

任务介绍与数据准备
更新时间:2022-12-17
任务介绍
开放域信息抽取利用单一模型支持多种类型的开放抽取任务,用户可以使用自然语言自定义抽取目标,无需训练即可抽取输入文本中的对应信息。
基于ERNIE IE2.0模型的技术方案是,将各种类型的信息抽取任务统一转化为自然语言的形式,并进行多任务联合训练,进而支持零样本信息抽取。模型的输入是待抽取文本(content)和自然语言描述的抽取目标(prompt),prompt通常建议的结构为“A的B”或“B”的形式,如下例子:
content:出租方:小明 地址:筒子街12号 电话:12345678900 承租方:小红 地址:新华路8号 电话:18345678901
prompt:地址
result:筒子街12号,新华路8号content:出租方:小明 地址:筒子街12号 电话:12345678900 承租方:小红 地址:新华路8号 电话:18345678901
prompt:小明的地址
result:筒子街12号常用的场景不限于命名实体、关系、事件论元、事件描述片段、评价、评价维度、观点词、情感倾向等。模型示意图如下所示:
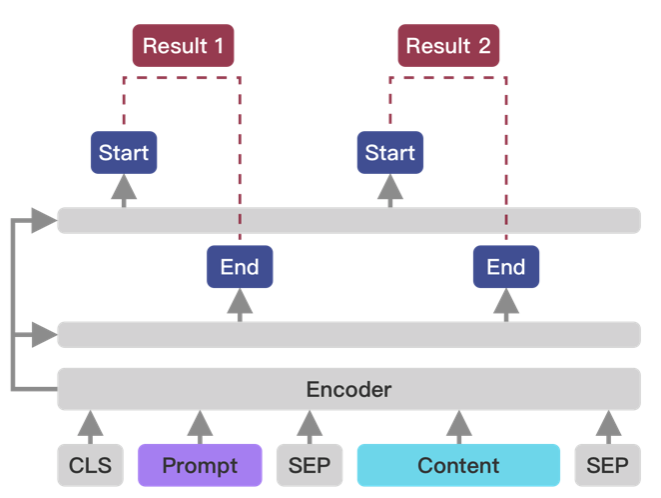
数据准备
- 这里我们提供了一份开源的实体抽取数据集MSRA示例。
cd wenxin_appzoo/tasks/openie/data/information_extraction/msra-ner/- 训练集、验证集已经转好模型需要的格式,分分别存放在msra-ner目录下的train.json、dev.json文件下。
训练集/测试集/验证集
训练集、测试集和验证集的数据格式相同,如下所示。
{"content": "1991年3月18日李鹏代表我国政府签署了世界儿童问题首脑会议通过的两个文件。\t人名", "annotations": {"MRC": [{"text": "李鹏", "segments": [{"text": "李鹏", "start_offset": 10, "end_offset": 12}], "label": "answer"}]}, "title": "NER\tOPEN\tMSRA"}
{"content": "我国对国际大家庭的承诺表现在:目前,全国80%的县及以上有产科的医疗保健机构均已被评为“爱婴医院”,共5890所,还有4071所有产科的乡卫生院也被评为“爱婴卫生院”,北京、上海等16省、市的164个城市社区和105个农村社区开展了妇幼卫生服务项目工作,并取得明显效果。\t地名", "annotations": {"MRC": [{"text": "上海", "segments": [{"text": "上海", "start_offset": 87, "end_offset": 89}], "label": "answer"}, {"text": "北京", "segments": [{"text": "北京", "start_offset": 84, "end_offset": 86}], "label": "answer"}]}, "title": "NER\tOPEN\tMSRA"}每条数据有三个字段,content字段是文本内容+promt(对于实体抽取任务,可以用实体的标签作为promt);annotations字段是标注信息的格式,分别是标签的文本和在原文中的起始/结束位置,label字段统一写为answer即可;title字段可以理解文本内容的简介/标题等或者表示文本内容属于哪一类的文本。
预测集
预测集无需标注信息(也可以有标注信息),其格式如下所示:
{"content": "我们是受到郑振铎先生、阿英先生著作的启示,从个人条件出发,瞄准现代出版史研究的空白,重点集藏解放区、国民党毁禁出版物。\t机构团体", "annotations": {"MRC": []}, "title": "NER\tOPEN\tMSRA"}
{"content": "藏书本来就是所有传统收藏门类中的第一大户,只是我们结束温饱的时间太短而已。\t地名", "annotations": {"MRC": []}, "title": "NER\tOPEN\tMSRA"}