

模型效果评估
简介
在参考模型训练操作说明文档完成模型训练后,可参考此文档了解模型效果。
模型训练结果
模型的训练结果是如何得到的?
上传的实景图,只有标注过的图片会被训练,所有训练图片中,系统会随机抽取70%的标注数据作为训练数据,剩余的30%作为测试数据,训练数据训练出的模型去对测试数据进行检测,检测得到的结果跟人为标注的结果进行比对,得到页面显示的mAP,精确率和召回率。
提示:训练数据,即上传标注的实景图片越接近真实业务里需要预测的图片,模型训练结果越具有参考性。
模型版本详情
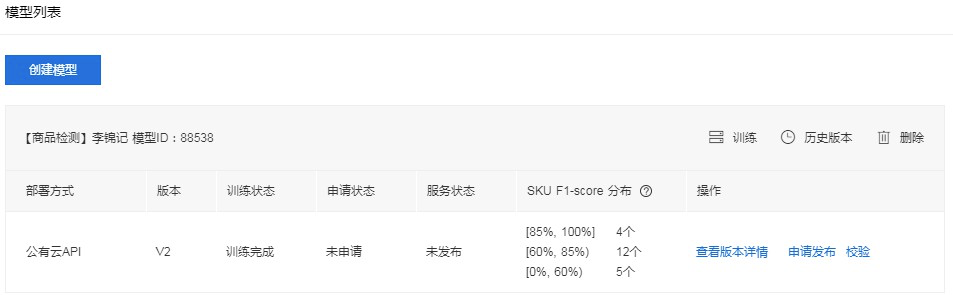
模型训练好后,可以在模型列表中看到SKU的F1-score分布情况,如果需要了解更为详细的模型效果表现,可以在模型列表中点击「查看版本详情」。
基础信息

模型版本的基础信息包含以下内容:
- 模型ID
- 训练版本
- 训练图片数
- 训练SKU数
- 训练完成时间
- 训练算法
SKU F1-score分布

直观展示模型中SKU F1-score的分布,F1-score是模型中一个SKU的精确率和召回率的调和平均数,可以作为判断模型中各SKU效果的指标,通常情况下:
- F1-score>85%时,可满足商品计数需求
- F1-score>60%时,可满足统计商品分销需求
模型整体效果

页面上显示的分销准确率、mAP、召回率和精确率数值,是模型里所有SKU在建议阈值下的平均值,建议阈值可以在模型的「模型整体F1-score走势图」中查看。四项指标的含义分别为:
- 分销准确率
按图片粒度统计分销准确率,即单张评估图片中正确识别出所有SKU种类的平均概率。
分销准确率 = 一张图片内正确识别的SKU种类数/(人工标注出的SKU种类数 U 模型识别出的SKU种类数)
- mAP
mAP在[0,1]区间,越接近1模型效果越好,mAP不高也不说明模型里所有的SKU识别效果不好。
mAP(mean average precision)是物体检测(Object Detection)算法中衡量算法效果的指标。对于物体检测任务,每一类object都可以计算出其精确率(Precision)和召回率(Recall),在不同阈值下多次计算/试验,每个类都可以得到一条P-R曲线,曲线下的面积就是average precision(AP)的值。“mean”的意思是对每个类的AP再求平均,得到的就是mAP的值。
- 精确率
对于一个SKU而言,精确率越高,说明模型识别出是这个SKU的所有结果中,正确数量的占比越高。如果精确率为1,说明识别出的所有结果都是对的,但不说明该SKU全部都被识别出来了,可能会存在漏识别。
精确率 Precision = 模型正确预测为该SKU的数量/模型预测为该SKU的总数- 召回率
对于一个SKU而言,召回率越高,说明模型越完整地识别出这个SKU。如果召回率为1,说明这个SKU全部都被模型识别出来了,但不表示识别出是这个SKU的结果都是对的,可能会存在误识别。
召回率 Recall = 模型正确预测为该SKU的数量/SKU客观存在的总数模型整体F1-score走势图
F1-score是模型中一个SKU的精确率和召回率的调和平均数,在以相同权重考虑precision和recall的情况下,用来衡量一个模型的效果。
F1-score = 2*Precision*Recall/(Precision+Recall)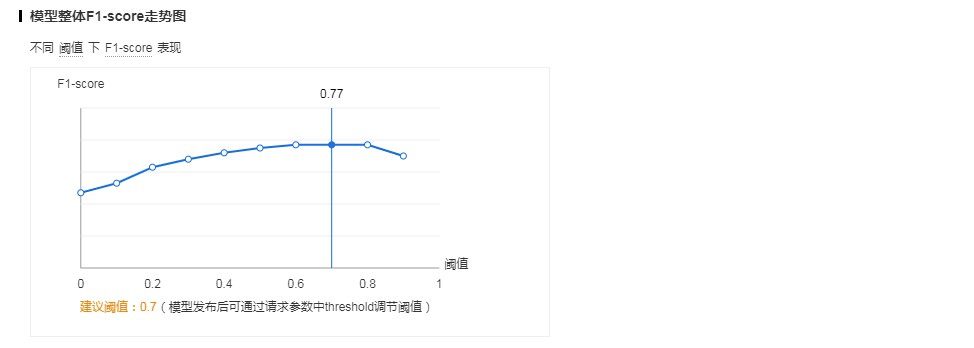
该曲线图展示了模型中各SKU在不同阈值下的F1-score平均值,根据该曲线可以得到阈值的最优值,即图中显示的「建议阈值」。模型列表和整体评估展示的三项模型效果指标数据,均是模型在「建议阈值」下的结果。另外,在模型发布后,调用服务API时可通过请求参数中threshold调节阈值,默认为建议阈值。
阈值(threshold),是正确结果的判定标准,例如阈值是0.6,置信度大于0.6的识别结果会被当作正确结果返回。
训练及评估数据明细
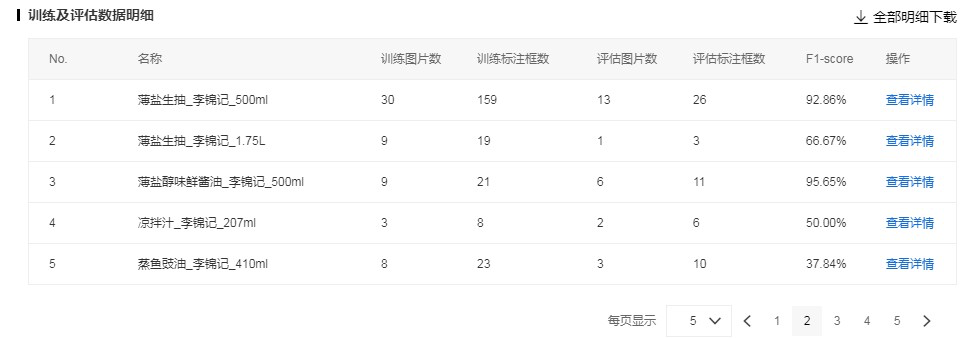
由于训练过程中,系统会随机抽取70%的标注数据作为训练数据,剩余的30%作为测试数据,所以模型训练存在一定的随机性。明细数据列表中展示了该模型版本训练时的图片数据和标注框的分布情况,帮助用户更具针对性的分析各个SKU的指标对应的数据量,以便针对性补充训练数据来优化模型。该表单支持下载,以便用作模型报告的制作。表单中的各列含义如下:
- No. :SKU在表单中的序号
- 名称:SKU的标签名称,名称品牌规格
- 训练图片数:实际用于训练模型的各个SKU的图片数量(训练模型时选择所有图集中含有图片总量的70%)
- 训练标注框数:实际用于训练模型的图片中,各个SKU的标注框数
- 评估图片数:用于评估个SKU训练效果的图片数量(训练模型时选择所有图集中含有图片总量的30%),即用来得到模型各项指标(mAP、Precision、Recall、F1-score)的评估集
- 评估标注框数:用于评估的图片中,各个SKU的标注框数
-
F1-score:每个SKU的F1-score,F1-score是模型中一个SKU的精确率和召回率的调和平均数,可以作为判断模型中各SKU效果的指标,通常情况下:
- F1-score>85%时,可满足商品计数需求
- F1-score>60%时,可满足统计商品分销需求
- 操作:查看详情,可查看所有参与训练和评估的图片