

7.电商网站UGC图片自动分类
项目说明
业务背景
运动潮牌鞋类越来越受年轻人欢迎,近几年运动鞋类销量也持续增高,也出现不少用户自主交易的电商平台。用户每天上传几万张鞋子照片,包括:鞋子外观、外盒或者鞋标,后台需要将鞋类照片进行分类处理,以便用户进行图像搜索时实现精准搜索。现阶段主要依赖人工进行分类后建立数据底库的形式来建设功能应用,其中耗费的人力成本过高,且识别效果不理想。某电商企业希望通过建立AI图像分类的能力来实现以图搜商品、商品自动分类等应用。
业务难点
AI模型的训练需要有图片对应标注的数据集,海量的鞋品图片需要进行标注,成本高,且人工标注效率低。模型效果调优周期长,需要反复添加数据进行模型迭代,效率低下。应用app有高并发、多地域的用户使用特性,如低成本地部署AI模型成为难点问题。
解决思路
通过EasyDL图像分类任务,无需了解AI算法知识,简单上手使用,提交少量图片进行训练,很快即可获得能够识别鞋类照片的AI模型。标注少量数据后可使用智能标注功能,完成大量原始数据的标注,来进行模型训练与迭代。模型可生成在线 API服务,多地域、高并发调用;并通过该模型在内部平台建立了图片自动分类的接口,当有用户上传图片时,将自动对其分类。每日3W+的新增照片分类,补充了产品后台数据处理能力,替代原有 10+人工审核团队,提升审核效率。
数据准备
数据采集
客户最终的应用场景是在电商app中提供用户拍摄的鞋类照片识别功能,因此数据采集的照片要尽量贴合用户拍摄的场景,具备真实性,包含多种光照条件,这样才能保证训练模型的效果。切勿使用网络图片进行训练。 应用场景需要对每种型号的鞋品进行识别,并定位到最终的鞋品型号(例如 NIKE TMQPDG1),型号具有唯一性,可在AI模型应用时直接通过AI识别定位到鞋品SKU。因此需要对每种型号的鞋品进行多角度拍摄采集数据。而在设计标签时,也需要注意的是,每种型号鞋品的不同视角图差异太大,因此我们需要将鞋底、鞋侧面等图片分别定义为对应的标签。

创建并导入数据
第一步,在EasyDL官网点击立即使用,选择图像分类任务,进入图像分类操作台。
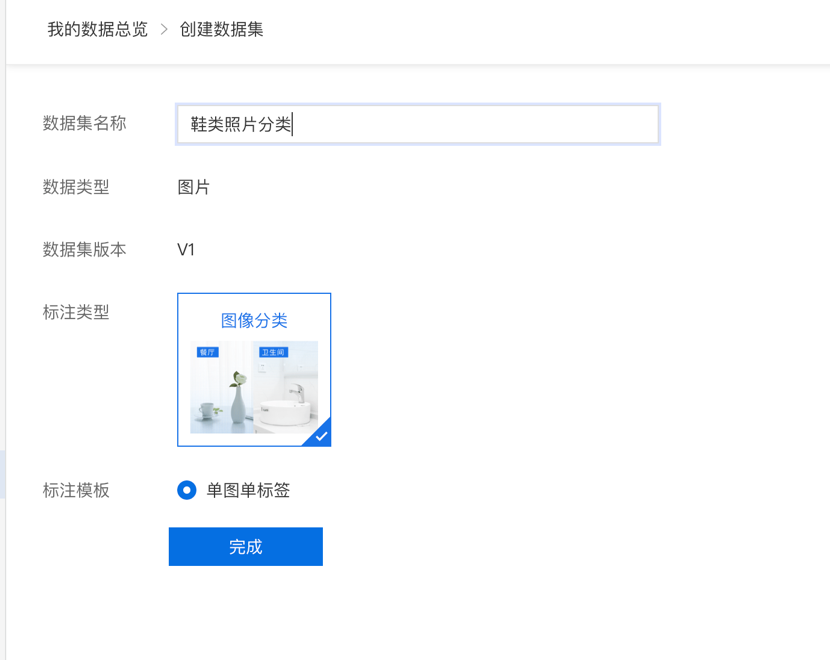
第二步,在数据总览页中点击创建数据集,创建一个“鞋类照片分类”数据集,点击完成。
第三步,在数据总览页中找到刚才创建的数据集,点击操作栏的“导入”,EasyDL提供多种数据导入方式,可在页面中参考各个方式对应的要求来导入数据。 提示:为方便开展模型训练,示例数据已经在本地通过文件夹分隔进行好分类。请选择“有标注信息”-“本地导入”-“上传压缩包”-“以文件夹命名分类”,上传压缩包【shooes.zip】,并确认。
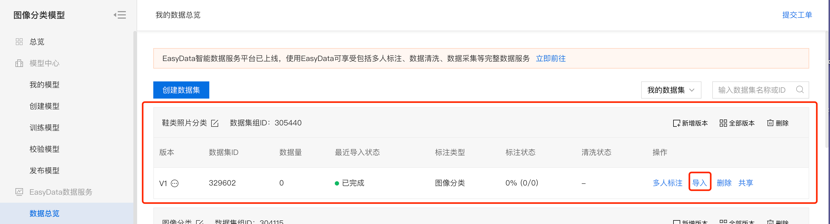
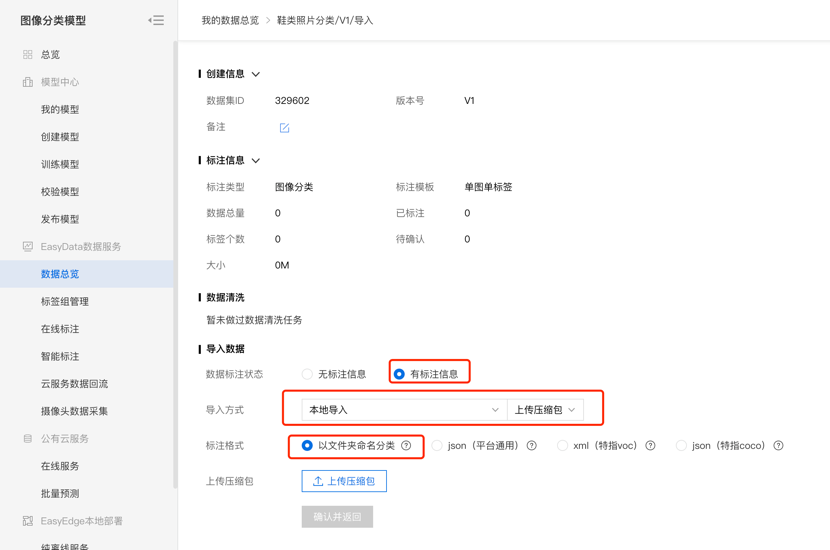
第四步,在数据总览中可以看到数据已经导入,点击右侧的查看与标注就可以去标注上传的原始图片数据。如果上传的是EasyDL提供的示例数据,则无需标注。

模型训练
第一步,在我的模型页创建模型,填写真实信息,方便EasyDL团队后续提供更好的服务。
第二步,在刚才创建好的模型操作栏点击训练,准备开始配置训练任务。

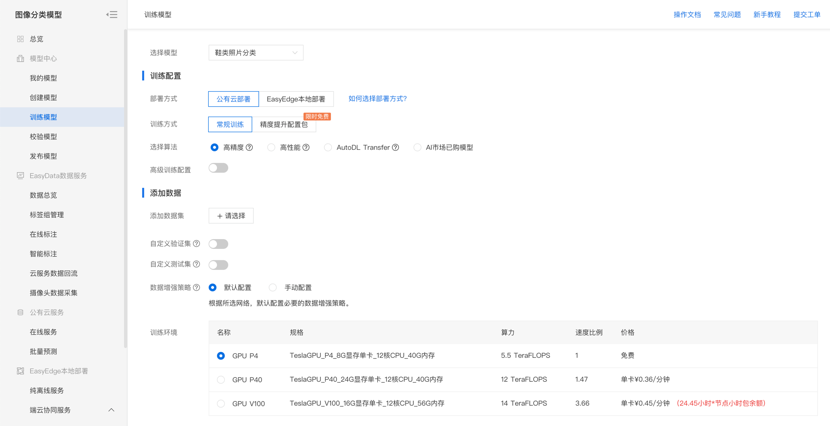
第三步,配置训练任务。训练配置有很多功能,可根据业务的需求考虑后选择。部署方式分为公有云部署和本地部署,因为鞋类照片分类的能力是需要集成应用在手机app中,有多地域、高并发的应用场景诉求。同时具备稳定连接网络的条件,推荐使用公有云在线部署的方式,简单几行代码即可调用。如果业务需要在离线的网络环境下运行,可选择本地部署。在选择算法时可根据应用场景是更加看重识别精度还是识别结果返回的速度,来决定是选择高精度还是高性能算法。在鞋类照片分类的应用场景中,更加看重精度,因此这里我们选择高精度模型。配置完训练策略后即可添加刚才导入的数据集作为训练数据,即可点击开始训练啦!
模型部署
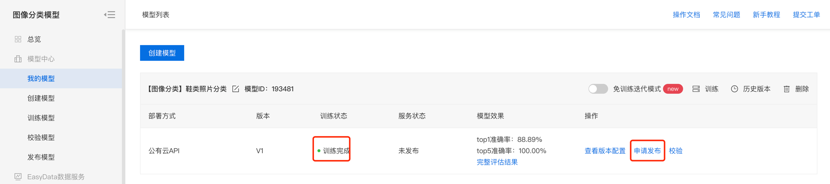
第一步,模型发布。模型训练完成后,点击右侧操作栏的申请发布,将模型发布为公有云服务,发布完成后可在公有云服务页中查看。
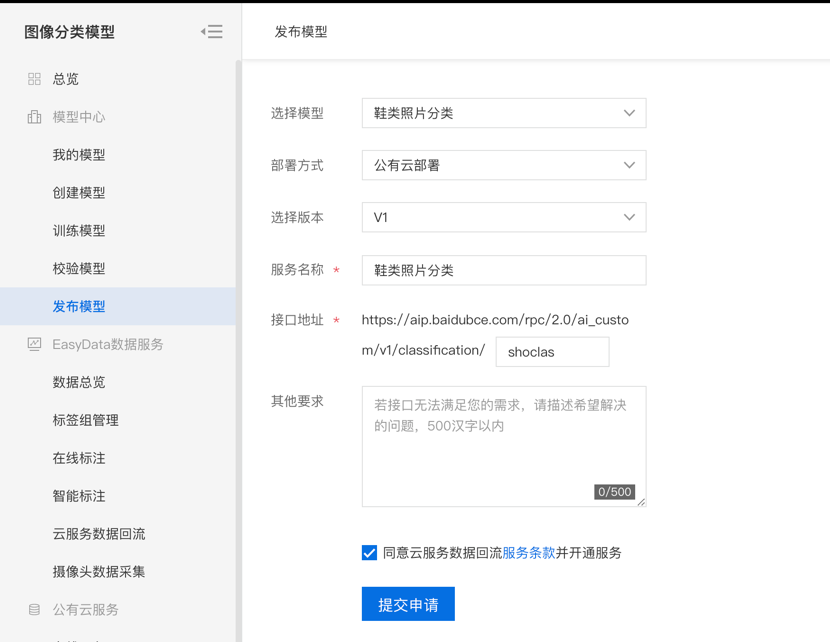

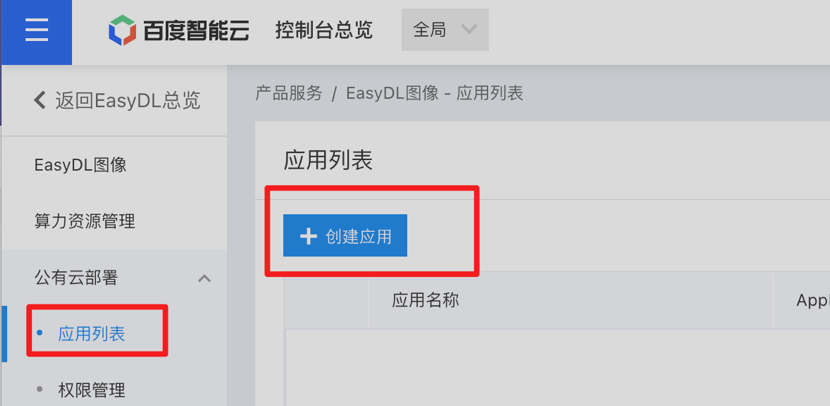
第二步,权限配置。首先在百度智能云控制台-EasyDL-公有云部署-应用列表页创建应用,创建完成后将会获得AK/SK,通过AK/SK来获得接口运行的“Access Token”,在自己的pc终端中命令行输入 curl -i -k 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【百度云应用的AK】&client_secret=【百度云应用的SK】' 即可获取。

第三步,安装依赖并运行示例代码。完成权限配置后即可参照API调用文档的示例代码进行调用。(使用文档链接:https://ai.baidu.com/ai-doc/EASYDL/Sk38n3baq)

效果优化
在模型训练完成后,可点击完整评估结果来查看模型评估报告。可查看模型的总体评估指标和详细的评估信息,例如错误示例、混淆矩阵等,可根据评估报告反馈的明显问题来完善数据集或者训练配置进行模型优化。如详细评估中的错误示例是标注错误,则可直接点击大图进行修改标注;如某个类别的误识别较多,可考虑针对该类别补充更多数据来优化效果。
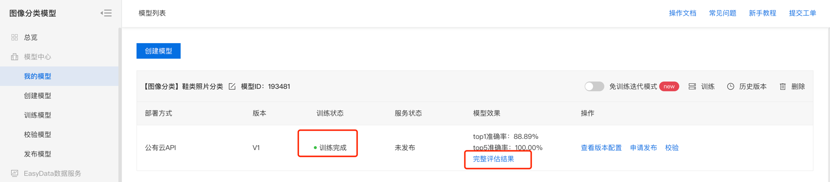
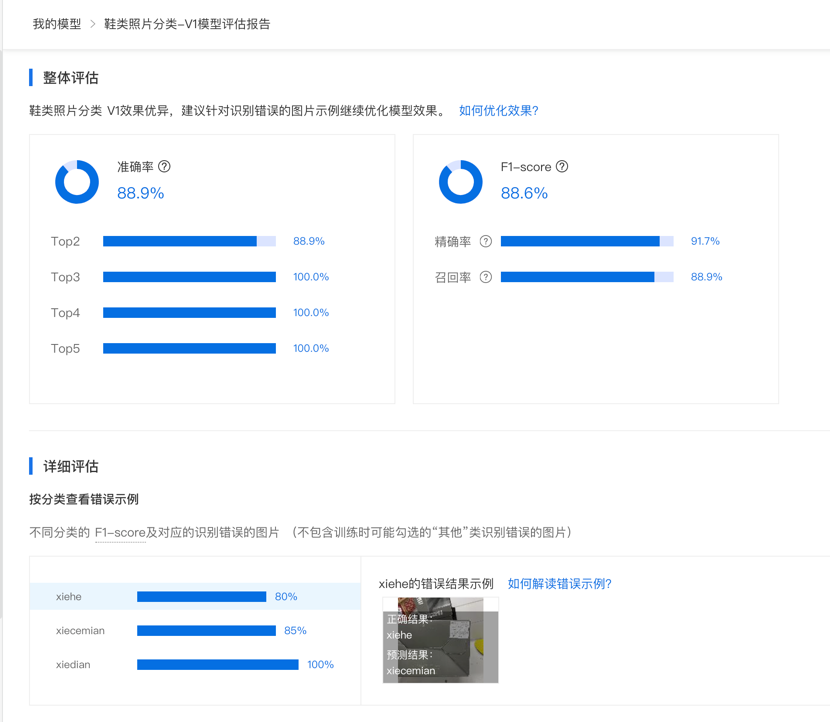
还可在详细评估中查看不同标签的识别结果,针对于效果表现不好的标签类别进行专项优化:删除干扰数据、补充典型数据、配置数据增强策略等措施。
对于像电商零售这样的场景,经常会有增加需要识别的商品SKU的情况,这种场景推荐使用EasyDL的免训练迭代模式。免训练迭代模式下,新增标签数据时,无需重新发起训练,可直接快速添加数据来完成模型迭代,可将模型服务快速投产。具体使用方式如下:首先,训练完成模型。其次,打开免训练迭代模式开关,待免训练迭代模式的模型生成完毕后即可使用。最后,需要添加标签数据时可打开免训练模式数据底库,将新数据添加至底库中,快速完成模型迭代与投产。
常见问题
问题1:我应该采集多少数据?
如果是为了体验模型训练和使用的流程,每个类别准备20张即可开始训练。如果需要保证模型效果,模型将投入业务中使用,建议每个类别准备300-500张图片,且覆盖光照和角度都比较全面,从而保证模型的泛化性。
问题2:我有些标签数据量很少,会不会影响模型效果?如果影响,我应该怎么办? 某类标签的数据量相比其他标签的量较少,会影响模型对此类标签的识别准确率。在无法采集到更多原始数据的情况下可以在EasyDL上配置多个策略来优化效果。第一,可在训练配置页面-高级训练配置中打开「数据不平衡优化」开关,优化某类标签数据量少带来的效果问题。第二,可打开数据增强开关,并自己选择数据增强算子来生成更多训练数据,选择算子时需要结合自己的应用场景来选择。例如从肉眼上判断,光照不太影响识别率,就可以选择配置「Brightness」算子来调节光照条件来增加数据。
问题3:模型训练免费吗?你们平台什么时候收费? 数据标注、模型训练都是免费的,公有云服务API调用和本地部署SDK都提供免费试用的额度