

创建模型精调任务
更新时间:2025-06-26
接口描述
本接口用于创建模型精调任务。
权限说明
调用本文API,需符合以下权限要求,权限介绍及分配,请查看角色与权限控制列表、账号创建与权限分配。需具有以下任一权限:
- 完全控制千帆大模型平台的权限:QianfanFullControlAccessPolicy
- 完全控制千帆大模型平台模型调优的权限:QianfanModelTuningFullControlAccessPolicy
鉴权说明
调用本文API,使用“基于安全认证AK/SK”进行签名计算鉴权,即使用安全认证中的Access Key ID 和 Secret Access Key进行鉴权,具体鉴权认证机制参考HTTP调用鉴权说明。
请求结构
POST /v2/finetuning?Action=CreateFineTuningTask HTTP/1.1
Host: qianfan.baidubce.com
Authorization: authorization string
Content-Type: application/json
{
"jobId": "job-1xzycis4jm3b",
"parameterScale": "FullFineTuning",
"hyperParameterConfig": {
"epoch": 1,
"learningRate": 0.00003,
"maxSeqLen": 4096
},
"datasetConfig": {
"sourceType": "Platform",
"versions": [{
"versionId": "ds-he8srs01ym0b8fh7"
}],
"splitRatio": 20
}
}请求头域
除公共头域外,无其它特殊头域。
请求参数
- Query参数
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| Action | string | 是 | 方法名称,固定值CreateFineTuningTask |
- Body参数
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| jobId | string | 是 | 作业ID,可以通过以下方式获取该参数值,以SFT为例说明: 在控制台-模型精调页面,查看ID,如下图所示: 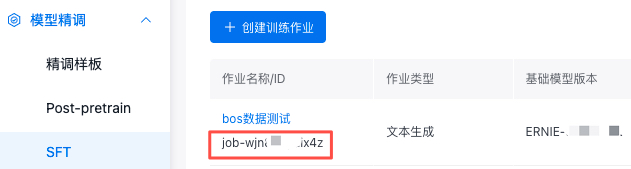 |
| incrementTaskId | string | 否 | 基础任务ID,说明: (1)如果是增量训练,该字段必传 (2)传了该字段,默认走增量训练 (3)基础任务的模型类型要和作业一致 (4)自定义模型作业不支持增量训练 |
| incrementCheckpointStep | int | 否 | 基础任务Step,说明:如果基础任务是多checkpoint任务,该字段必传 |
| parameterScale | string | 否 | 调优的参数规模,该字段取值详情参考模型支持情况 |
| hyperParameterConfig | object | 是 | 超参数配置,说明:该字段请查看本文hyperParameterConfig说明,也可以参考模型支持情况 |
| datasetConfig | object | 是 | 数据集配置 |
| corpusConfig | object | 否 | 混合语料配置 |
| modelConfig | object | 否 | 模型配置,说明:只支持自定义模型作业,此时该参数必传 |
| resourceConfig | object | 否 | 资源池配置 |
| rewardRule | object | 否 | 奖励规则 |
| rlMethod | string | 否 | 只有当创建RFT任务,此参数有效;可选值: · PPO · GRPO |
| rlhfConfig | object | 否 | 强化学习类型任务配置,说明:当创建强化学习类型任务时,此参数必填 |
rlhfConfig说明
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| rewardModelConfig | object | 是 | 奖励模型的配置 |
rewardModelConfig说明
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| taskId | string | 是 | 任务ID |
corpusConfig说明
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| generalCorpusProportion | double | 否 | 通用语料混入比例 ,说明: (1)取值范围 :大于0。默认为0,不混入此语料 (2)仅支持ERNIE系列模型使用此参数 |
| verticalCorpusProportion | double | 否 | 垂直语料混入比例 ,说明: (1)取值范围:大于0。默认为0,不混入此语料 (2)仅支持ERNIE系列模型使用此参数 |
| defaultCorpusProportion | double | 否 | 默认语料混入比例,说明: (1)取值范围:[0-100]。默认为0,不混入此语料 (2)仅支持开源系列模型使用此参数 |
| copyData | bool | 否 | 是否数据拷贝,说明: (1)如果在配置的混合比例下,需要混合的数据量超出了平台混合数据的总量。 (2)此参数作用于通用语料和垂直语料。 (3)可选值如下: · false:不重复,选择数据训练,默认为false · true:重复选择数据 |
| labels | List<string> | 否 | 混入语料任务类型,说明: (1)仅支持垂直混合语料使用此参数 (2)SFT和Post-pretrain支持的任务类型不同。 (3)SFT支持以下任务类型: · 知识问答:可分为两类,主观知识问答侧重获取个人见解、经验和观点,答案因人而异;客观知识问答则涉及可验证的事实和数据,答案基于可靠资料和逻辑推理,强调客观性和真实性。 · 文本创作:各类的文案、文学、创意等写作任务,可以涉及多种体裁,包括但不限于小说、诗歌、散文、剧本、广告文案、新闻报道、科技文档等。 · 表格问答:根据给定的表格信息进行问答的任务,要求模型能够从表格中提取信息,并回答相关问题。 · 信息抽取:从非结构化或半结构化的文本中抽取特定信息的任务,要求模型能够准确地找到并提取出需要的信息。 · 指令理解:理解用户给出的指令或命令的任务,并作出相应的合理动作或回答。包含了多种指令理解任务的组合。 · 标题生成:根据给定的内容生成相应的标题的任务,要求模型能够准确抓住文本的核心信息,并生成简洁而具有概括性的标题。 · 问题生成:根据给定的内容生成相应的问题的任务,要求模型能够从文本中提取出问题的关键信息,并生成符合规范的问题。 · 示例学习:通过给定的示例来理解任务的要求,要求模型能够从示例中学习到通用的模式或规律,并应用到类似的任务中。 · 文本属性分析:分析文本中的属性或特征的任务,要求模型能够识别文本中的各种属性,如观点、主题、意图等。 · 摘要:对文本进行概括性提取的任务,要求模型能够从文本中提取出最重要或最具代表性的信息,生成简洁而完整的摘要。 · 语言推理:理解和推断文本中的逻辑关系和语义关系的任务,要求模型能够根据文本内容进行推理和判断。 · 阅读理解:理解和回答与给定文本相关的问题的任务,要求模型能够从文本中获取必要的信息,并作出准确的回答。 · 文本分类:将文本分类到预定义类别的任务,要求模型能够根据文本内容确定其所属的类别或标签。 · Json转文本:将结构化的json数据转换为可读的自然语言文本。这项任务在很多应用场景中都很有用,比如生成报告、用户界面展示、自然语言接口等。 · 代码生成:代码生成指根据给定的要求生成相应的代码的任务,要求模型能够理解代码的要求,并生成符合要求的代码。 · 代码纠错:检测和修正代码中的错误的任务,要求模型能够识别代码中的错误,并提供正确的修正建议。 · 代码解释: 解释代码功能和逻辑的任务,要求模型能够理解代码的功能和实现方式,并用易于理解的语言进行解释。 · 理科试题:涉及自然科学知识的试题,要求模型能够理解科学知识,并回答相关问题。例如各学段的数学题目。 · 多轮对话:进行多轮交互的对话任务,要求模型能够理解上下文,并进行连贯和合理的对话。 · 角色扮演(多轮):使用大型语言模型进行角色扮演对话。在这个任务中,用户可以与大模型进行各类对话交互,大模型根据对话的内容和扮演的角色特点来生成回复,该任务经常被用于娱乐、教育等场景。 · 角色扮演(括号文学):是模型在对话中扮演文学作品中的角色,利用括号添加细腻的心理和动作描述,以丰富故事情节,打造沉浸式互动体验。 · 风格定制(多轮):通过特定风格类描述定制,使得大模型在生成文本时符合特定的风格要求。通过这种方式,可以定制语言模型的回复风格,使其更符合特定应用场景或个人喜好。 · 翻译:将一种语言的文字内容转换成另一种语言的任务。 · 专业考试:涉及专业知识的考试题目(主要为文科类),要求模型能够理解专业知识,并作出准确的回答或解释。 · Agent:智能助手根据用户请求执行特定任务,如查询信息或执行服务。 · NL2SQL:将自然语言转换成结构化查询语言的任务,要求模型能够理解自然语言的意图,并将其转换成能够执行的SQL查询语句。 · 记忆增强:AI助手根据用户个人信息和偏好,提供个性化服务和提醒。 (4)Post-pretrain支持以下任务类型: · 金融 · 医疗 · 广告传媒 · 电商 · 旅游 · 教育 · 交通物流 · 地产家装 · 法律 · 党政 · 游戏 · 科技 · 化工 · 能源 · 机械 |
| languages | List<string> | 否 | 混合通用/垂直语料的语言类型,说明: (1)仅支持Post-pretrain使用此参数 (2) 可选值如下: · en:英文 · cn:中文 · code:代码,仅支持通用语料 |
resourceConfig说明
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| idleResource | bool | 否 | 是否开启潮汐调度任务,说明: 目前只有SFT的任务,支持潮汐任务调度 |
datasetConfig说明
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| sourceType | string | 是 | 数据来源,可选值: · Platform · Bos |
| versions | List<object> | 是 | 数据集版本列表,说明:可以通过以下方法获取该数据版本值: 在控制台-数据集管理页面,查看某数据集版本,如下图所以: 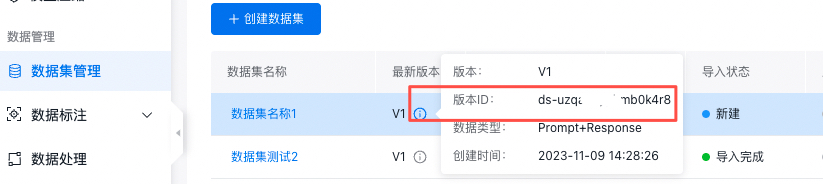 |
| splitRatio | double | 是 | 数据拆分比例,取值范围:[0,20] |
| validationDatasetSourceType | string | 否 | 验证集数据来源,可选值如下: · Platform |
| validationDatasetVersions | List<object> | 否 | 验证集数据版本列表 |
versions说明
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| versionId | string | 否 | 数据集版本ID,说明: (1) 当sourceType为Platform时,该字段必传 (2) 数据集必须是已发布的数据集 (3)可以通过以下方法获取该字段值,在控制台-数据集管理页面,查看某数据集版本ID,如下图所示:  |
| samplingRate | float | 否 | 数据集采样率,说明: (1)sourceType为Platform时,该字段有效 (2)取值范围:[0.01-10],默认值1 |
| versionBosUri | string | 否 | 数据集版本bos地址,说明: (1)当sourceType为Bos时,该字段必传 |
validationDatasetVersions说明
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| versionId | string | 否 | 数据集版本ID,说明: (1) 当sourceType为Platform时,该字段必传 (2) 数据集必须是已发布的数据集 (3)可以通过以下方法获取该字段值,在控制台-数据集管理页面,查看某数据集版本ID,如下图所示: |
| samplingRate | float | 否 | 数据集采样率,说明: (1)sourceType为Platform时,该字段有效 (2)取值范围:[0.01-10],默认值1 |
| versionBosUri | string | 否 | 数据集版本bos地址,说明: (1)当sourceType为Bos时,该字段必传 |
modelConfig说明
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| modelId | string | 是 | 模型ID |
| modelVersionId | string | 是 | 模型版本ID |
rewardRule说明
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| rewardFunc | string | 是 | 奖励函数,可选值如下: · check:字符串比较 · matching:字符串匹配 · similarity:字符串相似度对比 · math:数学答案匹配 |
| cfcTriggerHttpUrl | string | 否 | 自定义规则下,CFC函数触发器地址 |
hyperParameterConfig说明
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| epoch | int | 否 | 迭代轮次,说明:该字段取值详情参考模型支持情况 |
| learningRate | float | 否 | 学习率,说明:该字段取值详情参考模型支持情况 |
| batchSize | int | 否 | 批处理大小,说明:该字段取值更多详情参考模型支持情况 |
| maxSeqLen | int | 否 | 序列长度,说明:该字段取值更多详情参考模型支持情况 |
| loggingSteps | int | 否 | 保存日志间隔,说明:该字段取值更多详情参考模型支持情况 |
| warmupRatio | float | 否 | 预热比例,说明:该字段取值更多详情参考模型支持情况 |
| weightDecay | float | 否 | 正则化系数,说明:该字段取值更多详情参考模型支持情况 |
| loraRank | int | 否 | LoRA 策略中的秩,说明:该字段取值更多详情参考模型支持情况 |
| loraAlpha | int | 否 | 说明:该字段取值更多详情参考模型支持情况 |
| loraAllLinear | bool | 否 | LoRA 所有线性层,说明:该字段取值更多详情参考模型支持情况 |
| loraTargetModules | string | 否 | 说明:该字段取值更多详情参考模型支持情况 |
| loraDropout | float | 否 | 说明:该字段取值更多详情参考模型支持情况 |
| schedulerName | string | 否 | 说明:该字段取值更多详情参考模型支持情况 |
| Packing | string | 否 | 可选值:true、false 或 auto,默认值auto,说明:该字段取值更多详情参考模型支持情况 |
| globalBatchSize | int | 否 | 说明:该字段取值更多详情参考模型支持情况 |
| pseudoSamplingProb | float | 否 | 说明:该字段取值更多详情参考模型支持情况 |
| checkpointCount | int | 否 | 说明:该字段取值更多详情参考模型支持情况 |
| saveStep | int | 否 | 说明:该字段取值更多详情参考模型支持情况 |
| dpoBeta | float | 否 | 说明:该字段取值更多详情参考模型支持情况 |
| seed | int | 否 | 说明:该字段取值更多详情参考模型支持情况 |
| lrSchedulerType | string | 否 | 说明:该字段取值更多详情参考模型支持情况 |
| lrEnd | float | 否 | 说明:该字段取值更多详情参考模型支持情况 |
| power | int | 否 | 说明:该字段取值更多详情参考模型支持情况 |
| validationStep | int | 否 | 说明:该字段取值更多详情参考模型支持情况 |
| earlyStopping | bool | 否 | 说明:该字段取值更多详情参考模型支持情况 |
| earlyStopMetric | string | 否 | 说明:该字段取值更多详情参考模型支持情况 |
| early_stopping_threshold | int | 否 | 说明:该字段取值更多详情参考模型支持情况 |
| early_stopping_patience | int | 否 | 说明:该字段取值更多详情参考模型支持情况 |
| tensorParallelDegree | int | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| shardingParallelDegree | int | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| sharding | string | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| recompute | int | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| critic_learning_rate | float | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| clip_range_score | int | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| clip_range_value | int | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| clip_range_ratio | float | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| top_p | float | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| repetition_penalty | float | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| temperature | float | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| kl_coeff | float | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| checkpointSaveStrategy | string | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| perDeviceTrainBatchSize | int | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| maxPromptLen | int | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| maxSteps | int | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| freezeViT | bool | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| criticLearningRate | float | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| actorLearningRate | float | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| klCoeff | float | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| rolloutBatchSize | int | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| numSamplesPerPrompt | int | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| maxPromptLen4k | int | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| maxPromptLen8k | int | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| maxPromptLen16k | int | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| maxPromptLen32k | int | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| maxLength4k | int | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| maxLength8k | int | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| maxLength16k | int | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
| maxLength32k | int | 否 | 说明: 该字段取值更多详情参考模型支持情况 |
响应头域
除公共头域外,无其它特殊头域。
响应参数
| 名称 | 类型 | 描述 |
|---|---|---|
| requestId | string | 请求ID |
| result | object | 请求结果 |
result说明
| 名称 | 类型 | 描述 |
|---|---|---|
| jobId | string | 作业ID |
| taskId | string | 任务ID |
请求示例
curl --location 'https://qianfan.baidubce.com/v2/finetuning?Action=CreateFineTuningTask' \
--header 'Authorization: bce-auth-v1/f0ee7xxx8079702c13/2023-09-19T13:42:13Z/180000/host;x-bce-date/9a8cfb8ee58a8f44xxx' \
--header 'x-bce-date: 2023-09-19T13:37:10Z' \
--header 'Content-Type: application/json' \
--data '{
"jobId": "job-1xzycis4jm3b",
"parameterScale": "FullFineTuning",
"hyperParameterConfig": {
"epoch": 1,
"learningRate": 0.00003,
"maxSeqLen": 4096
},
"datasetConfig": {
"sourceType": "Platform",
"versions": [{
"versionId": "ds-he8srs01ym0b8fh7"
}],
"splitRatio": 20
}
}'响应示例
{
"requestId":"1bef3f87-c5b2-4419-936b-50f9884f10d4",
"result":{
"jobId":"job-n50985crhqq3",
"taskId":"task-nycp7bycjjn7"
}
}错误码
若请求错误,服务器将返回的JSON文本包含以下参数:
| 名称 | 描述 |
|---|---|
| requestId | 请求ID |
| code | 错误码 |
| message | 错误描述信息,帮助理解和解决发生的错误 |
例如错误返回:
{
"requestId":"6ba7b810-xxxc04fd430c8",
"code":"AccessDenied",
"message":"Access denied."
}更多其他错误码,也可以查看错误码说明。