

ERNIE-M
更新时间:2022-08-03
基本介绍
- 目前文心提供ERNIE-M base 多语言模型。
- ERNIE-M 是一个多语言模型,它通过大规模的单语语料和双语语料来捕捉语言之间的语义,可以同时建模96种语言,适用于各项多语言任务,跨语言任务。 详细支持语种目录如下:(淡蓝色列为iso_code,黄色列为语种)
- ERNIE-M base的模型下载脚本位于./wenxin_app/models_hub/目录下,为download_ernie_m_1.0_base.sh。执行下载脚本,会下载并生成对应的目录,其中包含模型参数文件、词表文件、网络配置文件、模型版本信息文件。
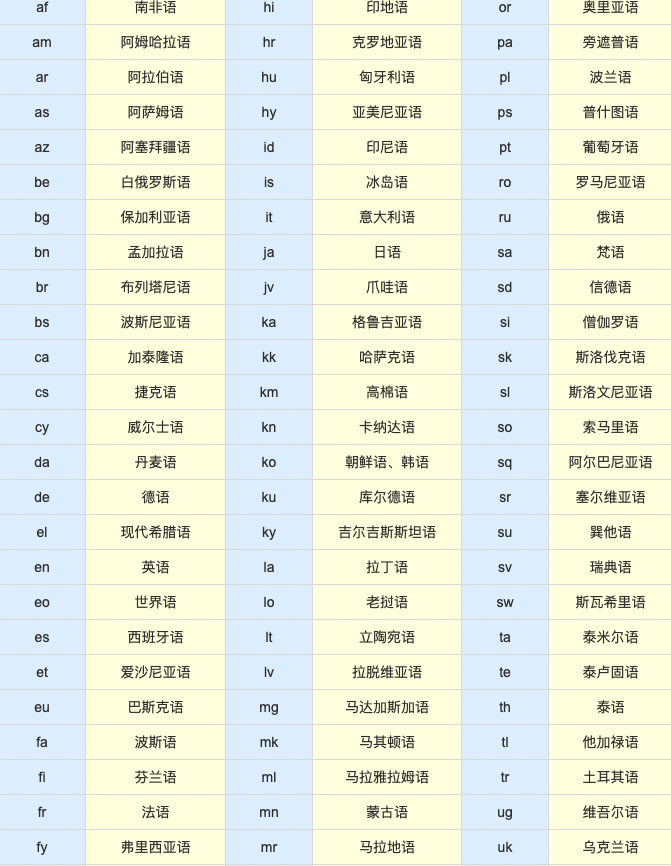
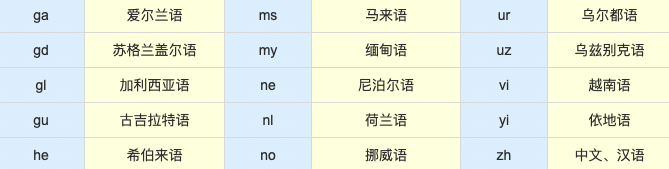
备注:有多重语言使用相同的iso code,如 zh 包括简体\繁体中文,ur 包括乌尔都语和乌尔都(罗马化)语言
原理介绍
- ERNIE-M 的词表大小为 25万,涵盖了96种语言的大多数常见词汇,训练语料包含了汉语、英语、法语、南非语、阿尔巴尼亚语、阿姆哈拉语、梵语、阿拉伯语、亚美尼亚语、阿萨姆语、阿塞拜疆语等96种语言。
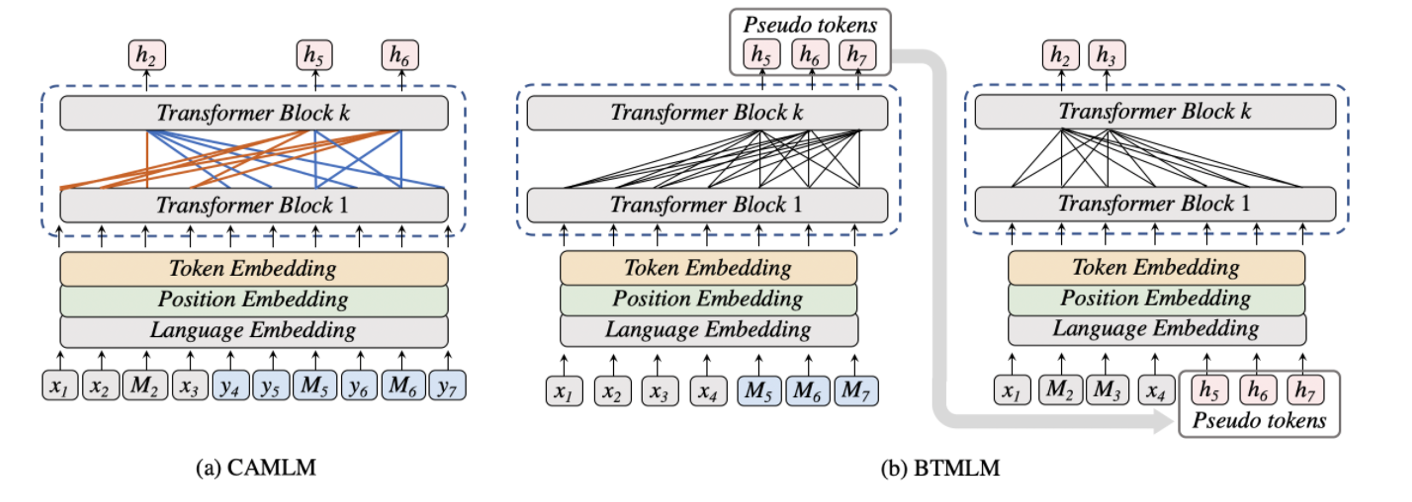
- ERNIE-M 的学习过程由两阶段组成。第一阶段从少量的双语语料中学习跨语言理解能力,使模型学到初步的语言对齐关系;第二阶段使用回译的思想,通过大量的单语语料学习,增强模型的跨语言理解能力。
在第一阶段的学习中,ERNIE-M提出了 Cross-attention Masked Language Modeling (CAMLM) 预训练算法。该算法在少量双语语料上捕捉语言间的对齐信息。在CAMLM中,将一对双语句子记为 <源句子,目标句子>。CAMLM需要在不利用源句子上下文的情况下,通过目标句子还原被掩盖的词语。例如:输入的句子对是 <明天会[MASK][mask]吗,Will it be sunny tomorrow>,模型需要只使用英文句子
来推断中文句子中掩盖住的词 <天晴>,使模型初步建模了语言间的对齐关系。 - 在此基础上,ERNIE-M又提出了 Back-translation Masked Language Modeling (BTMLM) 预训练算法。该方法基于回译机制从单语语料中学习语言间的对齐关系。首先,通过第一阶段学习到的CAMLM模型生成伪平行句子,然后让模型学习生成的伪平行句子。模型在对还原被掩盖的单词时,不仅可以依赖原始输入句子,也可以依赖生成的伪平行句子。例如,输入的单语句子是 <我真的很喜欢吃苹果>,模型首先会依据输入的句子 <我真的很喜欢吃苹果> 生成伪双语平行句子 <我真的很喜欢吃苹果,eat apple>。然后再对生成的伪平行句子<我真的很喜欢吃[MASK][mask],eat apple >学习。通过这种方式,ERNIE-M利用单语语料更好地建模语义对齐关系。
模型效果
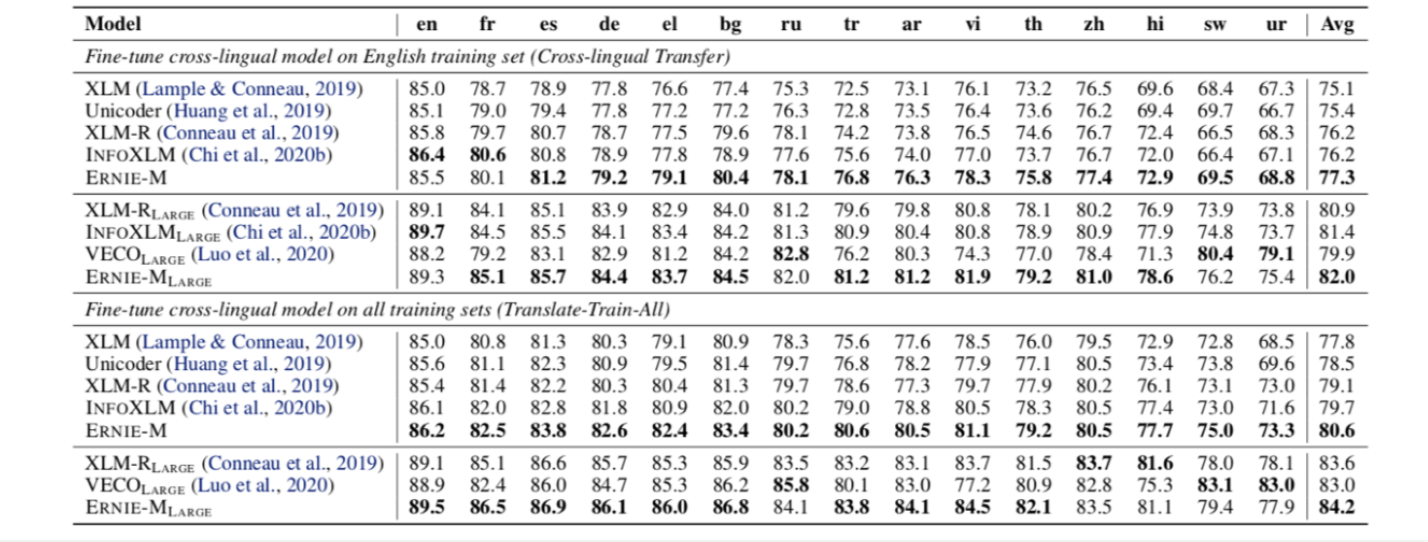
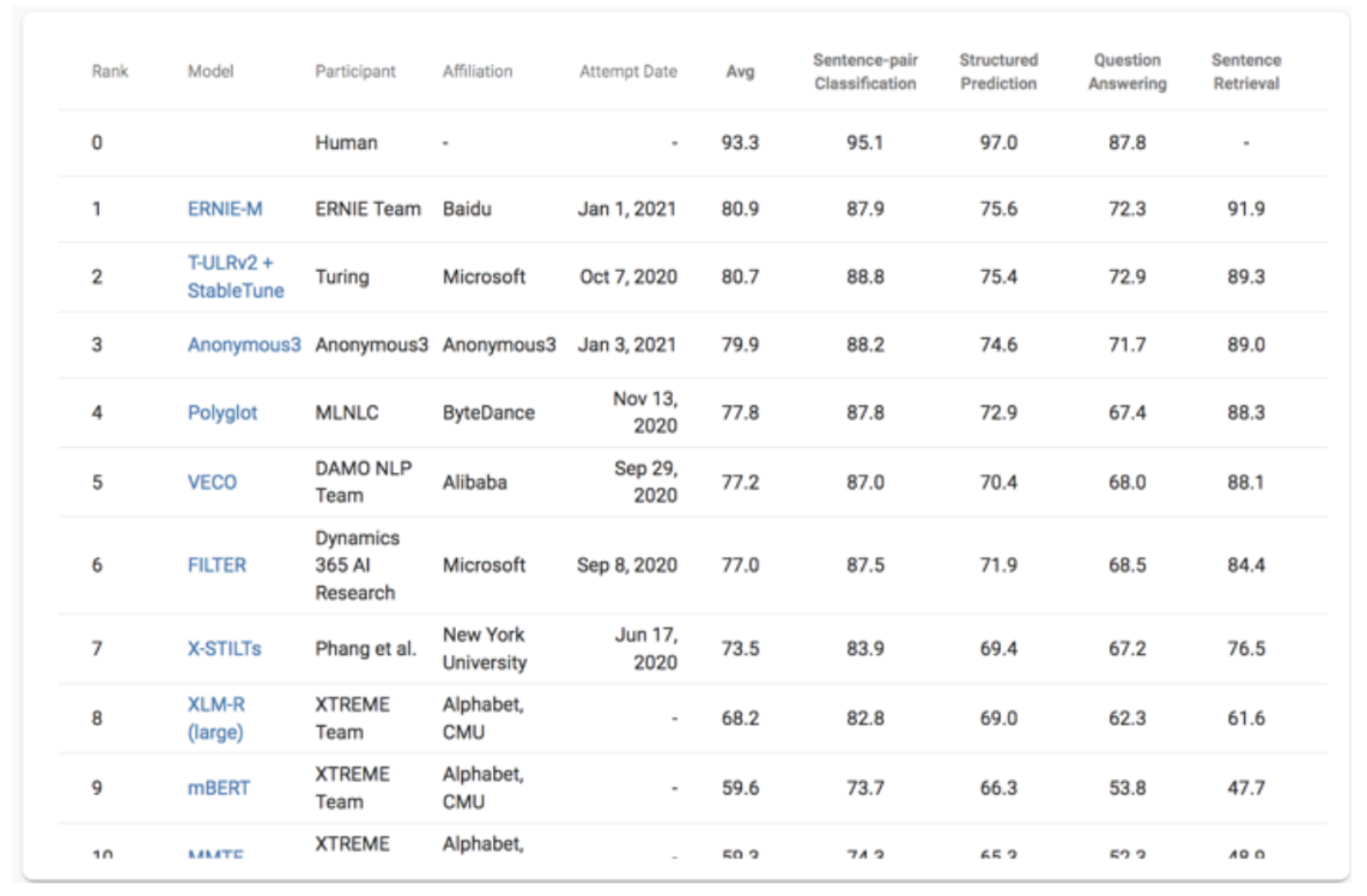
- ERNIE-M 在5项跨语言任务上刷新了SoTA,同时登顶多语言权威评测榜单XTREME
- 自然语言推断 (XNLI)
- 命名实体识别 (CoNLL)

- 语义相似度 (PAWS-X)
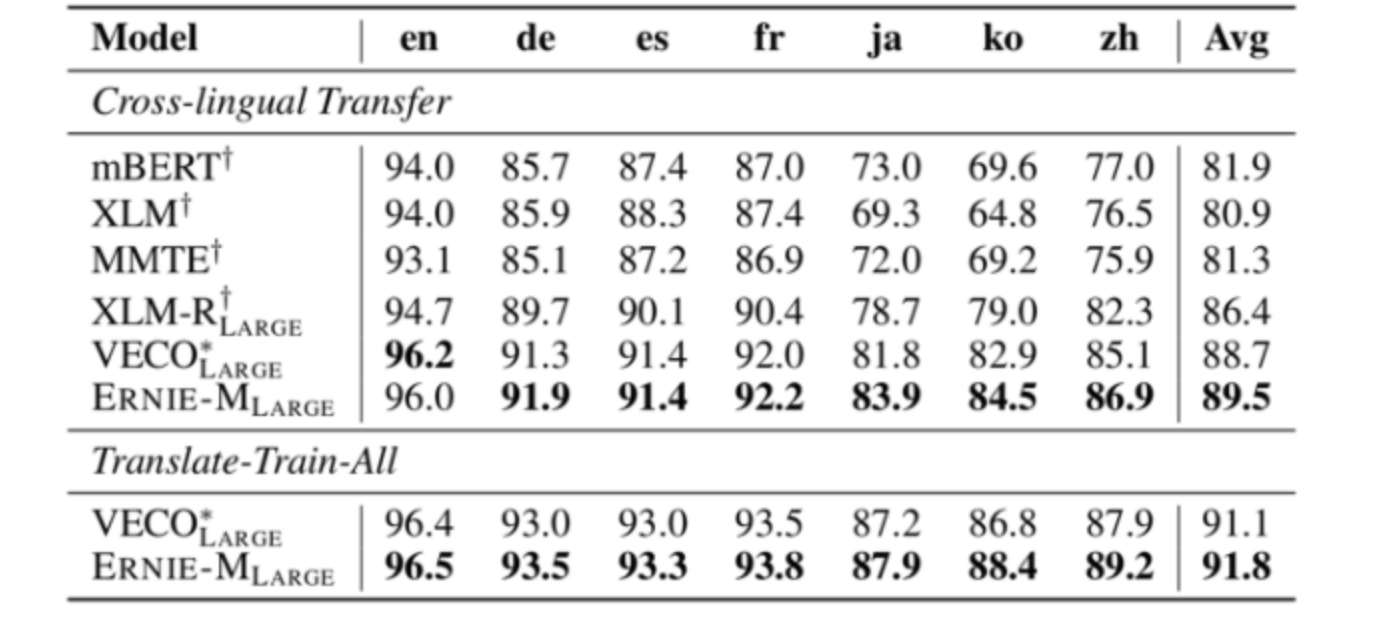
- 阅读理解 (MLQA)

- 跨语言检索 (Tatoeba)

- XTREME
使用方式
请移步使用ERNIE-M进行文本分类。