表格数据预测介绍
更新时间:2020-11-30
简介
Hi,您好,欢迎使用百度EasyDL定制化训练和服务平台。
定制表格数据预测模型,旨在帮助用户通过机器学习技术从表格化数据中发现潜在规律,从而创建机器学习模型,并基于机器学习模型处理新的数据,为业务应用生成预测结果。本文介绍表格数据预测模型,根据预测数据的不同,可以分为如下几种类型:
- 回归:目标列是连续的实数范围,或者属于某一段连续的实数区间。如在销量预测场景中,销量值可能是某个取值范围内的任意值,解决该问题的模型属于回归模型。
- 二分类:目标列是离散值,且只有两种可能的取值。如在精准营销场景中预测一个用户是否为潜在购买用户,其目标列仅存在“True”和“False”两种取值,解决该问题的模型属于二分类模型。
- 多分类:目标列是离散值,并具有有限的可能取值。如在用户分类场景中,根据用户的历史消费数据,将用户划分到不同消费偏好的类别中,解决该问题的模型属于多分类模型。
以下是关于表格数据预测模型的技术文档。
应用场景
- 精准营销:从客户消费记录中挖掘客户群的共有特征,分析出客户的购物偏好,从而实现广告的精准投放
- 信用评分:金融公司分析客户的历史行为数据,建立用户信用模型,从而确定贷款额度等
- 价格预测:从历史数据中发现商品的变化规律以及影响价格的因素,从而为未来的商业行为提供支持
- 客户流失预测:根据客户历史数据获得数据挖掘模型,从而生成客户流失预测列表,为市场营销策略提供有价值的业务洞察力。
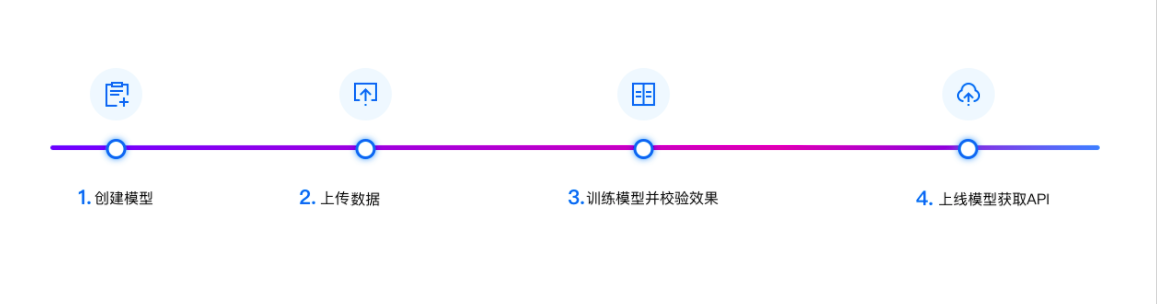
- 使用流程
训练模型的基本流程如下图所示,全程可视化简易操作。在数据已经准备好的情况下,最快几分钟即可获得定制模型。
下面将详细介绍每一步的操作方式和注意事项。如果文档没有解决您的问题,请在百度云控制台内提交工单反馈。