

AutoDL模式开发
为零AI开发基础的用户提供的建模方式,内置基于百度文心大模型的成熟预训练模型,可针对用户数据进行算法自动优化,助用户使用少量数据也能获得具备出色效果与性能的模型。
训练配置
AutoDL模式下支持对模型文件导出类型、模型SDK部署方式、训练使用算法类型等内容进行设置。
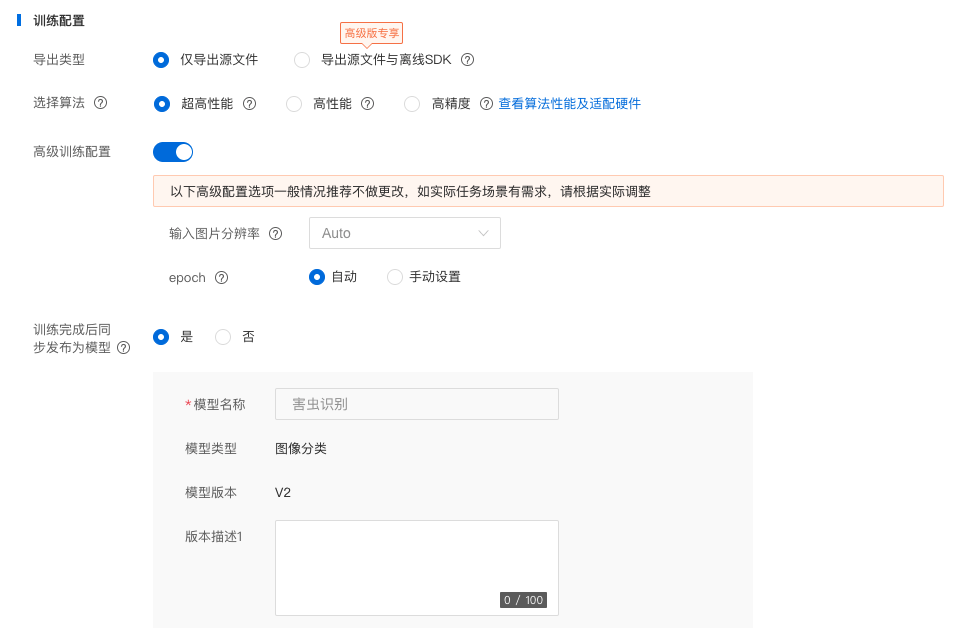
导出类型
- 导出模型源文件: 训练完成后支持将模型源文件导出,模型源文件可通过Paddle-Inference转化至实际应用场景中使用
-
导出模型源文件与离线SDK: 训练完成的模型可发布为在服务器、小型设备、专项适配硬件上直接部署的SDK,覆盖主流芯片与操作系统,可直接用于业务集成,省去繁琐转化过程
模型SDK适配设备类型详见 AotuDL模式算法适配硬件
部署方式
- 可发布为在服务器、小型设备、专项适配硬件上直接部署的SDK
- 模型SDK适配设备类型详见 AotuDL模式算法适配硬件
选择算法
- 高精度: 相同训练数据情况下,训练出的模型准确率更高,训练及预测耗时更长,模型体积更大
- 高性能: 相同训练数据情况下,较高精度算法,训练及预测耗时更短,模型准确率平均比高精度算法低3%~5%
-
超高性能: 相对高性能算法,模型体积更小,CPU环境预测速度提升近60%,GPU环境预测速度提升近10%
模型精度与训练数据量的大小、质量成正相关
训练速度与训练数据量的大小以及训练设备的算力情况相关
高级训练配置
高级训练配置开启状态下支持手动设置图像分辨率及迭代轮次(epoch)
- 图像分辨率: 如检测目标在图片中占比较小,可适当调高图片分辨率以得到更高的精度,如检测目标在图片中占比较大,可适当调低图片分辨率以得到更高的训练效率
-
迭代轮次(epoch): 训练集完整参与训练的次数,如模型精度较低,可适当调高迭轮次,使模型训练更完整
系统会根据本地训练资源以及所选算法类型自动采用最优组合,通常情况下推荐不做更改,如实际任务场景有需要,则可根据实际需求调整
训练完成后同步发布为模型
任务训练完成后可通过评估、校验验证任务效果,任务效果满足实际使用要求后发布为模型完成模型部署流程,如当前任务已经过多轮迭代且任务效果较有保证可勾选训练完成后同步发布为模型,并输入发布为的模型名称以及版本描述,训练成功后将会自动发布为模型
任务与模型一一对应,如当前任务已有版本发布为模型,则当前任务下的其他版本发布时仅支持发布在当前模型下
数据配置
添加训练数据
- 先选择数据集,再按分类选择数据集里的图片,可从多个数据集选择图片
- 训练时间与数据量大小有关,数据量越大,训练耗时越长
Tips:
- 图像分类任务类型,如只有1个分类需要识别,或者实际业务场景所要识别的图片内容不可控,可以在训练前勾选"增加识别结果为[其他]的默认分类"。勾选后,模型会将与训练集无关的图片识别为"其他"
- 如果同一个分类的数据分散在不同的数据集里,可以在训练时同时从这些数据集里选择分类,模型训练时会合并分类名称相同的图片
添加自定义验证集
AI模型在训练时,每训练一批数据会进行模型效果检验,以某一张验证图片作为验证数据,通过验证结果反馈去调节训练。可以简单地把AI模型训练理解为学生学习,训练集则为每天的上课内容,验证集即为每周的课后作业,质量更高的每周课后作业能够更好的指导学生学习并找寻自己的不足,从而提高成绩。同理AI模型训练的验证集也是这个功效。
注:学生的课后作业应该与上课内容对应,这样才能巩固知识。因此,验证集的标签也应与训练集完全一致。
添加自定义测试集
如果学生的期末考试是平时的练习题,那么学生可能通过记忆去解题,而不是通过学习的方法去做题,所以期末考试的试题应与平时作业不能一样,才能检验学生的学习成果。那么同理,AI模型的效果测试不能使用训练数据进行测试,应使用训练数据集外的数据测试,这样才能真实的反映模型效果。
注:期末考试的内容属于学期的内容,但不一定需要完全包括所学内容。同理,测试集的标签是训练集的全集或者子集即可。
配置数据增强策略
深度学习模型的成功很大程度上要归功于大量的标注数据集。通常来说,通过增加数据的数量和多样性往往能提升模型的效果。当在实践中无法收集到数目庞大的高质量数据时,可以通过配置数据增强策略,对数据本身进行一定程度的扰动从而产生"新"数据。模型会通过学习大量的"新"数据,提高泛化能力。
你可以在「默认配置」、「手动配置」2种方式中进行选择,完成数据增强策略的配置。
默认配置
如果你不需要特别配置数据增强策略,就可以选择默认配置。后台会根据你选择的算法,自动配置必要的数据增强策略。
手动配置
飞桨EasyDL提供了大量的数据增强算子供开发者手动配置。你可以通过下方的算子功能说明或训练页面的效果展示,来了解不同算子的功能:
| 算子名 | 功能 |
|---|---|
| ShearX | 剪切图像的水平边 |
| ShearY | 剪切图像的垂直边 |
| TranslateX | 按指定距离(像素点个数)水平移动图像 |
| TranslateY | 按指定距离(像素点个数)垂直移动图像 |
| Rotate | 按指定角度旋转图像 |
| AutoContrast | 自动优化图像对比度 |
| Contrast | 调整图像对比度 |
| Invert | 将图像转换为反色图像 |
| Equalize | 将图像转换为灰色值均匀分布的图像 |
| Solarize | 为图像中指定阈值之上的所有像素值取反 |
| Posterize | 减少每个颜色通道的bits至指定位数 |
| Color | 调整图像颜色平衡 |
| Brightness | 调整图像亮度 |
| Sharpness | 调整图像清晰度 |
| Cutout | 通过随机遮挡增加模型鲁棒性,可设定遮挡区域的长宽比例 |

训练环境配置
飞桨EasyDL支持以Intel CPU,或可通过NVIDIA旗下不同型号显卡加速训练。
如果您的计算机有NVIDIA® GPU,且需要使用GPU环境进行训练,请确保满足以下条件:
- Windows 7/8/10/11: 需安装 CUDA 11.2 与 cuDNN v8.2.1
- Ubuntu 16.04/18.4/20.4: 需 CUDA 11.2 与 cuDNN v8.1.1
- CentOS 7: 需 CUDA 11.2 与 cuDNN v8.1.1
CUDA、cuDNN安装指南
您可参考NVIDIA官方文档了解CUDA和CUDNN的安装流程和配置方法,详见: