

ERNIE-Rank
基本介绍
ERNIE-Rank 是在ERNIE 2.0 的基础上,通过大数据构造无监督任务, 面向搜索领域的预训练模型,因为其预训练数据是搜索场景,所以理论上搜索的其他任务如recall也可以尝试:
在搜索领域中,用户通过主动向搜索引擎输入问题(Query),然后点击含有标题(Title) 的相关文章完成一次搜索行为。所有用户的搜索行为汇聚起来,可以得到同一个 Query 会对应多个 Title,反过来 同一个 Title 也会对应多个 Query。通过这样的关联关系,我们可以将 Query 和 Title 组织成一份二部图。
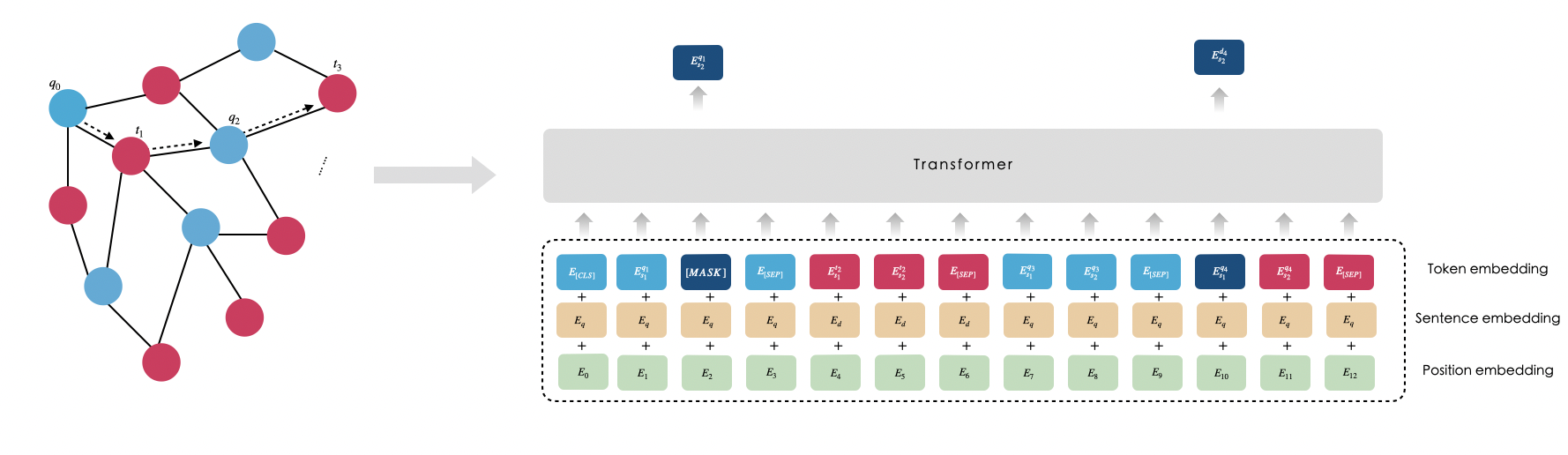
图1 利用搜索点击行为组织 Query 、Title 二部图,形成预训练样本 以图1 左侧 Query Title 二部图为例,蓝色的结点是用户提供的 Query,红色的结点是点击 Title。在这张图上,我们可以以 q0 为起点,随机选择与q0 相关的 title,例如 t1,再随机选择与t1相关的 q2,以此类推,就可以得到一个的序列 S = [q0 , t1 , …, qN-1 , tN] 。通过在这个序列上执行遮盖词预测和上下句预测,就可以完成预训练任务,如图1 右侧模型示意图。
该任务训练得到的模型与 ERNIE 2.0 模型结构完全一样,也共享同样的词表,所以可以直接通过改变模型配置路径加载,进行下游的微调任务。
效果验证
为了对比预训练模型的效果,我们将该模型在搜索的某领域数据上进行了 finetune,评估指标是正逆序,测试集包括点击行为构成的测试集和人工标注集合。
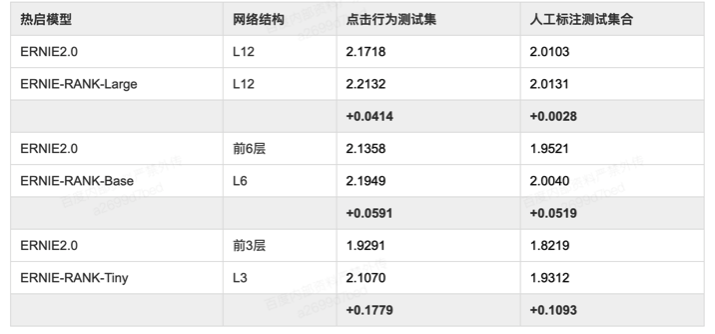
表1 ERNIE2.0 和 ERNIE-RANK 在搜索某领域数据上进行了 finetune,评估指标是正逆序
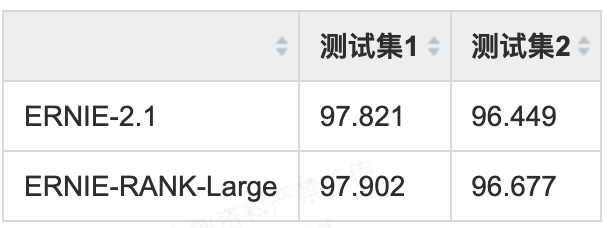
表2 ERNIE-RANK 在 搜索query意图分类表现。
模型配置
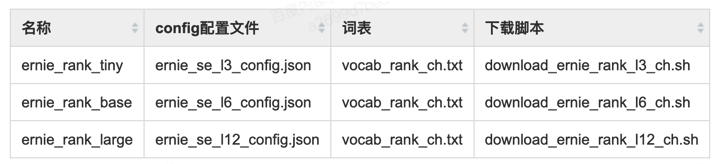
文心中的支持
见文本排序任务。