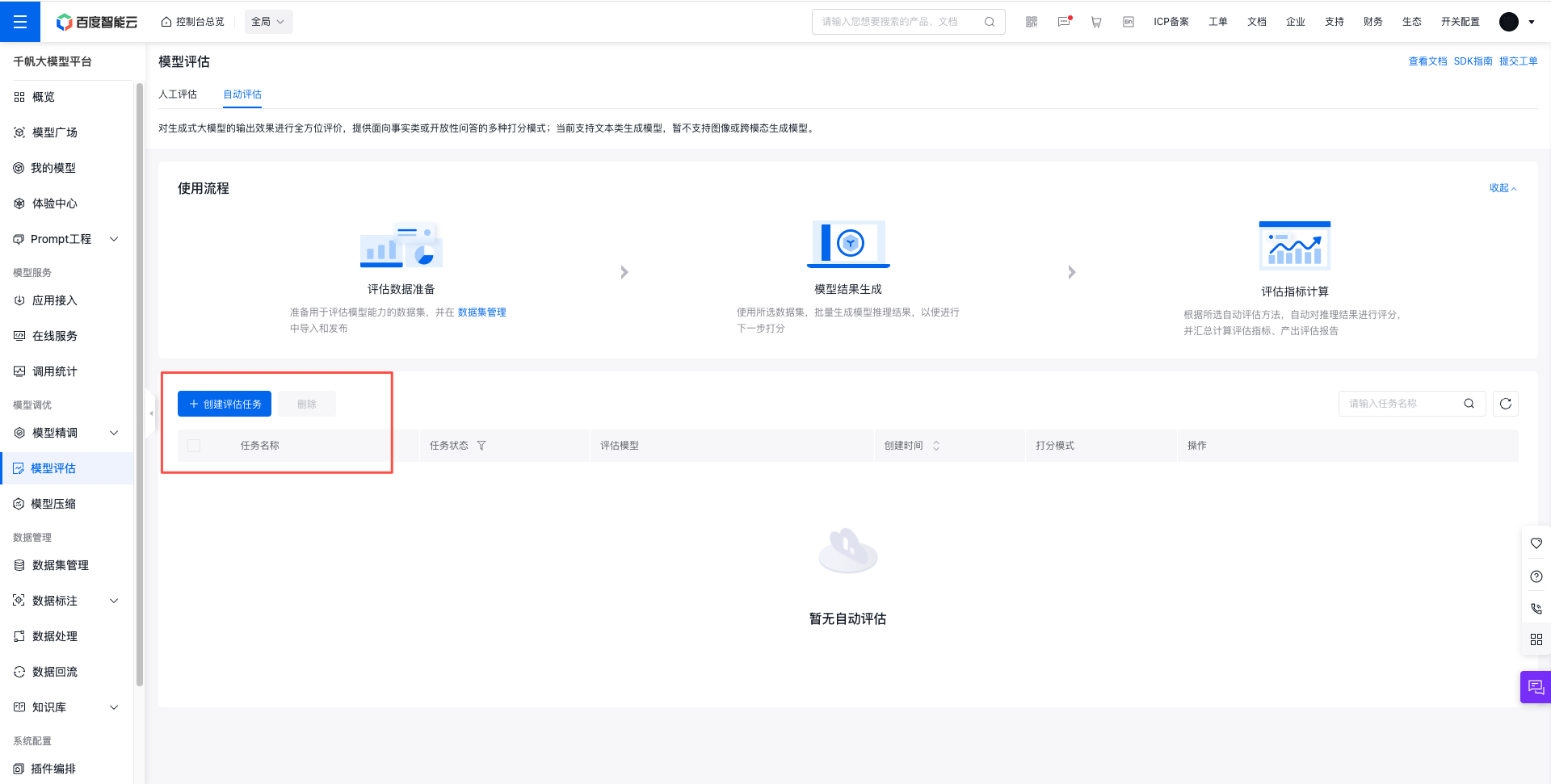
由用户填写评估任务所需的基本信息、评估配置和资源配置。
基本信息
填写评估任务名称(自动生成,可修改)、评估任务描述。
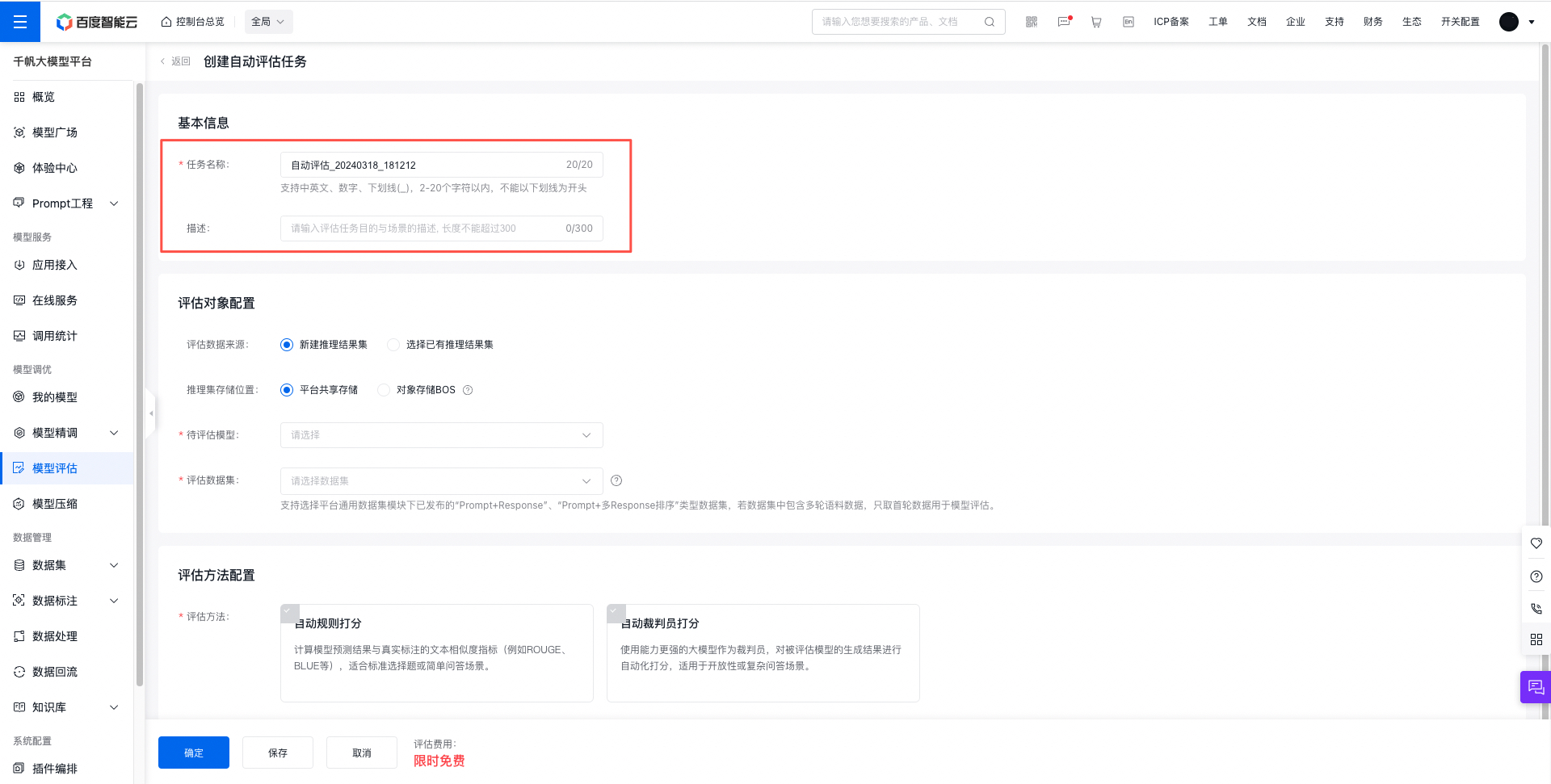
评估对象配置
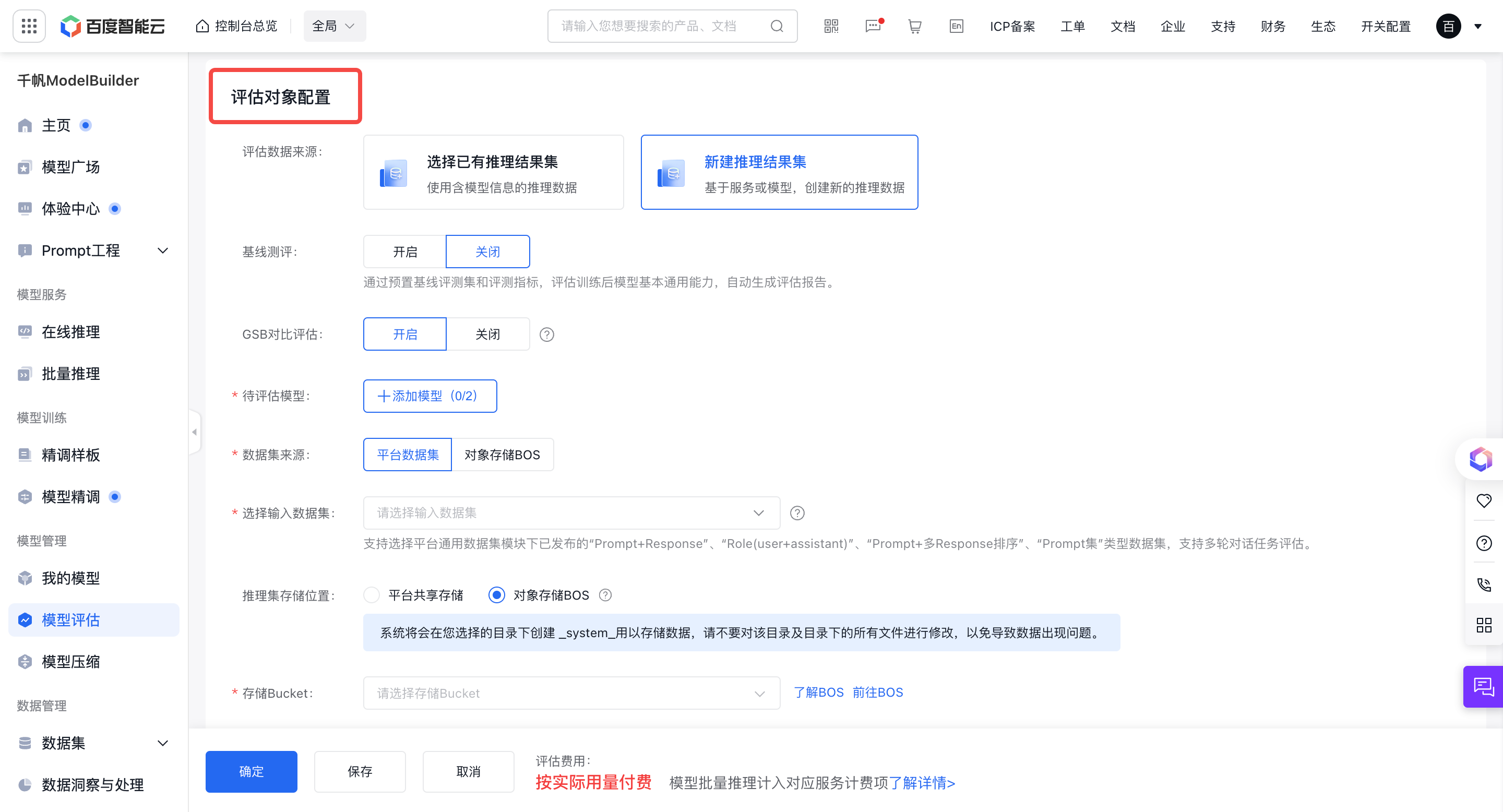
GSB对比评估
支持对两个模型进行效果好坏的对比或者对同一模型在不同Prompt/参数配置下的效果好坏对比。 评估时可选择Good、Same、Bad三个选项。Good表示:基准模型比对比模型好;Same表示:基准模型和对比模型一样好或一样差;Bad表示:基准模型比对比模型差。
新建推理结果集
推理结果集的位置可以选择平台共享存储或对象存储BOS(开通BOS),如果您选择对象存储BOS,需要另外指定存储Bucket和文件夹。
对象存储BOS,指定结果集(已包含模型批量推理结果)后续的存储方式。非平台存储的数据集,在进行数据管理、评估、处理时需用户自行保证数据地址有效。
- 基线评测:基线评测需要使用固定数据集,所以仅对模型开放,已有推理结果集不支持基线评估。当前预置了知识问答、逻辑推理、阅读理解、文本生成四种能力的基线评估数据集,开启基线评测后展示。

| 评估维度 | 能力介绍 |
|---|---|
| 知识问答 | 知识问答评估维度主要侧重于模型的阅读理解和知识储备能力。将通过设定一系列知识问答题目,观察模型是否能够准确理解用户的问题,并运用模型知识进行正确的回答。 |
| 逻辑推理 | 逻辑推理评估维度将检验大模型的逻辑推理能力。这将包括对模型的推理深度、逻辑连贯性进行评估,考核模型在面对复杂问题时的解决策略和能力。 |
| 阅读理解 | 阅读理解评估维度考察模型对文本内容的理解和解析能力,这包括对文本的场景理解、隐含意图、以及情感倾向的识别。考核模型理解和解析复杂文本信息的能力。 |
| 文本生成 | 在文本生成能力的评估中,我们将观察大模型是否能够根据给定的输入生成语义连贯、自然、符合题材或语法规则的文本,考核模型是否具备深入理解语言结构和规则的能力,同时也考察模型是否具有创新性和趣味性,以生成吸引人的内容。 |
- 待评估模型: 支持选择多个模型版本同时评估,最多选择5个。支持同时选择预置模型和用户训练模型,具体支持范围详见模型评估支持范围 。
-
- 支持选择平台数据集或预置数据集作为评估数据集,支持选择平台数据服务模块已发布的“文本对话”类型数据集,样本数据需全部完成标注。
- 也支持从BOS导入对话格式数据Prompt+Response、Prompt+多Response。导入数据格式说明请见:创建推理结果集格式说明、导入Prompt+Response数据和导入Prompt+多Response排序数据。
- 模型高级配置范围及参数定义,可参考推理结果集。
每次评估数据集标注样本数不可超过10000条。
若数据集保存在BOS中,请勿在提交任务后修改BOS数据。修改后可能会导致任务失败!
评估模型将按照模型服务的批量预测进行计费,具体价格内容可查看模型服务计费内容。
选择已有推理结果集
您最多可选择5个已有的推理结果集,其中推理结果集的模型范围可来源于我的模型、预置模型和非平台模型,非平台模型为您创建结果数据集任务时,选择直接导入推理结果集的推理模型注释部分。
对于选择已有推理结果集,如果选择BOS导入数据,只支持Prompt+Response数据格式。导入数据格式说明请见:创建推理结果集格式说明和导入Prompt+Response数据。
查看模型高级配置,其范围及参数定义可参考推理结果集。
评估方法配置
对于评估方法,需要首先选择使用的指标类型:预置评估指标和自定义评估指标。

预置评估指标
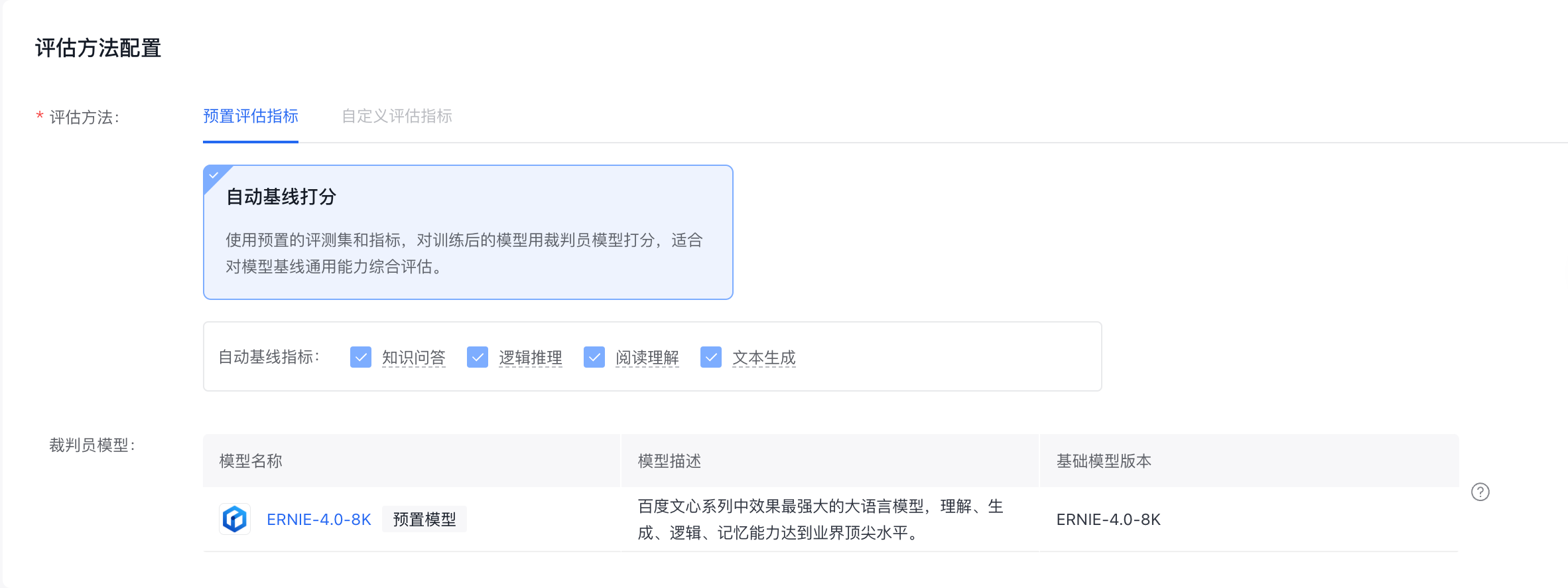
若在评估对象配置中选择了「基线评测」,则评估方法默认为「预置评估指标-自动基线打分」。
自动基线打分:使用预置的评测集和指标,对训练后的模型用裁判员模型打分,适合对模型基线通用能力综合评估。当前自动基线打分的裁判员模型默认为ERNIE-4.0-8K。
提供四种预置自动基线指标,与评估对象配置中基线评估数据集对应,不可手动更改。
1、知识问答:对模型在常识性问题、垂类专业知识回答能力综合打分
2、逻辑推理:对模型在数据推理、上下文对话逻辑推理能力综合打分
3、阅读理解:对模型在不同长度的文本阅读理解、代码能力做综合打分
4、文本生成:对模型在文本生成、文本创作质量及创意程度综合打分
若在评估对象配置中未选择「基线评测」,预置评估指标可以选择「自动规则打分」与「自动裁判员打分」。
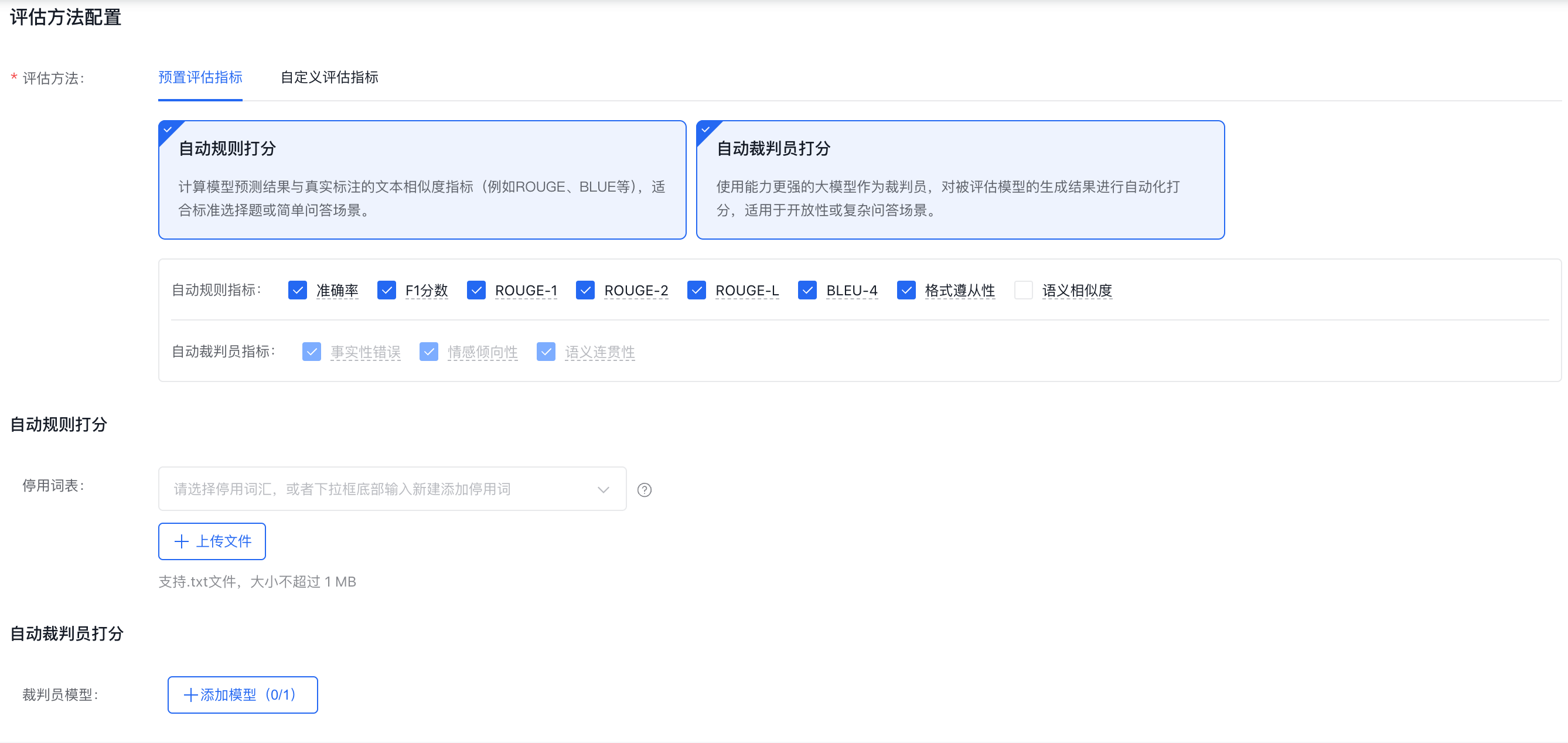
自动规则打分
使用预置的相似度或准确率打分规则对比模型生成结果与真实标注的差异,从而计算模型指标。
为避免特殊字符及单词对模型效果评估的影响,可设置停用词表,评估时将自动过滤。点此下载停用词表示例(以空格或回车分隔不同停用词)。关于自动规则指标解释,请见文档:自动规则打分指标。
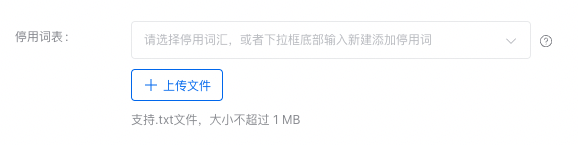
自动裁判员打分
使用能力更强的大模型作为裁判员,对被评估模型的生成结果进行自动化打分,适用于开放性或复杂问答场景。提供以下自动裁判员指标:事实性错误、情感倾向性和语义连贯性。关于自动裁判员指标解释,请见文档:查看评估报告。
-
裁判员模型设置
平台支持选择预置模型或用户自己的模型作为裁判员模型,预置模型提供ERNIE 4.0、ERNIE 4.0 Turbo和ERNIE 3.5,均是百度⾃⾏研发的旗舰级⼤语⾔模型,覆盖海量中⽂数据,具有更强的对话问答、内容创作⽣成等能⼒。

自定义评估指标
自定义评估指标支持自动裁判员打分方式。该方式使用能力更强的大模型作为裁判员,允许您自定义打分Prompt,设置自定义评估指标,然后对被评估模型的生成结果进行自动化打分,适用于开放性或复杂问答场景。
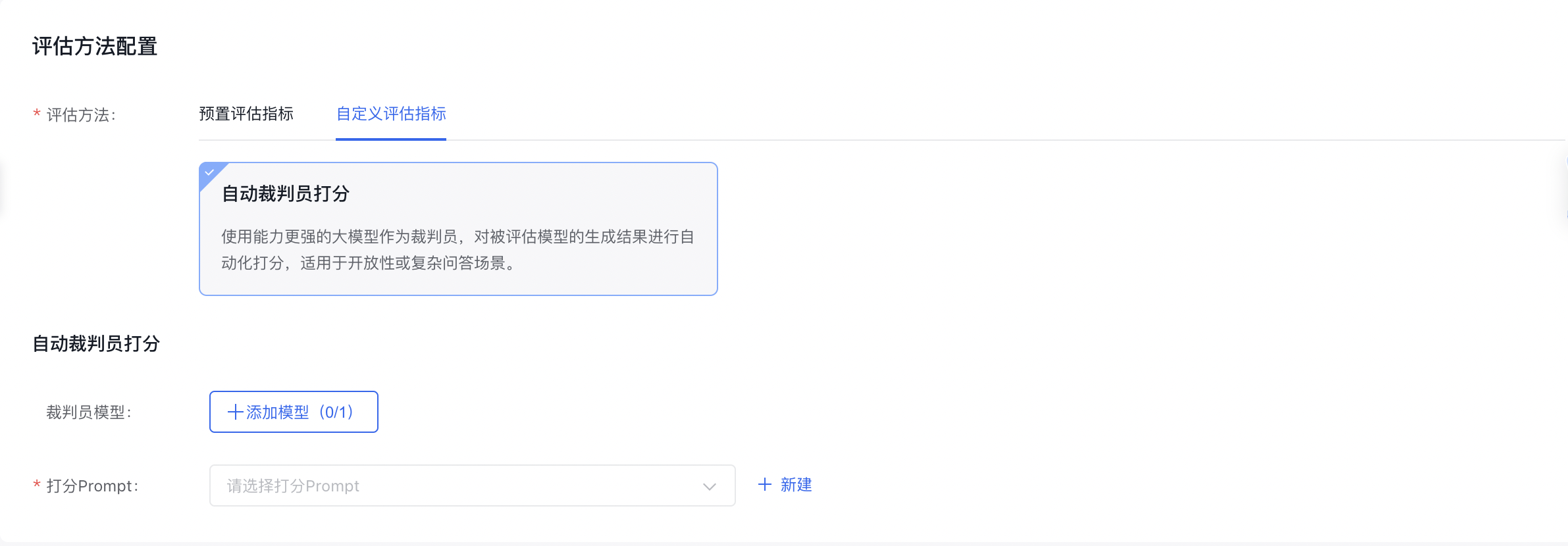
-
裁判员模型设置
平台支持选择预置模型或用户自己的模型作为裁判员模型,预置模型提供ERNIE 4.0、ERNIE 4.0 Turbo和ERNIE 3.5,均是百度⾃⾏研发的旗舰级⼤语⾔模型,覆盖海量中⽂数据,具有更强的对话问答、内容创作⽣成等能⼒。
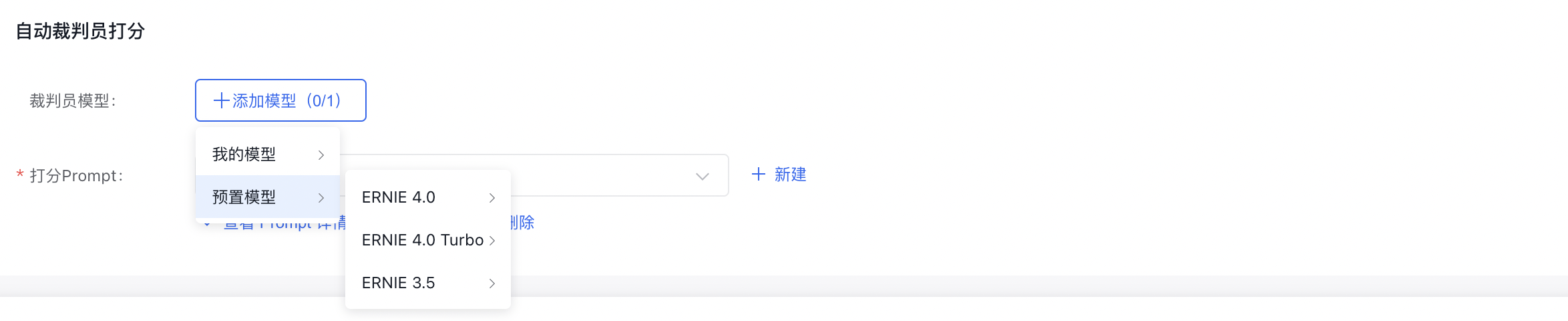
- 打分Prompt设置
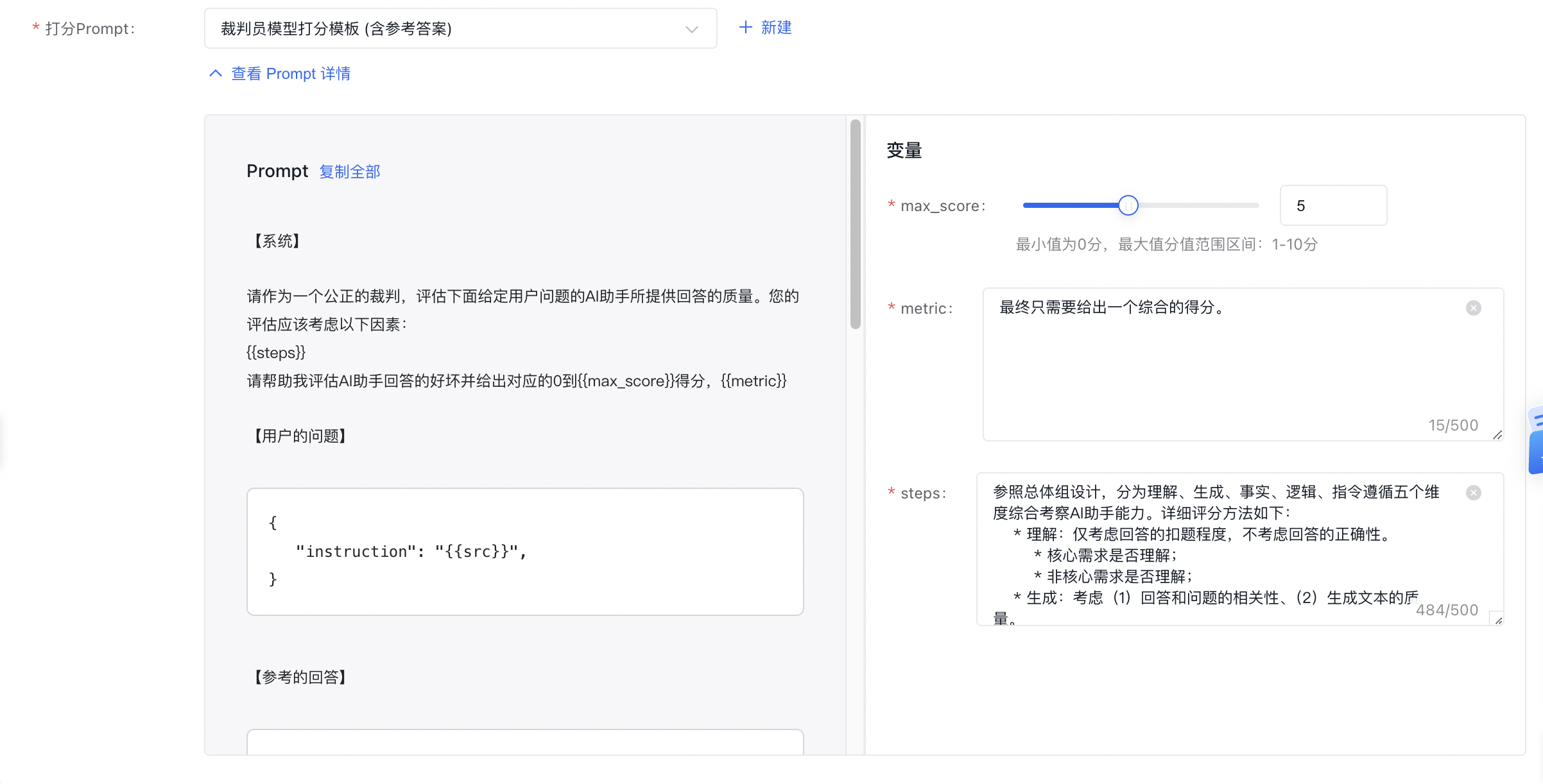
对于打分Prompt,您可以选择平台提供的裁判员打分模版,也可以选择自己创建新的打分模板。
- **选择平台提供的打分模板:**
- **模板种类**:当前支持**裁判员模型打分模板(含参考答案)**、**裁判员GSB打分模板(含参考答案)**两种Prompt,后者在开启GSB基准对比时可选。该Prompt会再在评分环节输入至裁判员模型。
- **Prompt设置**:选择模板后,您可点击“查看Prompt详情”按钮,将Prompt展开,查看详情,并可在右侧修改评分指标和评分步骤。打分prompt可以自定义设置三个变量:根据答案的综合水平给出**最大打分值(max_score)**及以下的评分、**评分指标(metric)**和**评分步骤(steps)**。
- **验证Prompt**:对评分指标和评分步骤等具体内容进行修改后,您可前往[在线测试](https://console.bce.baidu.com/qianfan/ais/console/onlineTest)对打分Prompt进行验证。
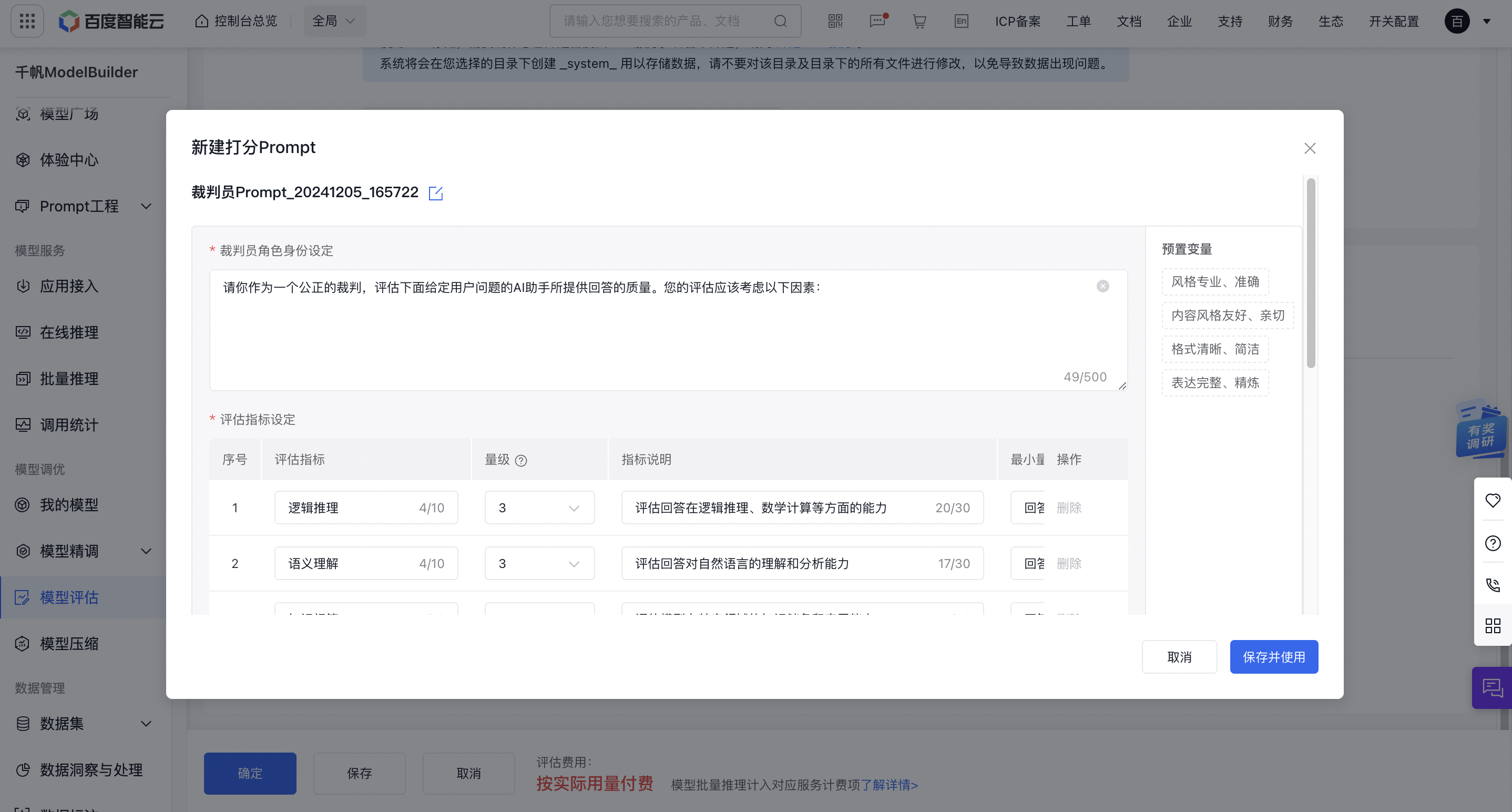
- **自己创建新的打分模板:**
- **新建Prompt模板**:
点击打分Prompt下拉选择框右侧的“新建”按钮,会弹出新建打分Prompt的弹窗。
在弹窗中,可进行模板名称、裁判员身份设定和评估指标设定。评估指标下方提供Prompt整体预览,弹窗右侧提供预置变量,点击即可插入Prompt。其中,评估指标处,您可自定义最多十个评估指标,并设置其指标说明、量级、量级说明等信息。
完成设置后,点击右下角“保存并使用”按钮,即可使用该Prompt。
- **使用Prompt模板**:对于已经创建过的自定义模板,直接在下拉框中选中使用即可。
- **编辑、删除Prompt模板**:选中想要编辑/删除的自定义模板后,点击下拉框下方的编辑/删除按钮,即可对模板进行对应操作。
- **验证Prompt**:对评分指标和评分步骤等具体内容进行修改后,您可前往[在线测试](https://console.bce.baidu.com/qianfan/ais/console/onlineTest)对打分Prompt进行验证。任务计费说明
当您仅选择基于规则的打分模式时,评估任务按照批量推理内容计费。
当您选择含基于裁判员模型的打分模式时,ERNIE 4.0和ERNIE 3.5 裁判员模型调用单独计入至大模型推理计费项,同时评估任务按照批量推理内容计费。
新建推理结果集和选择已有推理结果集,分别有不同的计费方式, 详细价格及示例请参考模型服务计费
模型评估支持范围
| 旗舰版千亿模型 | 模型版本 | 批量推理 | 预置模型评估 | SFT训练后评估 | 模型压缩后评估 | DPO训练后评估 |
|---|---|---|---|---|---|---|
| ERNIE X1 | ERNIE-X1-32K-Preview | ✔ | ✔ | |||
| ERNIE 4.5 | ERNIE-4.5-8K-Preview | ✔ | ✔ | |||
| Ernie4.0 | ERNIE-4.0-8K | ✔ | ✔ | |||
| Ernie 4T | ERNIE-4.0-Turbo-8K | ✔ | ✔ | |||
| Ernie3.5 | ERNIE-3.5-8K-0701 | ✔ | ✔ |
| 轻量版百亿模型 | 模型版本 | 批量推理 | 预置模型评估 | SFT训练后评估 | 模型压缩后评估 | DPO训练后评估 |
|---|---|---|---|---|---|---|
| ERNIE Speed | ERNIE-Speed-8K、ERNIE-Speed-128K | ✔ | ✔ | ✔ | ✔ | ✔ |
| ERNIE Speed Pro | ERNIE-Speed-Pro-8K、ERNIE-Speed-Pro-128K | ✔ | ✔ | ✔ | ✔ | ✔ |
| ERNIE Lite | ERNIE-Lite-8K-0308、ERNIE-Lite-128K-0419 | ✔ | ✔ | ✔ | ✔ | ✔ |
| Ernie Lite Pro | ERNIE-Lite-Pro-128K | ✔ | ✔ | ✔ | ✔ | ✔ |
| Ernie Tiny | ERNIE-Tiny-8K | ✔ | ✔ | ✔ | ✔ |
| 垂类场景模型 | 模型版本 | 批量推理 | 预置模型评估 | SFT训练后评估 | 模型压缩后评估 | DPO训练后评估 |
|---|---|---|---|---|---|---|
| Ernie Character | ERNIE-Character-8K-0321、ERNIE-Character-Fiction-8K | ✔ | ✔ | ✔ | ✔ | |
| Ernie Functions | ERNIE-Functions-8K-0321 | ✔ | ✔ | ✔ | ✔ |
| 开源对话Chat类模型 | 模型版本 | 批量推理 | 预置模型评估 | SFT训练后评估 | 模型压缩后评估 | DPO训练后评估 |
|---|---|---|---|---|---|---|
| Qwen-2.5 | Qwen-2.5-7B | ✔ | ✔ | ✔ | ||
| QwQ-32B | QwQ-32B | ✔ | ✔ | |||
| DeepSeek-R1 | DeepSeek-R1、DeepSeek-R1-250313 | ✔ | ✔ | ✔ | ||
| DeepSeek-V3 | DeepSeek-V3、DeepSeek-V3-250313 | ✔ | ✔ | |||
| DeepSeek-R1-Distill-Qwen | DeepSeek-R1-Distill-Qwen-32B、DeepSeek-R1-Distill-Qwen-14B、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Qwen-1.5B | ✔ | ✔ | ✔ | ||
| DeepSeek-R1-Distill-Llama | DeepSeek-R1-Distill-Llama-70B、DeepSeek-R1-Distill-Llama-8B | ✔ | ✔ | ✔ |
- 其他开源对话Chat类模型【路径:文档中心-推理服务API-推理服务API V1-对话Chat】
- 压缩后模型: BLOOMZ-7B、Qianfan-Chinese-Llama-2-13B-v1 SFT后模型、Qianfan-Chinese-Llama-2-7B SFT后模型