

UIE预测:预测函数和批量预测任务
UIE提供通用信息抽取、观点抽取、情感分析等能力,可抽取多种类型的信息,包括但不限于实体识别(如人名、地名、机构名等)、关系(如电影的导演、歌曲的发行时间等)、事件(如某路口发生车祸、某地发生地震等)、以及评价维度、观点词、情感倾向等信息。用户可以使用自然语言自定义抽取目标,无需训练即可抽取输入文本中的对应信息,实现开箱即用。
准备工作,下载模型:
# 进入模型文件夹
cd ../../models_hub
# 下载所有uie模型
sh ernie_uie_xxxxxx预置模型无需训练,可以参考如下两个方法使用预测功能
预测函数 - 开箱即用
最推荐的使用方式,在ernie-uie文件夹下,可以直接使用预测函数,只需要三行代码,即可实现预测功能
实际使用case在tests/test_uie_infer.py:
python3 tests/test_uie_infer.py uie-large
python3 tests/test_uie_infer.py uie-v3-large以下是各个子任务的使用示例详解:
实体抽取
命名实体识别(Named Entity Recognition,简称NER),是指识别文本中具有特定意义的实体。UIE的抽取类别没有限制,用户可以自己定义。 例如抽取的目标实体类型是"时间"、"选手"和"赛事名称", schema(预测目标)构造如下:
['时间', '选手', '赛事名称']调用示例:
>>> from pprint import pprint
>>> from uie import UIE
>>> schema = ['时间', '选手', '赛事名称']
>>> m = UIE(schema=schema)
>>> pprint(m("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!"))
[{'时间': [{'end': 6,
'probability': 0.9857378532924486,
'start': 0,
'text': '2月8日上午'}],
'赛事名称': [{'end': 23,
'probability': 0.8503089953268272,
'start': 6,
'text': '北京冬奥会自由式滑雪女子大跳台决赛'}],
'选手': [{'end': 31,
'probability': 0.8981548639781138,
'start': 28,
'text': '谷爱凌'}]}]例如抽取的目标实体类型是"肿瘤的大小"、"肿瘤的个数"、"肝癌级别"和"脉管内癌栓分级", schema构造如下:
['肿瘤的大小', '肿瘤的个数', '肝癌级别', '脉管内癌栓分级']在上例中我们已经实例化了一个UIE对象,这里可以通过set_schema方法重置抽取目标。
>>> schema = ['肿瘤的大小', '肿瘤的个数', '肝癌级别', '脉管内癌栓分级']
>>> m.set_schema(schema)
>>> pprint(m("(右肝肿瘤)肝细胞性肝癌(II-III级,梁索型和假腺管型),肿瘤包膜不完整,"
"紧邻肝被膜,侵及周围肝组织,未见脉管内癌栓(MVI分级:M0级)及卫星子灶形成。"
"(肿物1个,大小4.2×4.0×2.8cm)。"))
[{'肝癌级别': [{'end': 20,
'probability': 0.9243267447402701,
'start': 13,
'text': 'II-III级'}],
'肿瘤的个数': [{'end': 84,
'probability': 0.7538413804059623,
'start': 82,
'text': '1个'}],
'肿瘤的大小': [{'end': 100,
'probability': 0.8341128043459491,
'start': 87,
'text': '4.2×4.0×2.8cm'}],
'脉管内癌栓分级': [{'end': 70,
'probability': 0.9083292325934664,
'start': 67,
'text': 'M0级'}]}]关系抽取
关系抽取(Relation Extraction,简称RE),是指从文本中识别实体并抽取实体之间的语义关系,进而获取三元组信息,即<主体,谓语,客体>。 例如以"竞赛名称"作为抽取主体,抽取关系类型为"主办方"、"承办方"和"已举办次数", schema构造如下:
{
'竞赛名称': [
'主办方',
'承办方',
'已举办次数'
]
}调用示例:
>>> schema = {'竞赛名称': ['主办方', '承办方', '已举办次数']}
>>> m.set_schema(schema)
>>> pprint(m("2022语言与智能技术竞赛由中国中文信息学会和中国计算机学会联合主办,"
"百度公司、中国中文信息学会评测工作委员会和中国计算机学会自然语言处理专委会承办,"
"已连续举办4届,成为全球最热门的中文NLP赛事之一。"))
[{'竞赛名称': [{'end': 13,
'probability': 0.7825402622754041,
'relations': {'主办方': [{'end': 22,
'probability': 0.8421710521379353,
'start': 14,
'text': '中国中文信息学会'},
{'end': 30,
'probability': 0.7580801847701935,
'start': 23,
'text': '中国计算机学会'}],
'已举办次数': [{'end': 82,
'probability': 0.4671295049136148,
'start': 80,
'text': '4届'}],
'承办方': [{'end': 39,
'probability': 0.8292706618236352,
'start': 35,
'text': '百度公司'},
{'end': 72,
'probability': 0.6193477885474685,
'start': 56,
'text': '中国计算机学会自然语言处理专委会'},
{'end': 55,
'probability': 0.7000497331473241,
'start': 40,
'text': '中国中文信息学会评测工作委员会'}]},
'start': 0,
'text': '2022语言与智能技术竞赛'}]}]事件抽取
事件抽取 (Event Extraction, 简称EE),是指从自然语言文本中抽取预定义的事件触发词(Trigger)和事件论元(Argument),组合为相应的事件结构化信息。 例如抽取的目标是"地震"事件的"地震强度"、"时间"、"震中位置"和"震源深度"这些信息,schema构造如下:
{
'地震触发词': [
'地震强度',
'时间',
'震中位置',
'震源深度'
]
}触发词的格式统一为触发词或XX触发词,XX表示具体事件类型,上例中的事件类型是地震,则对应触发词为地震触发词。
调用示例:
>>> schema = {'地震触发词': ['地震强度', '时间', '震中位置', '震源深度']}
>>> m.set_schema(schema) # Reset schema
>>> pprint(m("中国地震台网正式测定:5月16日06时08分在云南临沧市凤庆县(北纬24.34度,东经99.98度)发生3.5级地震,"
"震源深度10千米。"))
[{'地震触发词': [{'end': 58,
'probability': 0.9987181623528585,
'relations': {'地震强度': [{'end': 56,
'probability': 0.9962985320905915,
'start': 52,
'text': '3.5级'}],
'时间': [{'end': 22,
'probability': 0.9882578028575182,
'start': 11,
'text': '5月16日06时08分'}],
'震中位置': [{'end': 50,
'probability': 0.8551415716584501,
'start': 23,
'text': '云南临沧市凤庆县(北纬24.34度,东经99.98度)'}],
'震源深度': [{'end': 67,
'probability': 0.999158304648045,
'start': 63,
'text': '10千米'}]},
'start': 56,
'text': '地震'}]}]评论观点抽取
评论观点抽取,是指抽取文本中包含的评价维度、观点词等。 例如抽取的目标是文本中包含的评价维度及其对应的观点词和情感倾向,schema构造如下:
{
'评价维度': [
'观点词',
'情感倾向[正向,负向]'
]
}调用示例:
>>> schema = {'评价维度': ['观点词', '情感倾向[正向,负向]']}
>>> m.set_schema(schema)
>>> pprint(m("店面干净,很清静,服务员服务热情,性价比很高,发现收银台有排队"))
[{'评价维度': [{'end': 20,
'probability': 0.9817040258681473,
'relations': {'情感倾向[正向,负向]': [{'probability': 0.9966142505350533,
'text': '正向'}],
'观点词': [{'end': 22,
'probability': 0.957396472711558,
'start': 21,
'text': '高'}]},
'start': 17,
'text': '性价比'},
{'end': 2,
'probability': 0.9696849569741168,
'relations': {'情感倾向[正向,负向]': [{'probability': 0.9982153274927796,
'text': '正向'}],
'观点词': [{'end': 4,
'probability': 0.9945318044652538,
'start': 2,
'text': '干净'}]},
'start': 0,
'text': '店面'}]}]情感分类
句子级情感倾向分类,即判断整句的情感倾向是“正向”还是“负向”。实体级情感倾向分类,则判断句子中的某个具体实体的情感倾向。 句子级情感分类的schema构造如下:
'情感倾向[正向,负向]'实体级情感分类的schema构造如下:
{'水果': ['情感倾向[正向,负向]']}调用示例:
>>> schema = '情感倾向[正向,负向]'
>>> m.set_schema(schema)
>>> m('这个产品用起来真的很流畅,我非常喜欢')
[{'情感倾向[正向,负向]': [{'text': '正向', 'probability': 0.9988661643929895}]}]
>>> schema = {'水果': ['情感倾向[正向,负向]']}
>>> m.set_schema(schema)
>>> pprint(m('今天去超市买了香蕉、葡萄,香蕉吃起来还不错,葡萄快酸死了。'))
[{'水果': [{'end': 12,
'probability': 0.9880225658416748,
'relations': {'情感倾向[正向,负向]': [{'end': 1,
'probability': 0.7870954275131226,
'relations': {},
'start': 0,
'text': '负向'}]},
'start': 10,
'text': '葡萄'},
{'end': 24,
'probability': 0.9842413663864136,
'relations': {'情感倾向[正向,负向]': [{'end': 1,
'probability': 0.7870954275131226,
'relations': {},
'start': 0,
'text': '负向'}]},
'start': 22,
'text': '葡萄'},
{'end': 15,
'probability': 0.9612904191017151,
'relations': {'情感倾向[正向,负向]': [{'end': 1,
'probability': 0.9928863644599915,
'relations': {},
'start': 0,
'text': '正向'}]},
'start': 13,
'text': '香蕉'},
{'end': 9,
'probability': 0.8633676171302795,
'relations': {'情感倾向[正向,负向]': [{'end': 1,
'probability': 0.9928863644599915,
'relations': {},
'start': 0,
'text': '正向'}]},
'start': 7,
'text': '香蕉'}]}]跨任务抽取
例如在法律场景同时对文本进行实体抽取和关系抽取,schema可按照如下方式进行构造:
[
"法院",
{
"原告": [
"委托代理人",
"法定代表人"
]
},
{
"被告": [
"委托代理人",
"法定代表人"
]
}
]调用示例:
>>> schema = ['法院', {'原告': '委托代理人'}, {'被告': '委托代理人'}]
>>> m.set_schema(schema)
>>> pprint(m("北京市海淀区人民法院\n民事判决书\n(199x)建初字第xxx号\n原告:张三。\n"
"委托代理人李四,北京市 A律师事务所律师。\n被告:B公司,法定代表人王五,开发公司总经理。"))
[{'原告': [{'end': 37,
'probability': 0.9955972637653154,
'relations': {'委托代理人': [{'end': 46,
'probability': 0.9835957661618089,
'start': 44,
'text': '李四'}]},
'start': 35,
'text': '张三'}],
'法院': [{'end': 10,
'probability': 0.9245885500450299,
'start': 0,
'text': '北京市海淀区人民法院'}],
'被告': [{'end': 67,
'probability': 0.9033652934762237,
'relations': {'委托代理人': [{'end': 46,
'probability': 0.3863244074945271,
'start': 44,
'text': '李四'}]},
'start': 64,
'text': 'B公司'}]}]端到端文档抽取(UIE-X)
UIE-X支持端到端的文档信息抽取,其内部利用PaddleOCR、pyMuPDF、pydocx(需要自行安装)解析图片、pdf和word文档的内容,然后将解析的文本和layout信息输入给模型,进行端到端的文档信息提取。UIE-X支持从表格中提取信息,但需注意其并不能直接完整的还原表格内容,只能通过prompt来提取表格中对应的信息片段。 UIE-X比较适合单证文档(票据、单据)的信息提取,目前不适合过长或页数过多的文档。例如下面报关单即属于单证文档的范畴。
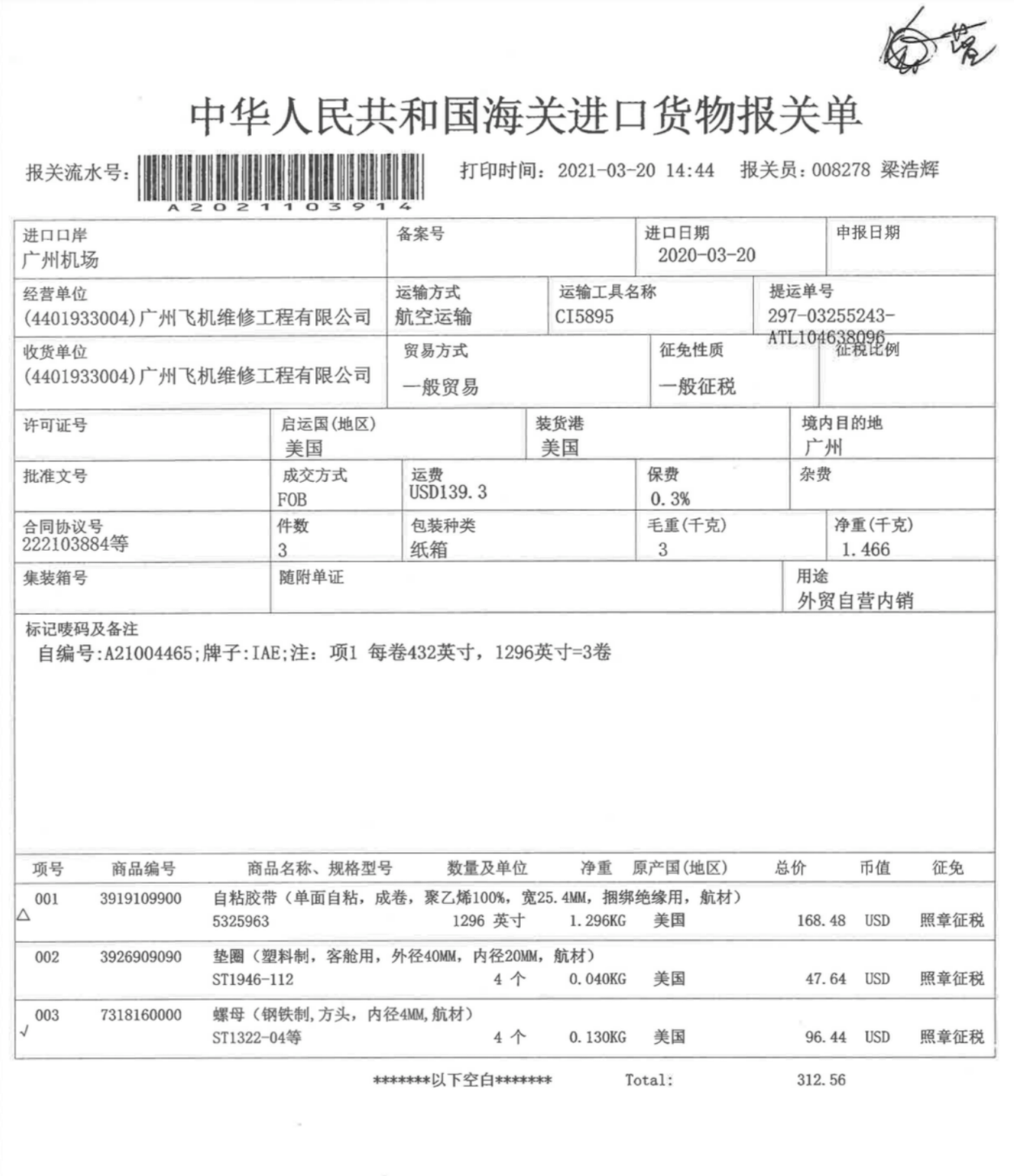
我们设置如下的Schema,其中使用一个dict表达下方二维表的Schema,dict的key是表格的主键值prompt,value为属性值的prompt。
[
"打印时间", "报关员", "进口口岸", "进口日期", "经营单位", "运输方式", "运输工具名称", "提运单号", "收货单位",
"交易方式", "征免性质", "启运国", "装货港", "境内目的地", "成交方式", "运费", "保费", "合同协议号", "件数",
"包装种类", "毛重", "净重", "用途",
{
"商品编号": ["商品名称、规格型号", "数量及单位", "净重", "原产国", "总价", "币值", "征免"]
}
]UIE-X支持三种文档格式输入,包括图片:{"image": "url/file/base64"}, PDF:{"pdf": "url/file/base64", "page_num": 0}和Word文档:{"docx": "url/file/base64"},其会自动调用PaddleOCR、pyMuPDF、和pydocx进行文档解析,然后进行预测。也可以输入已经解析好的文档layout:{"layout": [{"text": "TEXT", "box": [x1,y1,x2,y2]}, ...], "image": "url/file/base64"}。调用示例如下:
# 这里需要使用uie-v3-large的模型
>>> m3 = UIE(model='uie-v3-large')
>>> schema = ["打印时间", "报关员", "进口口岸", "进口日期", "经营单位", "运输方式", "运输工具名称", "提运单号", "收货单位", "交易方式", "征免性质", "启运国", "装货港", "境内目的地", "成交方式", "运费", "保费", "合同协议号", "件数", "包装种类", "毛重", "净重", "用途", {"商品编号": ["商品名称、规格型号", "数量及单位", "净重", "原产国", "总价", "币值", "征免"]}]
>>> m.set_schema(schema)
>>>results = m3({"image": "
http://ku.baidu-int.com/wiki/attach/image/api/imageDownloadAddress?attachId=b4dce163b86f46bab391b0b7c2f5c1ff&docGuid=INdW1ex8UMEBMI&sign=eyJhbGciOiJkaXIiLCJlbmMiOiJBMjU2R0NNIiwiYXBwSWQiOjEsInVpZCI6IlhPMlFqWnBQV2EiLCJkb2NJZCI6IklOZFcxZXg4VU1FQk1JIn0..mDN4jlmv0C7wClMs.BX8iENAmbcJR3L0_LjnrRwbG7jlrApLjBDC001-NupMara4KW9ZaaieMuqfApZ5tWqO5BngBc1uRCyo7DXV_n7TDpZpcxcvLFhRC7hsUx9s6kALiYawRc5RrFIWRLcq6Ff2z9ZCR3ZO0HiB0a0wwuaItYTiS8B02eP8P-WiPYfXe_SljVE-DMMHa8CyzsxKfqEek38y-YN0rbSiLggkwn_TZBQ.HAJfiiqwjhdX68S7BfBbKA也可以先parse文档,然后在进行预测,调用示例如下:
>>> parsed_doc = m3.parse({"image": "
http://ku.baidu-int.com/wiki/attach/image/api/imageDownloadAddress?attachId=b4dce163b86f46bab391b0b7c2f5c1ff&docGuid=INdW1ex8UMEBMI&sign=eyJhbGciOiJkaXIiLCJlbmMiOiJBMjU2R0NNIiwiYXBwSWQiOjEsInVpZCI6IlhPMlFqWnBQV2EiLCJkb2NJZCI6IklOZFcxZXg4VU1FQk1JIn0..mDN4jlmv0C7wClMs.BX8iENAmbcJR3L0_LjnrRwbG7jlrApLjBDC001-NupMara4KW9ZaaieMuqfApZ5tWqO5BngBc1uRCyo7DXV_n7TDpZpcxcvLFhRC7hsUx9s6kALiYawRc5RrFIWRLcq6Ff2z9ZCR3ZO0HiB0a0wwuaItYTiS8B02eP8P-WiPYfXe_SljVE-DMMHa8CyzsxKfqEek38y-YN0rbSiLggkwn_TZBQ.HAJfiiqwjhdX68S7BfBbKA使用以下接口,可以可视化parse结果(OCR结果)
>>> m3.doc_parser.write_image_without_results(parsed_doc['image'], layouts=parsed_doc['layout'], max_size=2000, save_path='doc_parse_result.jpg')
使用以下接口,可以可视化预测结果
>>> results = m3.flatten_results(results) # 首先flatten下results
>>> m3.doc_parser.write_image_without_results(parsed_doc['image'], layouts=results[0], max_size=2000, save_path='doc_result.jpg')
模型选择
MONET提供多种模型规模供选择,后续版本会追加更多模型大小 完整可选模型参考UIE任务介绍章节
| 模型 | 结构 | QPS (GPU*) | QPS (CPU**) |
|---|---|---|---|
| uie-large | 24-layers,1024-hidden,24-heads | 133.3 | 0.65 |
*NVIDIA A100单卡,序列长度512,batch_size 16~32 **Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz单核,序列长度512,batch_size 16 注:以上结论使用单个schema字段测试,多个字段性能需要除以schema字段数
更多配置
def UIE(model='uie-large',
schema=None,
prob_threshold=0.5,
is_single_result=False)- prob_threshod[float]: 预测结果的概率阈值(默认0.5)
- is_single_result[bool]: 预测结果是否为单值(默认为多值)
批量预测任务
不建议使用此种方式:如果用第一种预测函数的方式,可以根据schema自动构建有结构数据的先后预测内容 UIE的训练和预测数据格式一致,均为
{
"content": "丝角蝗科,Oedipodidae,昆虫纲直翅目蝗总科的一个科\t丝角蝗科的目", # 原文内容\tprompt内容
"annotations": {"UIE": [ # 标注结果,预测时为空
{
"text": "直翅目",
"segments": [
{"text": "直翅目", "start_offset": 20, "end_offset": 23}
],
"label": "answer"
}
]},
"title": "OPEN\tRE\tLIC2019",
# 有图片输入时,有以下输入
"bbox_lines": [ # [x1, y1, x2, y2], 为content中每个字符对应的bbox,此处的bbox取每个字符所在的segment的bbox
[12, 25, 23, 50], [12, 25, 23, 50]......
],
# image 和 image_path二选一提供
"image": "d1dw81hd193......", # 图片的base64数据
"image_path": "img/sample.jpg", # 图片相对训练文件的存储路径
}使用示例数据进行批量预测(预测结果在output/predict_result.txt):
python3 run_infer.py --param_path ./examples/ernie_uie_v1_large_infer.json
python3 run_infer.py --param_path ./examples/ernie_uie_v2_large_infer.json
python3 run_infer.py --param_path ./examples/ernie_uie_v3_large_infer.json