

知识库管理
【数据管理-知识库】用于存储和管理各类知识文档,帮助用户以高效的方式存储和检索大量的知识库文档,实现快速管理企业私域知识,构建知识问答应用。
登录到本平台,在左侧功能列选择【知识库】,进入知识库主任务界面。千帆 AppBuilder 应用开发平台提供知识库管理系列功能的配套OpenAPI服务,具体接口文档请参考创建知识库、上传文件到知识库等。
创建知识库
点击知识库列表上方的【创建知识库】按钮,在展开的页面中填写新知识库的各项信息。
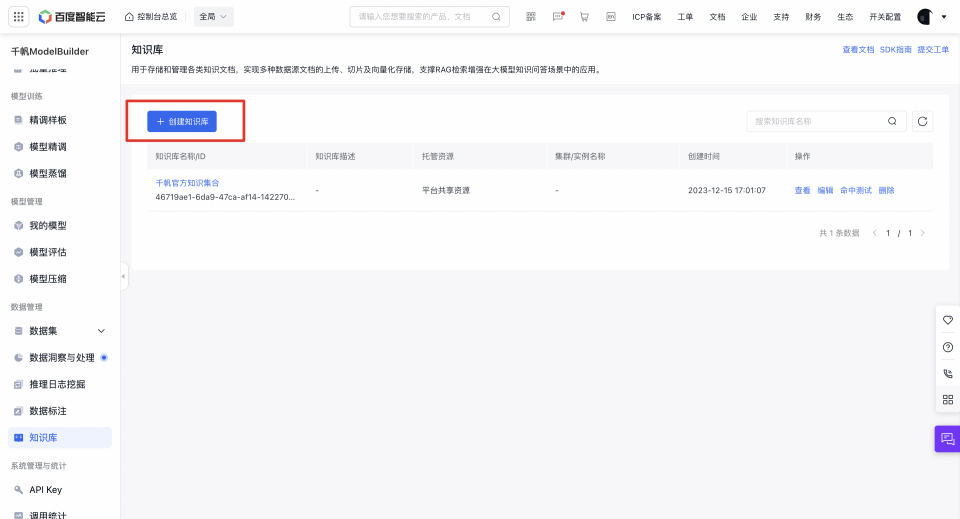
1. 知识库定义
【知识库定义】用于定义知识库的基本信息,包括知识库名称、知识库描述。
| 字段 | 填写注意事项 | 案例 |
|---|---|---|
| 知识库名称 | 知识库名称仅支持中文、英文、数字、下划线(_)、中划线(-)、英文点(.)(1~50字符) | 相机使用说明书 |
| 知识库描述 | 描述该知识库的内容和用途 | 主要包括相机的使用说明,为用户介绍相机的保修信息和服务条款、安全注意事项、基本操作、菜单设置、拍摄技巧等。 |
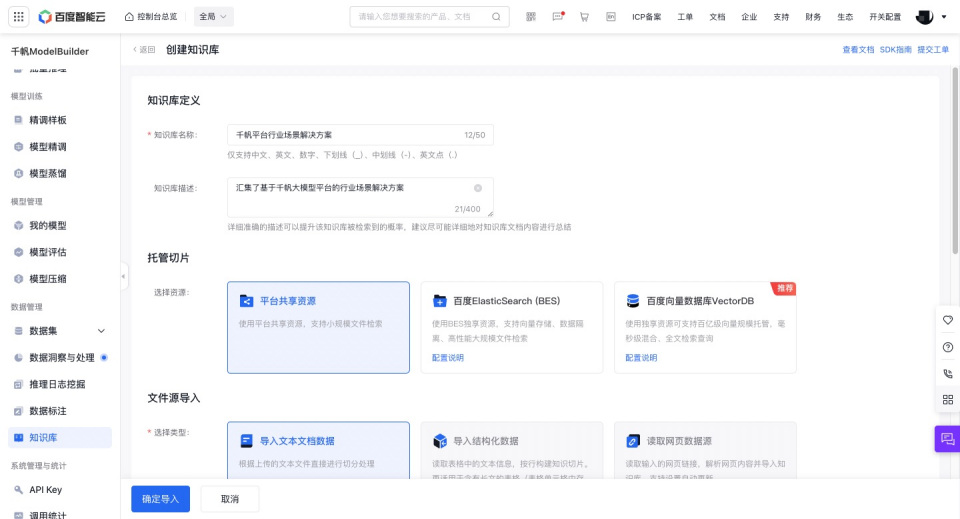
2. 托管切片
【托管切片】用于选择托管索引资源,选择结果会影响文件检索性能。
| 资源分类 | 说明 |
|---|---|
| 平台共享资源 | 不同用户之间共享资源,支持小规模的文件切片索引 |
| 百度ElasticSearch(BES)资源 | 需要付费使用,可独享资源,实现数据隔离,支持大规模的文件切片索引,索引性能更高,可以理解为有一块独立的资源空间 |
| 百度向量数据库VectorDB资源 | 支持百亿级向量规模托管、具备高性能访问和弹性高可用特性的向量数据库,适用于大规模向量数据检索、高性能应用及高可用性要求场景 |
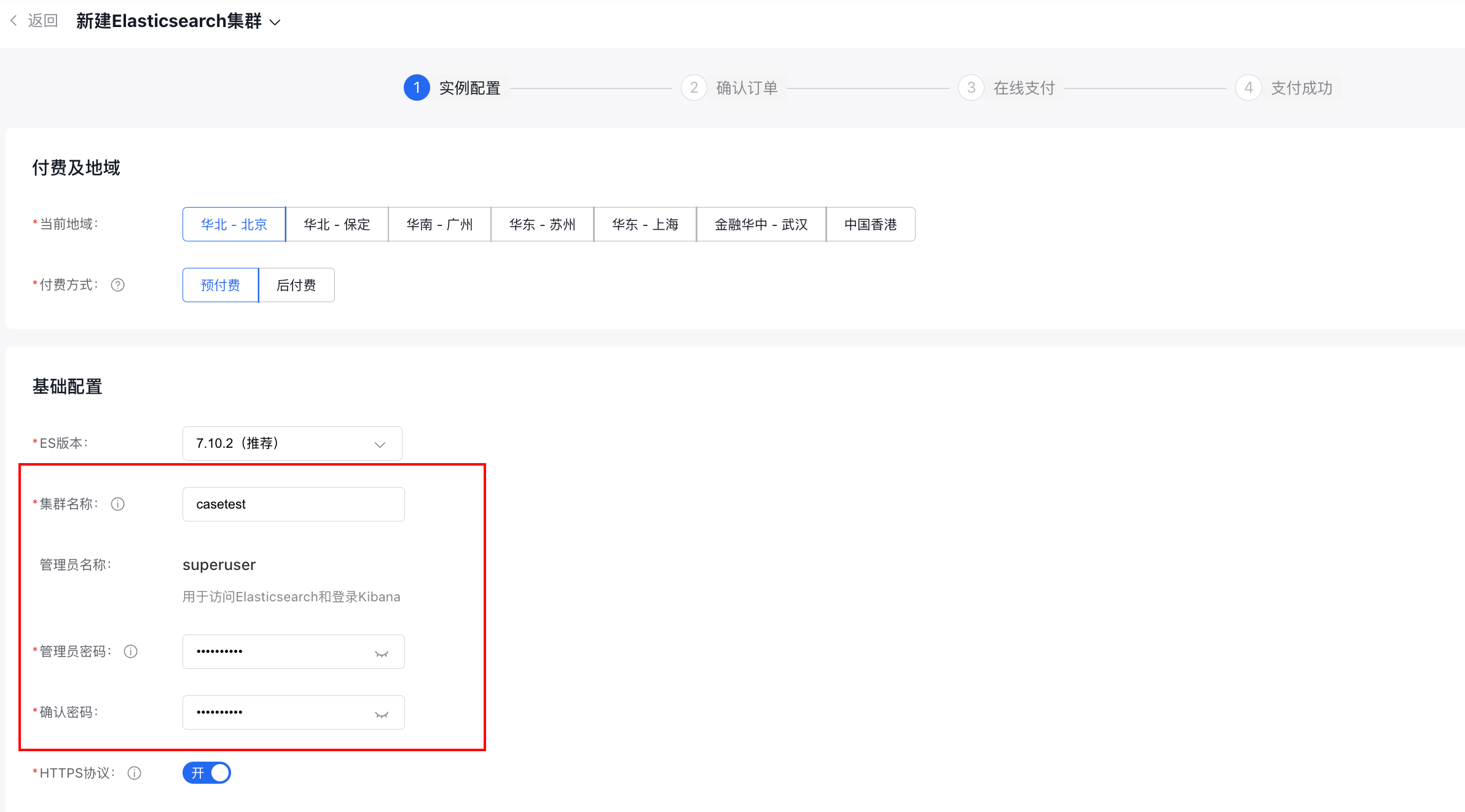
2.1. 使用百度ElasticSearch(BES)资源
- 若未开通 BES,请先开通 BES 资源,并创建 ElasticSearch 集群实例。
- 创建新 ElasticSearch 集群实例:设置BES集群名称及管理员密码,并填入知识库创建对应的表单位置。
调用已创建的 ElasticSearch 集群实例:点击集群名称链接进入集群详情页,查看集群名称与管理员名称。注意,管理员密码不可查看,若忘记密码请重新设置。
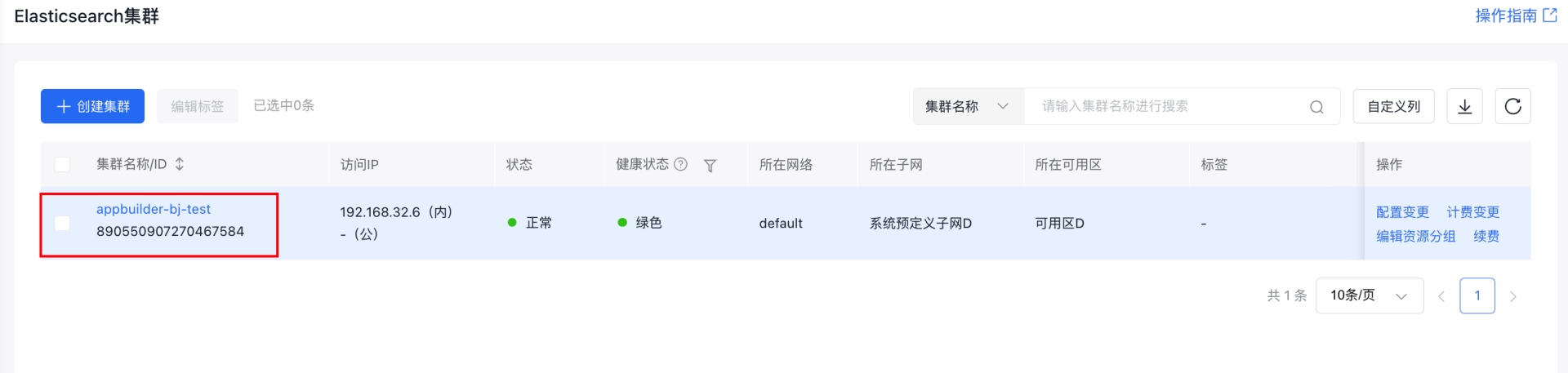
2.2. 使用百度向量数据库VectorDB
- 若未开通VDB,请先开通 VDB 资源,并创建百度VectorDB实例。
- 新用户可选择“测试版”,创建试用VDB实例。
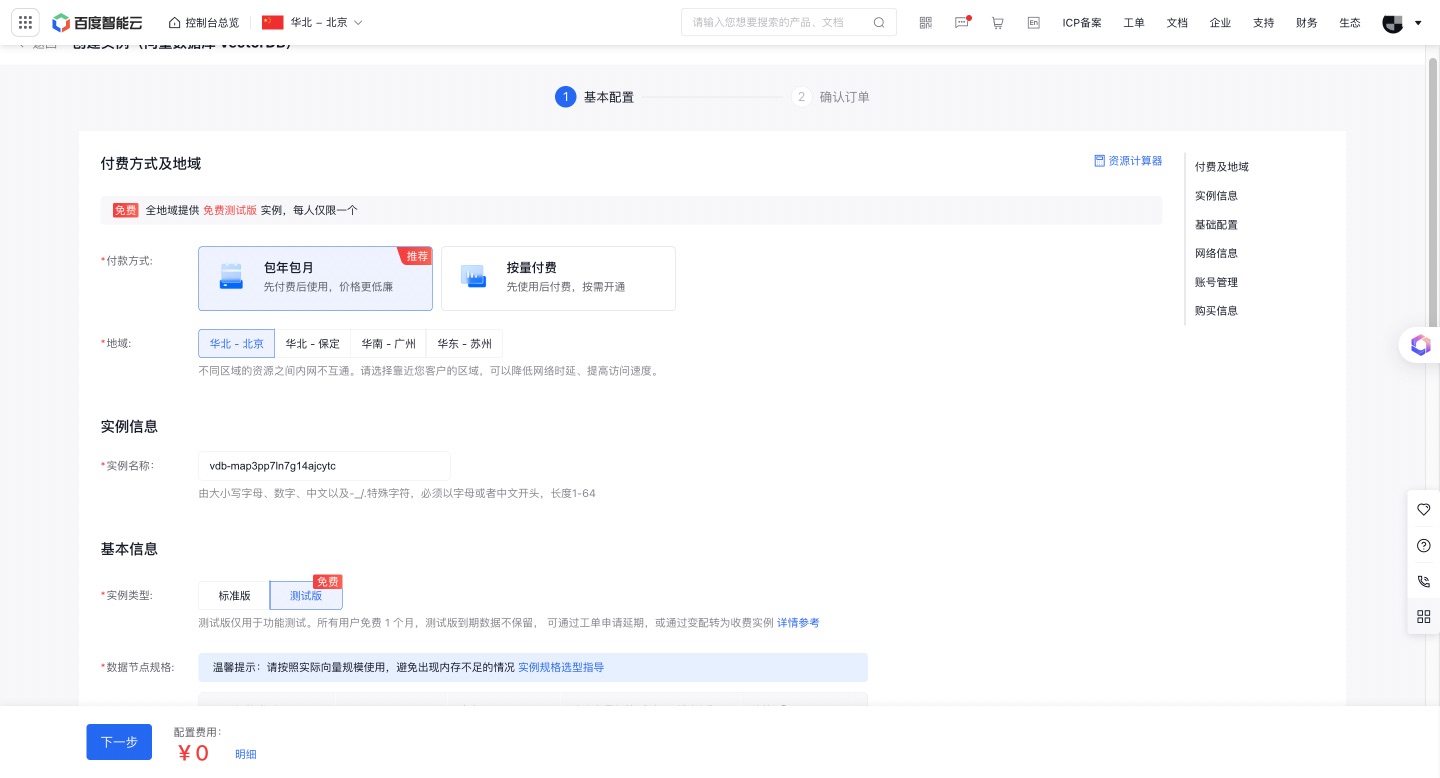
资源创建成功后回到知识库,选择相应的实例。
 界面。
界面。
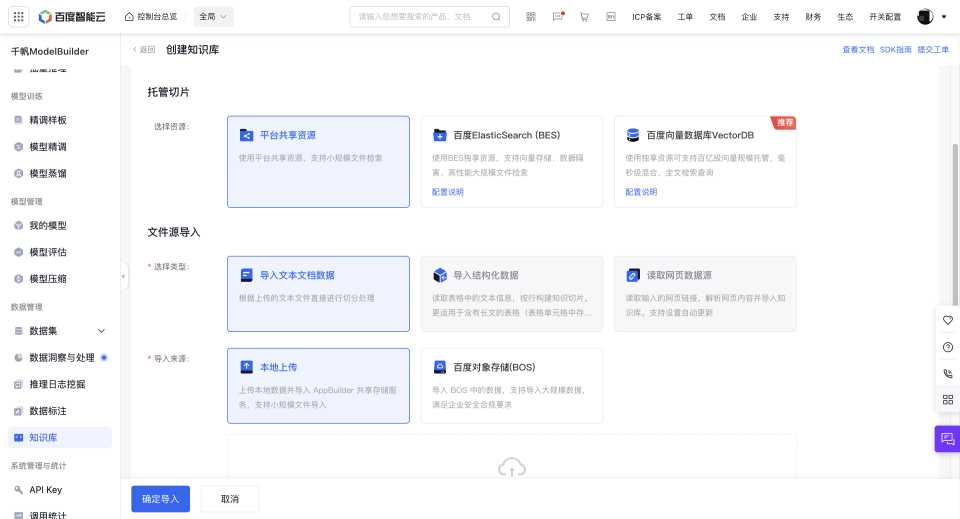
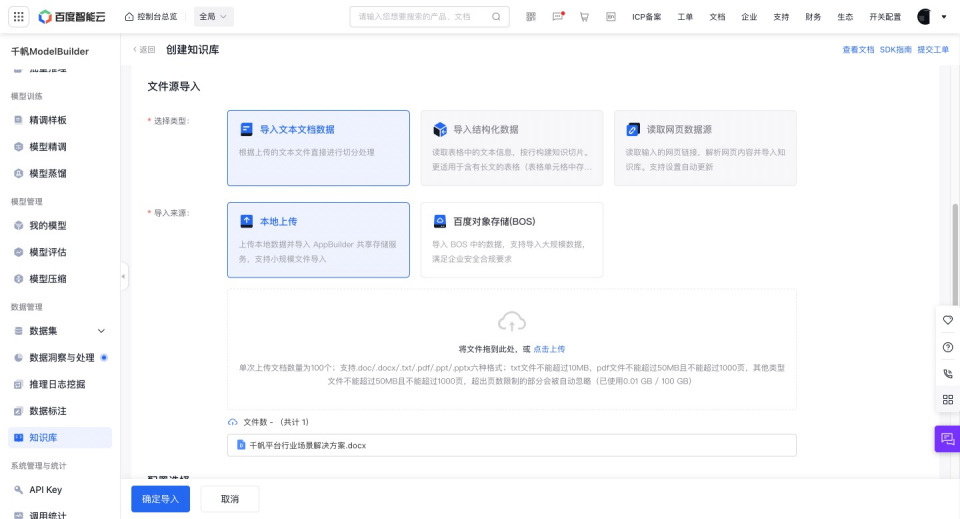
3. 文件源导入
【导入类型】支持导入文本文档数据,根据上传的文本文件直接进行切分处理,适合各类通用场景。
如需导入及配置结构化数据与网页数据源,请前往千帆AppBuilder应用开发平台,知识库文件数据将自动同步至本平台
【导入方式】文本文档数据支持本地上传和百度对象储存(BOS)
| 导入方式 | 说明 | 格式要求 |
|---|---|---|
| 本地上传 | 上传本地数据并导入平台共享存储服务,支持小规模文件导入 |
|
| 百度对象储存(BOS) | 导入 BOS 中的数据,支持导入大规模数据,满足企业安全合规要求 |
|
4. 配置选择
【选择配置】上传文本文档数据后,可在配置选择中根据需求配置解析策略、切片策略和知识增强以提升知识问答效果。
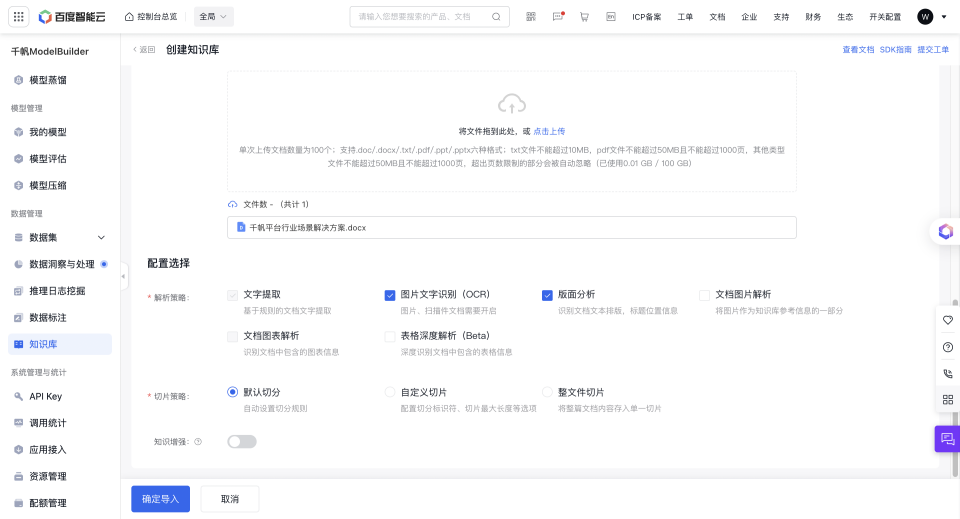
(1)解析策略: 用于配置文档解析策略。默认开启文字提取,可以选图片文字识别(OCR)、版面分析、文档图片解析、文档图表解析和表格深度解析(Beta)
| 解析策略 | 说明 | 适用场景 | 依赖 |
|---|---|---|---|
| 文字提取 | 基于规则的文档文字提取 | 默认开启 | |
| 图片文字识别(OCR) | 当文档中包含图像等内容时,可以开启该功能,打开后可识别图像、扫描件信息。关闭时,提高文档解析速度。 | 适用于图片、扫描件文档 | |
| 版面分析 | 当文档存在层级结构时,可以开启该功能,打开后会增强对文档层级结构的理解能力,检测文档中的标题、段落、页眉、页脚、图片、表格等元素。同时,启用该功能时,可以开启【切片策略-自定义切片-关联标题及子标题】功能。关闭时,提高文档解析速度。 | 文档存在层级结构时建议开启 | |
| 文档图片解析 | 当文档中包含图片,且希望能够在问答中准确召回图片时,可以开启该功能。启用该功能时,将在文档上传阶段对文档中图片进行解析,并将相关图片关联在文字切片下方。关闭时,提高文档解析速度。 | 适用于需要对文档中图片进行召回的场景。 | 文档图片解析的开启依赖图片文字识别(OCR)、版面分析开启,若图片文字识别(OCR)、版面分析策略关闭,则文档图片解析不可选中。 |
| 文档图表解析 | 当文档中包含图表,且希望能够在问答中检索召回图表中包含信息时,可以开启该功能。启用该功能时,将在文档上传阶段对文档中图表进行解析,并将相关图表关联在文字切片下方。关闭时,提高文档解析速度。 | 适用于需要对文档中的图表信息进行检索召回的场景。 | 图表解析的开启依赖文档图片解析开启。若文档图片关闭,则图片解析不可选中。 |
| 表格深度解析(Beta) | 当文档中包含跨行跨列,超长类等复杂表格,且希望准确识别图表结构,召回图表信息时,可以开启该功能。启用该功能时,将在文档上传阶段调用表格深度解析服务以优化解析效果。关闭时,提高文档解析速度。 | 适用于文档中存在跨行跨列,超长类复杂表格,且需要准确识别的场景。 | 表格深度解析的开启依赖版面分析开启。若版面分析关闭,则表格深度解析不可选中。 |
(2)切片策略:用于配置文档切分策略,支持默认切分、自定义切片、整文件切片
| 切片策略 | 说明 | 适用场景 |
|---|---|---|
| 默认切分 | 根据文档自动设置切分规则 | 适合具备简单结构的文本,如论文、新闻等 |
| 自定义切片 | 可以配置标识符、切片最大长度、切片重叠最大字数占比以及选择关联信息内容。(详细解释见下) | 文本具有特定的结构或需要特别关注某些信息,如药物说明书 |
| 整文件切片 | 将整份文档的解析内容放入同一个切片中,开启后,会增加文档的处理时长和资源消耗 | 适用于长上下文大模型对全文总结的场景,单一切片最高支持15万字 |
自定义切片:支持按页切分、按自定义正则表达式切分和按标识符切分
| 切片方式 | 说明 |
|---|---|
| 按页切分 | 按照文档自然分页切分文本 |
| 按自定义正则表达式切分 | 自定义正则表达式匹配分隔符,按照匹配到的分隔符切分文本,需要填写表达式内容和包含策略: 表达式:通过正则表达式,自定义可匹配的分隔符。例如: [。!?]:任意句号,叹号,问号(第[\d一二三四五六七八九十零壹贰叁肆伍陆柒捌玖拾]{1,}章):第x章包含策略:对正则匹配的分隔符,设置包含的位置。例如当匹配到"第x章"时,可选: 前序切片:将"第x章"拼接至前序切片末尾 后续切片:将"第x章"拼接至后续切片开头 匹配后丢弃:切分后,将"第x章"删除 注:当表达式涉及多段分隔符时,此选项功能可能不生效 |
| 按标识符切分 | 按照所选的标识符切分文本,支持选择的标识符有:中文句号、中文逗号、中文问号、英文句号、英文逗号、英文问号、省略号 |
通用配置项:包括切片最大长度、切片重叠最大字数占比、关联信息
| 配置项 | 说明 |
|---|---|
| 切片最大长度 | 设置每个切片内的字符数上限,确保切片的最大长度与模型所支持的上下文长度范围相匹配,以确保数据处理的准确性和效率。 长度越大,召回的上下文越丰富。 长度越小,召回的信息越精简。 当前切片最大长度默认为1200字,最高上限为15万字,但需确保填写的切片最大长度不超过模型上下文的数量限制。 |
| 切片重叠最大字数占比 | 设置当前切片与前后切片的"重叠部分字符数"相较于设置的"切片最大长度"的比例。如果重叠部分存在不完整的句子,则此切片舍去该句。占比越大,相邻切片重叠字符越多,占比越小,重叠字符越少。 例如,如果文本是"我爱学习我爱生活",假设我们按4个字符进行切片,重叠比例为3/4或75%,则第一个切片是"我爱学习",第二个切片是"爱学习我",第三个切片是"学习我爱",这些切片之间的重叠部分字符数是"爱学习"或"学习我"3个字符。通过这种方式,可以确保每个切片之间有指定的重叠字符数,从而保持文本的连贯性。同时,如果句子"我爱学习并享受这个过程"被切割成"我爱学习"和"并享受这个",由于"并享受这个"是不完整的,这个切片可能会被舍弃或与其他切片合并。 注:该功能在选择自定义正则表达式时不可用。 |
| 关联信息 | 关联文件名:开启后,将在段落切片中补充文件名信息,在检索文件名信息时,有利于提升切片召回效果。关闭时,可提高文件切分处理速度。 关联标题及子标题:开启后,将在段落切片中补充正文标题或子标题信息,在检索标题相关信息时,有利于提升切片召回效果。关闭时,可提高文件切分处理速度。 |
(3)知识增强: 在检索问答时,系统通过检索知识点召回对应的切片。开启知识增强,会调用大模型抽取更加丰富的知识点,增加切片的召回率。对于文本文档类知识切片,知识增强将对每个切片生成对应的知识点。知识点会对检索召回效果产生影响,本平台的检索召回效果与 AppBuilder 平台一致。如果您想查看知识切片对应的知识点,可 前往千帆AppBuilder应用开发平台 进行操作。
| 增强方式 | 说明 |
|---|---|
| 问题生成 | 默认开启。根据切片内容生成问题作为知识点,提升知识点和用户检索文本的相似度,进而提升知识召回成功率。 |
| 段落概要 | 根据切片内容生成段落概要作为知识点,提升知识召回成功率。开启后,增加文档的处理时长和资源消耗。 |
| 三元组知识抽取 | 对切片内容抽取三元组信息作为知识点,如:"百度发布新品"--- <百度,发布,新品>。开启后,提升知识召回成功率,同时会增加文档的处理时长和资源消耗。 |
注意事项:开启知识增强后,会增加文档的处理时长和资源消耗。知识增强文档字数上限为10万字;单个切片字数上限为8千字,超出部分无法使用知识增强。知识增强方式可选择问题生成、段落概要、三元组知识抽取三种方式。
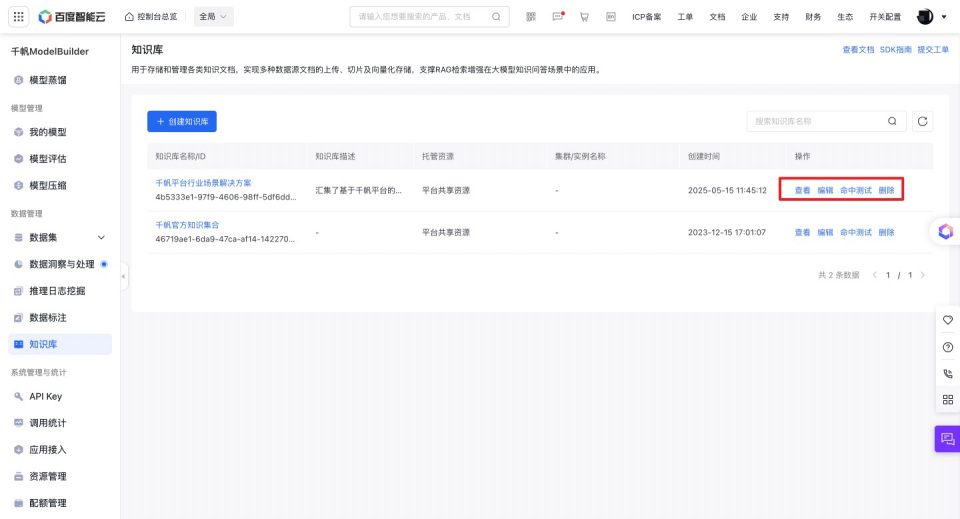
知识库管理
【数据管理-知识库】可通过查看、编辑、删除三项操作对知识库进行管理,支持根据知识库名称进行搜索,支持在知识库中导入新文件、删除现有文件。
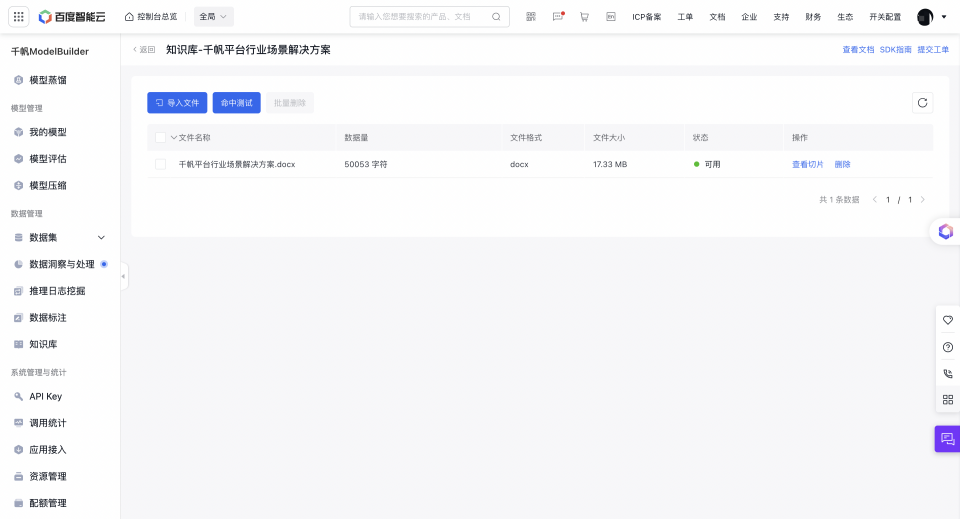
切片管理
【数据管理-知识库-查看-查看切片】可查看切片详情。切片详情页面分两列,分别展示文件基本信息、切片详情。
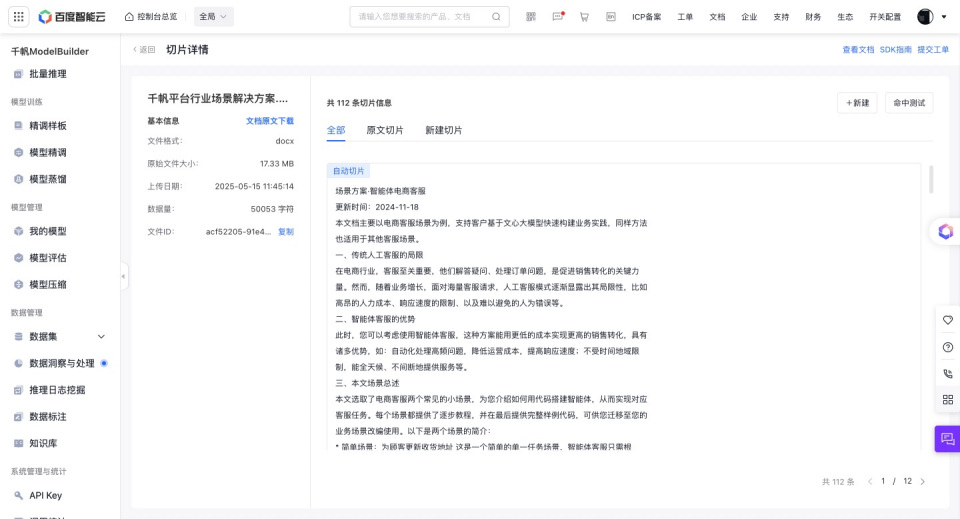
文件基本信息:包括文件名、文件格式、原始文件大小、上传日期、数据量、文件ID。点击"文档原文下载"可下载原始文档。
切片信息:鼠标悬于切片上,可查看切片ID、切片类型、字符数、编辑切片,以及决定是否启用该切片。如果选择不启用切片,该切片在命中测试和知识库检索时将不会被召回。
| 类型 | 说明 |
|---|---|
| 原文切片 | 用来存储没有编辑的切片,不允许编辑 |
| 新建切片 | 用来存储新建的切片,允许编辑 点击右上角【+新建】按钮,可以新建切片 |