

上传数据集
更新时间:2022-03-22
上传目标跟踪数据集
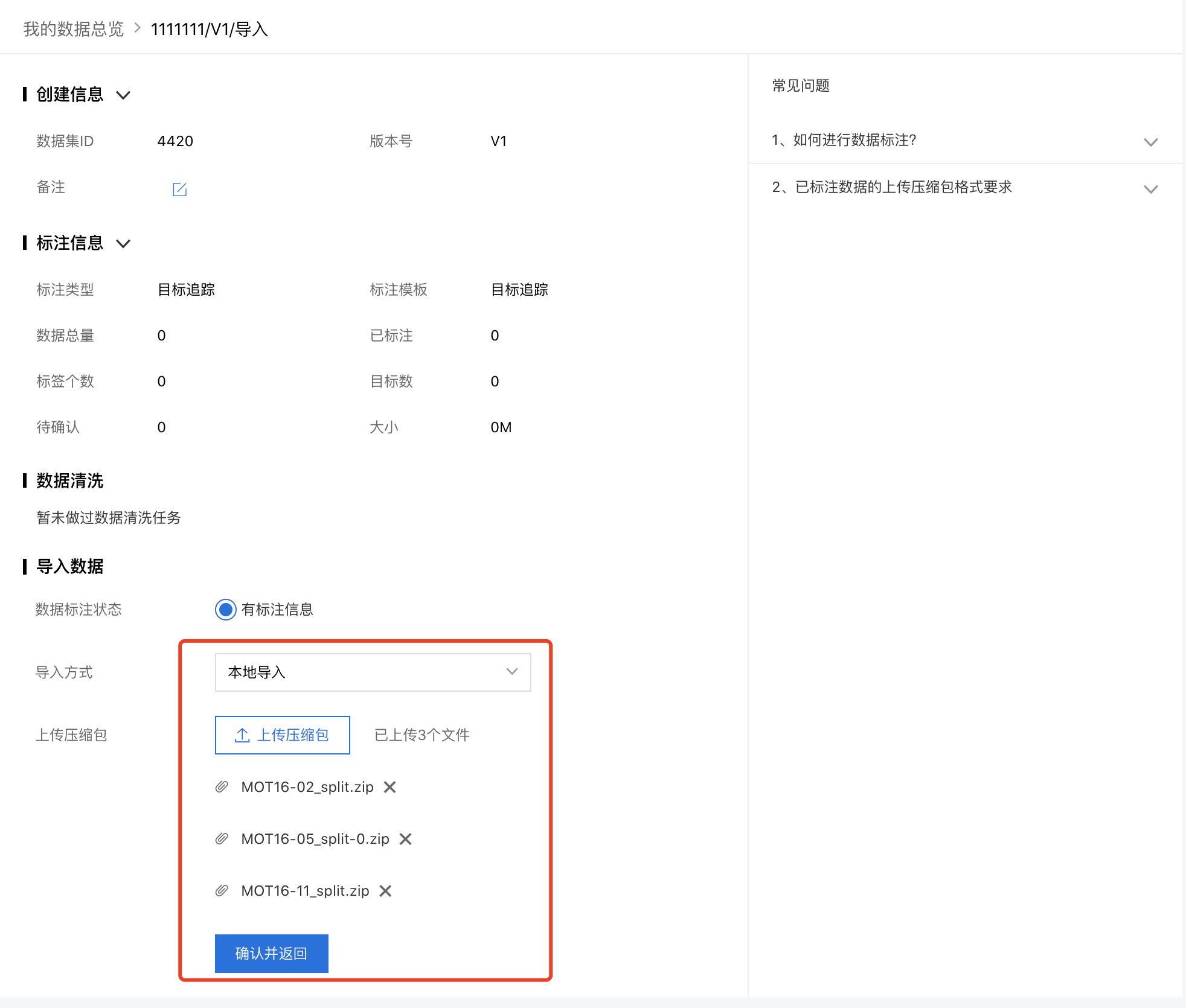
已标注数据上传
基于CVAT标注好的数据以MOT1.1的数据集形式导出,上传数据压缩包:
- 压缩包仅支持zip格式,大小限制5GB以内
- 压缩包内单个视频长度限制在10分钟内,至少应上传4个视频标注压缩包
- 从CVAT导出的标注数据压缩包可多次上传一起导入数据集组。也可通过本地解压再添加到同一个文件夹后压缩上传
如有任何问题,请提交工单联系我们
视频内容要求:
1、训练视频和实际场景要识别的视频拍摄环境一致,举例:如果实际要识别的视频是摄像头俯拍的,那训练视频就不能用网上下载的目标正面视频
2、每个视频需要覆盖实际场景里面的可能性,如拍照角度、光线明暗的变化,训练集覆盖的场景越多,模型的泛化能力越强
如果需要寻求第三方数据采集团队协助数据采集,请在百度云控制台内提交工单反馈
未标注数据上传
目前支持本地导入、BOS目录导入、分享链接导入、平台已有数据集导入,4种导入方式 本地导入的要求为
- 压缩包仅支持zip格式,压缩前源文件大小限制5GB以内
- 单视频文件类型要求为mp4/mov,单次上传限制10个文件
- 单个视频文件大小限制在3G内,视频码率不超过3Mbps,长度限制120min
- 分辨率大于1080P的视频会被压缩至1080P,编码格式不是h264格式的视频会被转为h264格式
- 您的账户下数据集数量限制为20G视频,如果需要提升数据额度,可在平台提交工单
导入完成后可在平台完成在线数据标注。如有任何问题,请提交工单联系我们
视频内容要求:
1、训练视频和实际场景要识别的视频拍摄环境一致,举例:如果实际要识别的视频是摄像头俯拍的,那训练视频就不能用网上下载的目标正面视频
2、每个视频需要覆盖实际场景里面的可能性,如拍照角度、光线明暗的变化,训练集覆盖的场景越多,模型的泛化能力越强