

准备工作:文本匹配
数据准备
在文心中,基于ERNIE的模型都不需要用户自己分词和生成词表文件,非ERNIE的模型需要用户自己提前切好词,词之间以空格分隔,并生成词表文件。切词和词表生成可以使用【快速开始->数据预处理工具】进行处理。
文心中的所有数据集、包含词表文件、label_map文件等都必须为为utf-8格式,如果你的数据是其他格式,请使用快速使用->数据预处理工具进行格式转换。
在文本匹配任务中,根据其训练方式的不同,训练集分为Pointwise和Pairwise两种格式,测试集、验证集和预测集的格式相同。
- 非ERNIE数据的pointwise训练集、pairwise训练集、测试集、验证集和预测集分别存放在./data目录下的train_data_pointwise_tokenized、train_data_pairwise_tokenized、test_data_tokenized、dev_data_tokenized和predict_data_tokenized文件夹下。
- ERNIE数据的pointwise训练集、pairwise训练集、测试集、验证集和预测集分别存放在./data目录下的train_data_pointwise、train_data_pairwise、test_data、dev_data和predict_data文件夹下。
下面将提供具体示例:
非ERNIE模型数据
-
训练集
-
Pointwise训练集
Pointwise训练集样例如下所示,数据分为三列,列与列之间用\t分割。前两列为文本,最后一列为标签。
喜欢 打篮球 的 男生 喜欢 什么样 的 女生 爱 打篮球 的 男生 喜欢 什么样 的 女生 1 我 手机 丢 了 , 我 想 换 个 手机 我 想 买 个 新手机 , 求 推荐 1 大家 觉得 她 好看 吗 大家 觉得 跑 男 好看 吗 ? 0 -
Pairwise训练集
Pairwise训练集样例如下所示,数据分为三列,列与列之间用\t分割,以query和文章标题匹配任务为例,第一列为query,第二列为正例标题pos_titile,第三列为负例标题neg_title。
喜欢 打篮球 的 男生 喜欢 什么样 的 女生 爱 打篮球 的 男生 喜欢 什么样 的 女生 爱情 里 没有 谁 对 谁错 吗 ? 我 手机 丢 了 , 我 想 换 个 手机 我 想 买 个 新手机 , 求 推荐 剑灵 高级 衣料 怎么 得 大家 觉得 她 好看 吗 大家 觉得 跑 男 好看 吗 ? 照片 怎么 变成 漫画
-
-
词表
ERNIE此表文件格式与非ERNIE的格式一致,由文心提供
[PAD] 0 [CLS] 1 [SEP] 2 [MASK] 3 的 4 这个 5 您好 6 ... [UNK] 1566 -
测试集/验证集
测试集/验证集样例如下所示,数据分为三列,列与列之间用\t进行分隔,前两列为文本,最后一列为标签。
我 姓 王 图片 怎么 制作 制作 文字 图片 0 为什么 鱼 会 被 淹死 为什么 鱼 会 淹死 1 深圳 如何 过 澳门 深圳 去 澳门 该 怎样 去 1 -
预测集
预测集样例如下所示,预测集无需进行标签预占位,数据为两列文本,两列文本之间使用\t进行分隔。
图片 上 得 牌子 是 什么 图片 上 是 什么 牌子 的 包 芹菜 包 什么 肉 好吃 芹菜 炒 啥 好吃 汽车 坐垫 什么 牌子 好 ? 什么 牌子 的 汽车 坐垫 好
ERNIE模型数据
-
ERNIE数据集与非ERNIE数据集格式一致,不同之处在于不用分词,以验证集/测试集为例子,如下所示:
我姓王图片怎么制作 制作文字图片 0 为什么鱼会被淹死 为什么鱼会淹死 1 深圳如何过澳门 深圳去澳门该怎样去 1 -
词表
ERNIE词表文件格式与非ERNIE的格式一致,ERNIE词表由文心提供,wenxin/tasks/model_files/dict路径下有各ERNIE模型的词表文件,用户可根据需要进行选择,具体示例如下所示:
[PAD] 0 [CLS] 1 [SEP] 2 [MASK] 3 , 4 的 5 、 6 一 7 人 8 -
非ERNIE预测数据集示例:仅一列为文本,不需要标签列
USB接口 只有 2个 , 太 少 了 点 , 不能 接 太多 外 接 设备 ! 表面 容易 留下 污垢 ! 平时 只 用来 工作 , 上 上网 , 挺不错 的 , 没有 冗余 的 功能 , 样子 也 比较 正式 ! 还 可以 吧 , 价格 实惠 宾馆 反馈 2008年4月17日 : 谢谢 ! 欢迎 再次 入住 其士 大酒店 。 -
非ERNIE模型的词表文件示例:词表分为两列,第一列为词,第二列为id(从0开始),列与列之间用\t进行分隔。文心的词表中,[PAD]、[CLS]、[SEP]、[MASK]、[UNK]这5个词是必须要有的,若用户自备词表,需保证这5个词是存在的。部分词表示例如下所示:
[PAD] 0 [CLS] 1 [SEP] 2 [MASK] 3 [UNK] 4 郑重 5 天空 6 工地 7 神圣 8 -
ERNIE数据集与非ERNIE数据集格式一致,不同之处在于不用分词,如下所示:
选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 1 15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很美观,做工也相当不错 1 房间太小。其他的都一般。。。。。。。。。 0 -
ERNIE词表文件格式与非ERNIE的格式一致,由文心提供。
[PAD] 0 [CLS] 1 [SEP] 2 [MASK] 3 , 4 的 5 、 6 一 7 人 8 有 9
网络(模型)选择
文心预置的可用于文本分类的模型源文件在wenxin_appzoo/tasks/text_matching/model目录下,在介绍具体的模型前先对文本匹配网络涉及到的概念进行描述。
| 单塔 | 双塔 | |
|---|---|---|
| Pointwise |  |
 |
| Pairwise | 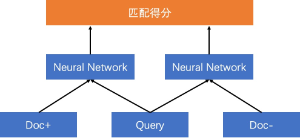 |
 |
-
Pointwise/Pairwise
-
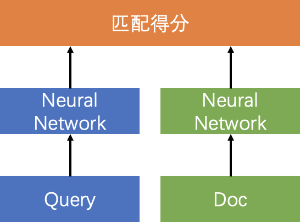
Pointwise
输入两个文本和一个标签,可看作为一个分类问题,即判断输入的两个文本是否匹配。
-
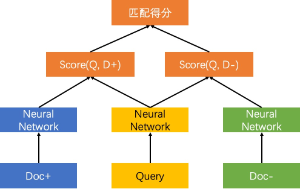
Pairwise
输入为三个文本,分别为Query以及对应的正样本和负样本,该训练方式考虑到了文本之间的相对顺序。
-
-
单塔/双塔
-
单塔
先将输入文本合并,然后输入到单一的神经网络模型。
-
双塔
对输入文本分别进行编码成固定长度的向量,通过文本的表示向量进行交互计算得到文本之间的关系。
-
各个模型的特点如下所示:
| 网络名称(py文件的类名) | 简介 | 支持类型 | 支持预训练模型 |
|---|---|---|---|
| BowMatchingPairwise | 词袋模型,不考虑句子语序,用一组无序单词来表达一段文本;Pairwise双塔模型。 | Pairwise | 无 |
| ErnieMatchingFcPointwise | 增加ERNIE预训练模型,下游网络为基础的文本匹配模型,可以任意搭配其他各种经典网络;Pointwise单塔模型。 | Pointwise | ERNIE1.0、ERNIE2.0-Base、ERNIE2.0-Large、ERNIE2.1-Base、ERNIE2.1-Large、ERNIE2.2-Base、ERNIE-Tiny |
| ErnieMatchingSiamesePairwise | 增加ERNIE预训练模型,下游网络采用余弦相似度作为匹配度计算,损失函数为合页损失函数;Pairwise双塔模型。 | Pairwise | ERNIE1.0、ERNIE2.0-Base、ERNIE2.0-Large、ERNIE2.1-Base、ERNIE2.1-Large、ERNIE2.2-Base、ERNIE-Tiny、ERNIE-SIM |
| ErnieMatchingSiamesePointwise | 增加ERNIE预训练模型,下游网络采用长短期记忆网络,可较好地处理序列文本中长距离依赖的问题;Pointwise双塔模型; | Pointwise | ERNIE1.0、ERNIE2.0-Base、ERNIE2.0-Large、ERNIE2.1-Base、ERNIE2.1-Large、ERNIE2.2-Base、ERNIE-Tiny、ERNIE-SIM |
ERNIE预训练模型选择
文心提供的ERNIE预训练模型的下载脚本在wenxin_appzoo/models_hub目录下,各预训练模型可由对应的download_xx.sh文件下载得到,用户可根据需求自行下载。其中,ernie_config.json为ERNIE预训练模型的配置文件,vocab.txt为ERNIE预训练模型的词表文件,params目录为ERNIE预训练模型的参数文件目录,以下是各个ERNIE预训练模型的介绍。
| 模型名称 | 简介 |
|---|---|
| ERNIE 1.0 | ERNIE 1.0通过建模海量数据中的词、实体及实体关系,学习真实世界的语义知识。相较于 BERT 学习原始语言信号,ERNIE 直接对先验语义知识单元进行建模,增强了模型语义表示能力。 |
| ERNIE 2.0 | ERNIE 2.0是基于持续学习的语义理解预训练框架,使用多任务学习增量式构建预训练任务。ERNIE 2.0中,新构建的预训练任务类型可以无缝的加入训练框架,持续的进行语义理解学习。 通过新增的实体预测、句子因果关系判断、文章句子结构重建等语义任务,ERNIE 2.0语义理解预训练模型从训练数据中获取了词法、句法、语义等多个维度的自然语言信息,极大地增强了通用语义表示能力。 |
| ERNIE 2.3 | ERNIE 2.3是针对ERNIE2.0优化后的一个版本,通过提出多视角对抗预训练语言技术、随机位置编码策略和对比自监督预训练技术,使得模型在8个中文主流下游任务上获得了明显的效果提升。 |
| ERNIE-Tiny | ERNIE-Tiny网络结构与ERNIE 1.0 base 中文模型不完全相同,有独立的模型配置json文件和dict。与传统基于字粒度的ERNIE中文模型不同,ERNIE Tiny是基于词粒度的预训练模型。 |
| ERNIE-SIM | ERNIE-Sim是针对提升中文短文本语义匹配效果预训练模型,模型结构与ERNIE 1.0 base中文模型相同,共享ERNIE 1.0 base中文模型的模型配置json文件和dict。 |
| ERNIE-Sim2.0 | ERNIE-Sim2.0 是针对提升中文短文本语义匹配效果预训练模型,其是在 ERNIE-Sim的基础上引入更多、更丰富的预训练数据和基于动态ngram的字词混合粒度对比策略。ERNIE-Sim2.0 模型结构与 ERNIE-Sim模型相同,模型配置文件和词表文件也与 ERNIE-Sim一致。 |
模型评估指标选择
匹配任务常用的指标有:Acc(准确率)、Precision(精确率)、Recall(召回率)、pn(正逆序比)、Auc、F1等,详见基本概念->Metrics 文心中上述已有的网络(模型)代码中已经默认预置了Acc(准确率)、Precision(精确率)、pn(正逆序比)、Auc计算。
运行环境选择
- 非ERNIE网络,优先考虑CPU机器
- ERNIE网络优先考虑GPU机器,显存大小最好在10G以上。