

模型优化器(optimizer)说明
更新时间:2022-01-25
简介
文心模型优化器(optimizer)模块可以通过在所使用模型(models)的 optimizer() 方法里自定义的方式实现。大部分模型在未指定优化器时,默认采用Adam。
在所使用模型(models)的 optimizer() 方法里自定义模型优化
模型优化器模块optimizer()
文心模型优化器模块通过对建模核心接口类model(./textone/models/model.py)中的 optimizer() 方法重写来实现,其功能和参数定义如下所示。
def optimizer(self, loss, is_fleet=False):
"""
必须选项forward_return_dict否则会抛出异常。
设置优化器forward_return_dict如Adamforward_return_dictAdagradforward_return_dictSGD等。
:param loss:前向计算得到的损失值。
:param is_fleet:是否为分布式训练。
:return:OrderedDict: 该dict中存放的是需要在运行过程中fetch出来的tensorforward_return_dict大多数情况下为空forward_return_dict可以按需求添加内容。
"""
raise NotImplementedError以分类任务预置模型cnn_classification.py为例,其优化器模块的实现如下所示。
def optimizer(self, loss, is_fleet=False):
"""
:param loss:
:param is_fleet:
:return: OrderedDict: 该dict中放的是需要在运行过程中fetch出来的tensor
"""
opt_param = self.model_params.get('optimization', None)
if opt_param:
lr = opt_param.get('learning_rate', 2e-5)
else:
lr = 2e-5
optimizer = fluid.optimizer.Adam(learning_rate=lr)
if is_fleet:
optimizer = fleet.distributed_optimizer(optimizer)
optimizer.minimize(loss)
optimizer_output_dict = collections.OrderedDict()
return optimizer_output_dict在基于ernie的预置模型中,没有在 optimizer() 方法中指定模型的优化器,此时模型默认采用Adam,如下所示。
def optimizer(self, loss, is_fleet=False):
"""
:param loss:
:param is_fleet:
:return: OrderedDict: 该dict中放的是需要在运行过程中fetch出来的tensor
"""
opt_params = self.model_params.get("optimization")
optimizer_output_dict = OrderedDict()
optimizer_output_dict['use_ernie_opt'] = True
opt_args_dict = OrderedDict()
opt_args_dict["loss"] = loss
opt_args_dict["warmup_steps"] = opt_params["warmup_steps"]
opt_args_dict["num_train_steps"] = opt_params["max_train_steps"]
opt_args_dict["learning_rate"] = opt_params["learning_rate"]
opt_args_dict["weight_decay"] = opt_params["weight_decay"]
opt_args_dict["scheduler"] = opt_params["lr_scheduler"]
opt_args_dict["use_fp16"] = self.model_params["embedding"].get("use_fp16", False)
opt_args_dict["use_dynamic_loss_scaling"] = opt_params["use_dynamic_loss_scaling"]
opt_args_dict["init_loss_scaling"] = opt_params["init_loss_scaling"]
opt_args_dict["incr_every_n_steps"] = opt_params["incr_every_n_steps"]
opt_args_dict["decr_every_n_nan_or_inf"] = opt_params["decr_every_n_nan_or_inf"]
opt_args_dict["incr_ratio"] = opt_params["incr_ratio"]
opt_args_dict["decr_ratio"] = opt_params["decr_ratio"]
optimizer_output_dict["opt_args"] = opt_args_dict
return optimizer_output_dict其中opt_args_dict用来传ernie需要的一些额外参数。如果想自定义优化方式,可以直接在此处进行添加,如下图红框所示。
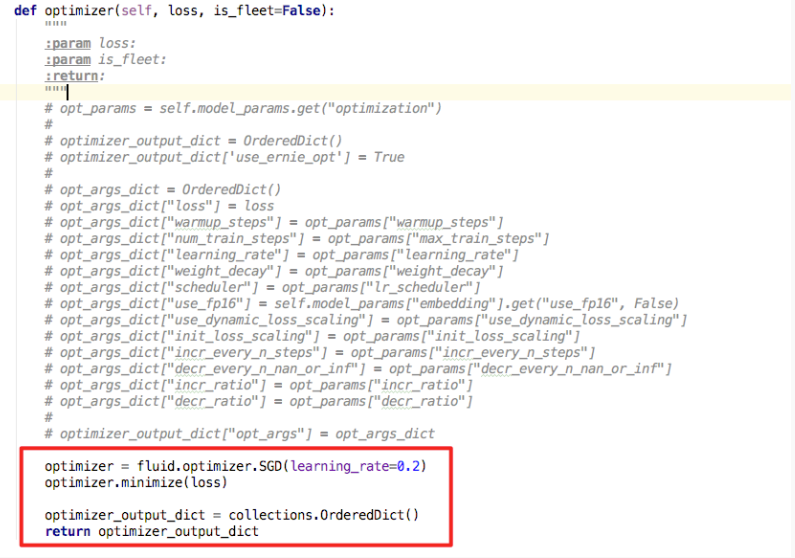
PaddlePaddle的常用optimizer接口
以下列举一些常用optimizer及其说明,如需了解更多信息请参考fluid.optimizer。
| 优化器名称 | 别名 | 介绍 | 代码示例 | 更多详情 |
|---|---|---|---|---|
| AdamOptimizer | Adam | Adam优化器出自Adam论文 的第二节,能够利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。 | adam_optimizer = fluid.optimizer.AdamOptimizer(learning_rate=0.01) adam_optimizer.minimize(loss) |
AdamOptimizer |
| AdamaxOptimizer | Adamax | Adamax优化器是参考 Adam论文 第7节Adamax优化相关内容所实现的。Adamax算法是基于无穷大范数的 Adam 算法的一个变种,使学习率更新的算法更加稳定和简单。 | adam = fluid.optimizer.AdamaxOptimizer(learning_rate=0.2) adam.minimize(loss) |
AdamaxOptimizer |
| AdagradOptimizer | Adagrad | Adaptive Gradient 优化器(自适应梯度优化器,简称Adagrad)可以针对不同参数样本数不平均的问题,自适应地为各个参数分配不同的学习率。相关论文:Adaptive Subgradient Methods for Online Learning and Stochastic Optimization。 | optimizer = fluid.optimizer.AdagradOptimizer(learning_rate=0.2) optimizer.minimize(loss) |
AdagradOptimizer |
| SGDOptimizer | SGD | 该接口实现随机梯度下降算法的优化器 | sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.001) sgd_optimizer.minimize(loss) |
SGDOptimizer |