

优化模型的一般思路
更新时间:2022-12-17
前期工作
- 进一步分析你的业务背景和需求,分析基线模型的不足,进行更细致的技术选型。
- 采用工具版进行本地小数据调试,极大地提升迭代效率。
观察收敛曲线
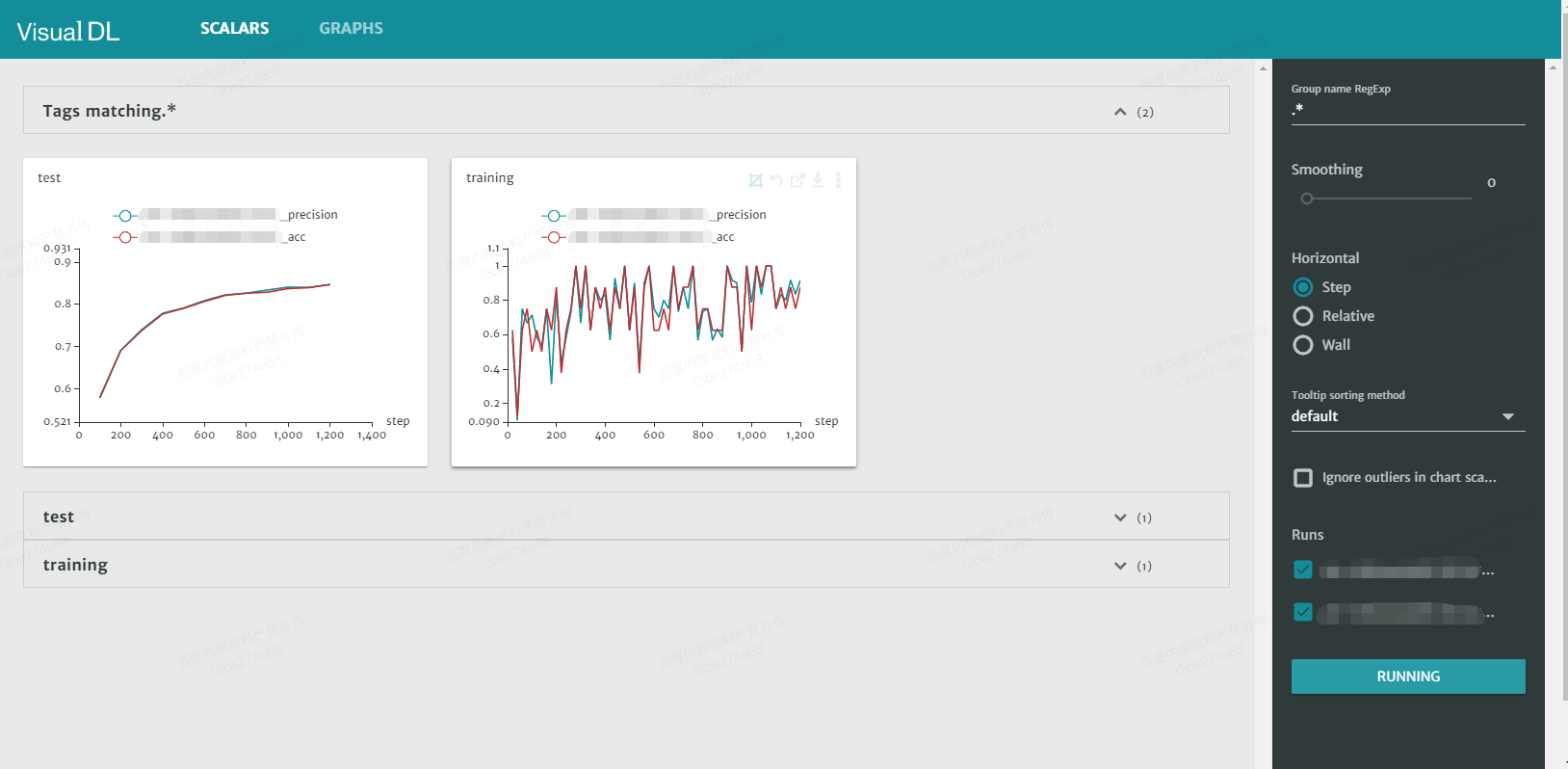
- 文心ERNIE平台版可自动绘制收敛曲线,如下图所示:
- 如果是工具版,建议自己将训练日志可视化为收敛曲线:比如grep指标数据,通过Excel绘制,如下图所示:
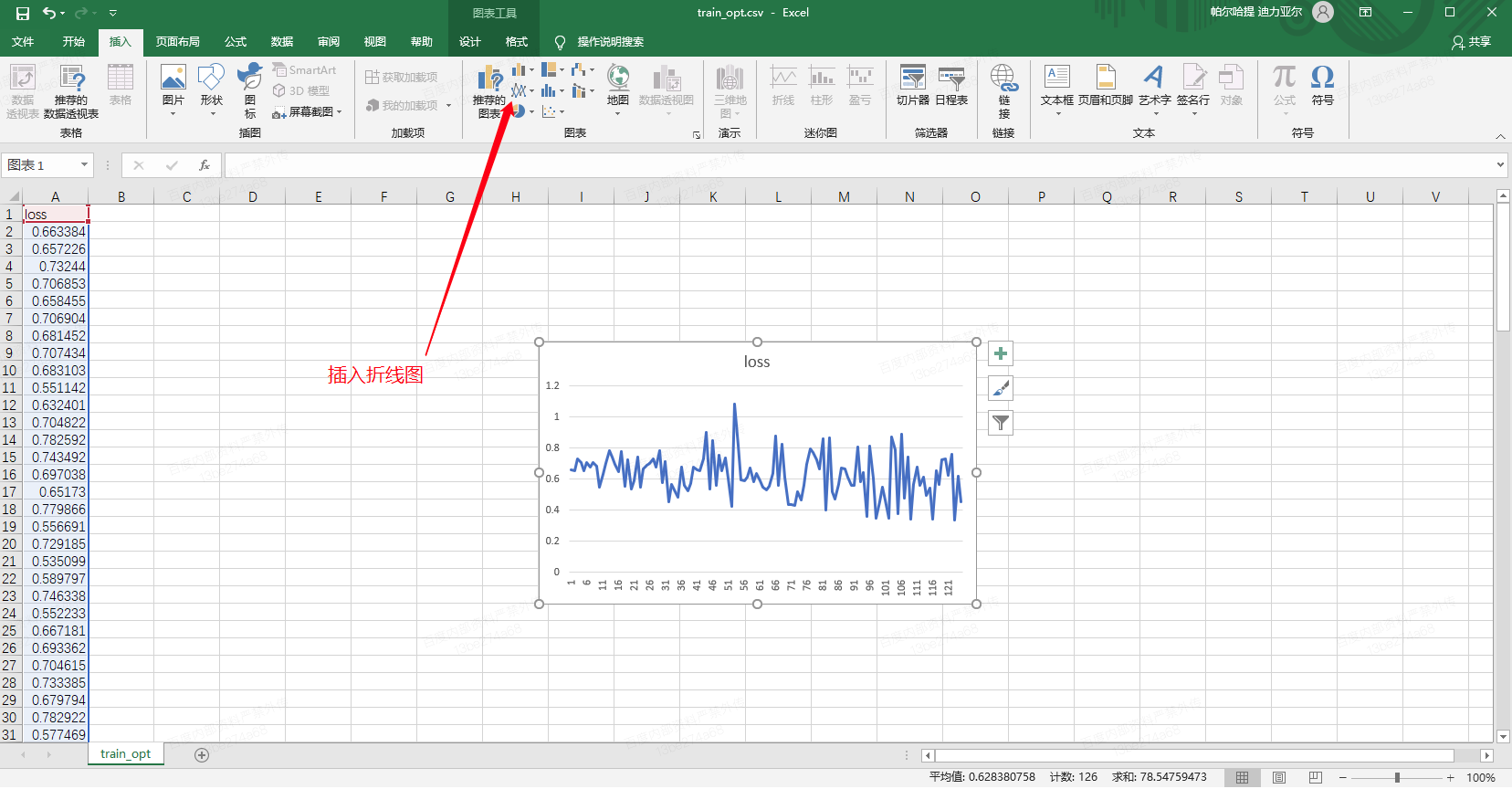
-
同时观察训练集与验证集收敛曲线,判断是否收敛完成,是过拟合还是欠拟合。
a.如果未收敛(如下图所示),可尝试调整学习率、最大训练步长等参数进行观察。
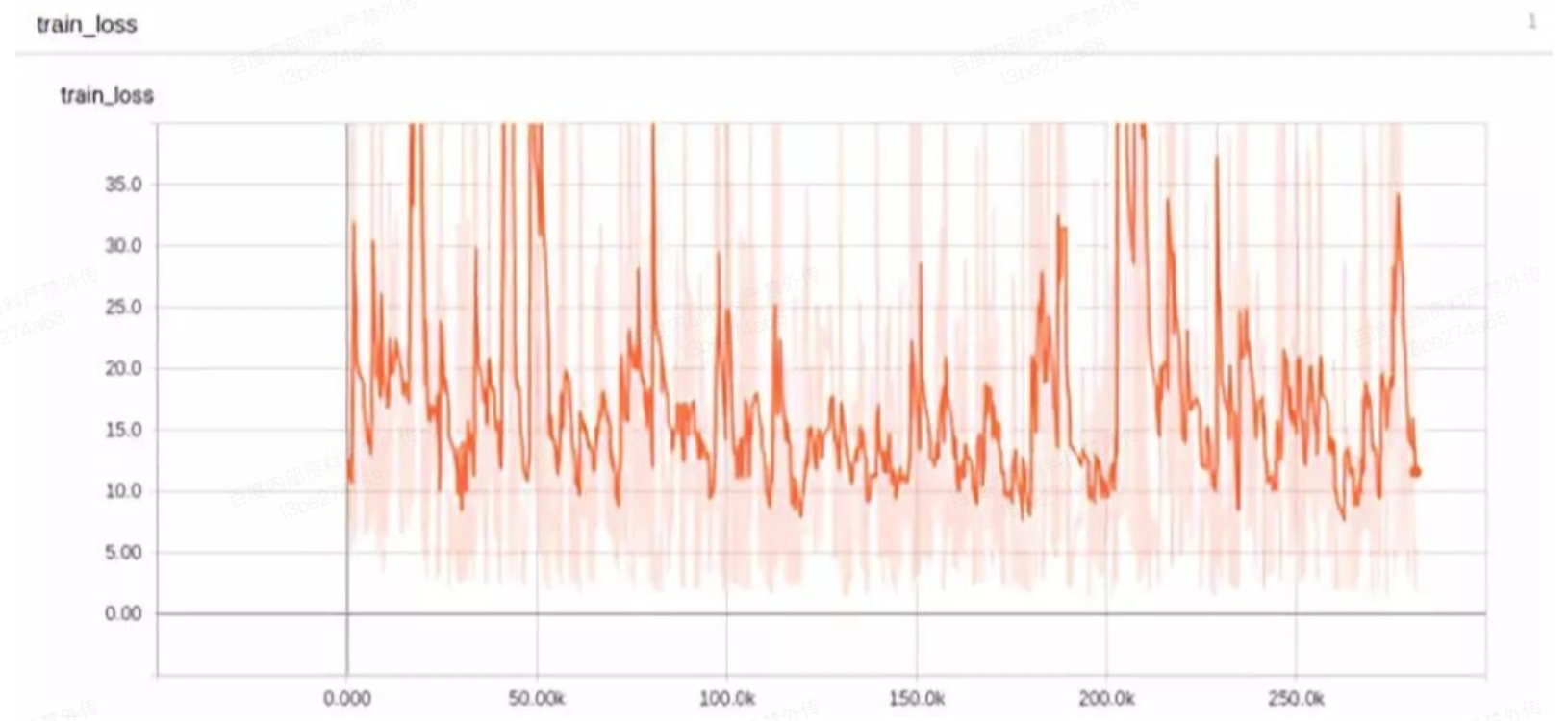
b.如果是欠拟合,一味增加数据数量没有意义,需要采用更复杂的模型。
c.如果是过拟合,可考虑降低模型复杂度,如增加正则项等工作,或者增加训练数据。
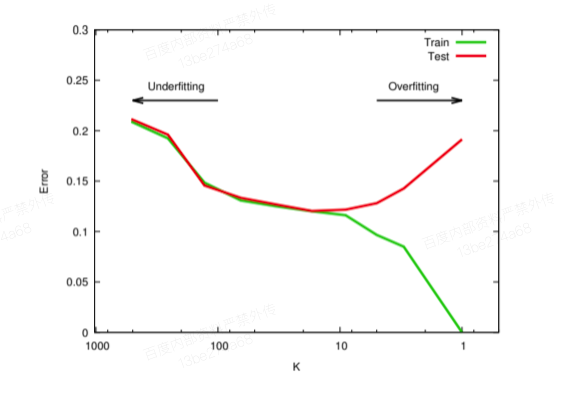
- 注:欠拟合与欠拟合的示意图如下所示:
优化调参
最常用的参数:学习率
- 学习率往往是深度学习里最常要调整的参数,
- 最简单的方式是选用adam等优化器,自动调整学习率,并且一般能够收敛到比较好的效果。
- 如果希望手动调整学习率,一般可按照等比数列调整,如每次放大(缩小)10倍\5倍进行调参。
- ERNIE系列预训练模型对学习率更加敏感,一般建议直接采用预制学习率,如果需要调整,可进行2倍3倍的放缩进行试验。
熟练运用热启动
- 可通过热启动进行多阶段训练,每一阶段将本阶段实验最好的策略模型保存起来,作为下一阶段迭代的热启动模型,可不断累加算法改进的效果。
优化组网
- 每个任务的组网建模方式有非常多,难以一一介绍。
- 一般建议优先采用ERNIE模型不加下游复杂网络进行训练,之后再考虑改进组网。
优化数据
优化数据质量
- 对于ERNIE系列预训练模型,数据的质量优于数据的数量。
- 以文本分类为例,着重关注模型预测错误的样本(badcase),将其用人工标注正确后放入训练集中,普遍能提升模型效果。特别是训练集中本来就标注错误的样本,将其人工筛选一遍重新标注,能提升模型效果。
增加数据数量
- 一般来说,过少的标注数据是限制模型优化的主要原因,可采用数据增强的方式增加训练数据。
- 在数据集很大的情况下,不建议一上来就跑全量数据。建议先用 1/100、1/10 的数据跑一跑,对模型性能和训练时间有个底,外推一下全量数据到底需要跑多久。在没有足够的信心前不做大规模实验。
- 参考:《万字长文综述:给你的数据加上杠杆——文本增强技术的研究进展及应用实践》
增加数据特征
- 如果业务场景有非文本数据特征,也可以加入到文心之中,作为单独的field进行处理。
- 可以尝试增加新的文本特征,比如N-gram、subword、分词边界、词性、语义组块等特征,可作为单独的field进行处理。