

ERNIE 2.0介绍
ERNIE 2.0
简介
ERNIE 2.0(A Continual Pre-training framework for Language Understanding)是基于持续学习的语义理解预训练框架,使用多任务学习增量式构建预训练任务。在ERNIE 2.0中,新构建的预训练任务类型可以无缝的加入训练框架,持续的进行语义理解学习。 通过新增的实体预测、句子因果关系判断、文章句子结构重建等语义任务,ERNIE 2.0 语义理解预训练模型从训练数据中获取了词法、句法、语义等多个维度的自然语言信息,极大地增强了通用语义表示能力。
技术原理
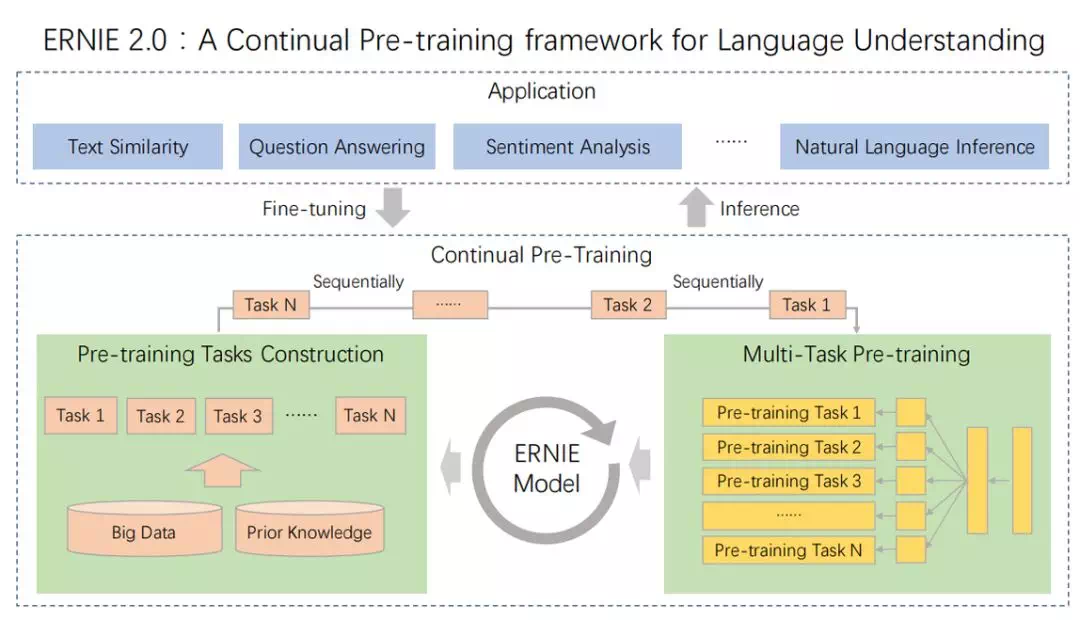
传统的pre-training 模型主要基于文本中words 和 sentences 之间的共现进行学习, 事实上,训练文本数据中的词法结构,语法结构,语义信息也同样是很重要的。在命名实体识别中人名,机构名,组织名等名词包含概念信息对应了词法结构。句子之间的顺序对应了语法结构,文章中的语义相关性对应了语义信息。为了去发现训练数据中这些有价值的信息,在ERNIE 2.0 中,提出了一个预训练框架,可以在大型数据集合中进行增量训练。基本框架如下图所示,核心特点就是多任务学习和持续训练:
-
多任务:ERNIE 2.0主要包含以下三类预训练任务
- Word-aware Pre-training Task: 词汇 (lexical) 级别信息的学习
- Structure-aware Pre-training Task: 语法 (syntactic) 级别信息的学习
- Semantic-aware Pre-training Task: 语义 (semantic) 级别信息的学习

-
持续训练
ERNIE 2.0 框架能通过多任务学习持续更新预训练模型,这也就是「持续预训练」的含义。在每一次微调中,ERNIE 会首先初始化已经预训练的权重,然后再使用具体任务的数据微调模型。这里的持续训练过程分为2个步骤,即构建无监督预训练任务和通过多任务学习增量地更新 ERNIE 模型。这里不同的任务是一个序列,因此模型在学习新任务时能记住已经学到过的知识。如下图所示为连续预训练的架构,它包含一系列共享的文本编码层来编码上下文信息,这些文本编码层可以通过循环神经网络或 Transformer 构建,且编码器的参数能通过所有预训练任务更新。

模型效果
-
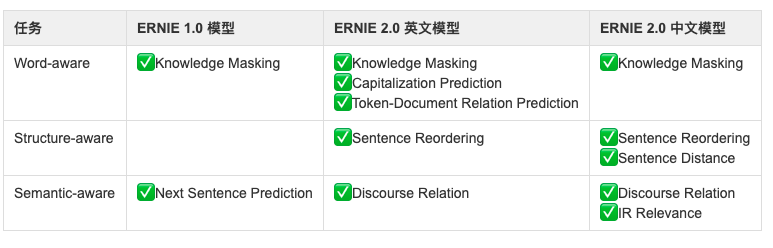
ERNIE 2.0与ERNIE 1.0的预训练任务对比
-
ERNIE 2.0在中文任务上的效果:9 大中文 NLP 任务,包括机器阅读理解、命名实体识别、自然语言推断、语义相似度、语义分析和问答。模型结果均为五次实验结果的中位数,粗体字表示 SOTA 结果。

-
ERNIE2.0在英文任务上的效果:模型在 GLUE 上的结果,其中开发集上的结果是五次实验结果的中位数,测试集结果是通过 GLUE 评估服务完成的。

文心中ERNIE 2.0的支持
目前文心提供ERNIE 2.0的Base和Large两个版本的中文模型。ERNIE 2.0 Base 中文模型模型结构与ERNIE 1.0 Base 中文模型相同,共享ERNIE 1.0 Base 中文模型的模型配置json文件和词表文件。ERNIE2.0的模型下载脚本位于./wenxin/tasks/model_files/目录下,download_ernie_2.0_base.sh和download_ernie_2.0_large.sh ; 配置文件在./wenxin/tasks/model_files/config/目录下,ernie_2.0_base_ch_config.json和ernie_2.0_large_ch_config.json;词表文件在./wenxin/tasks/model_files/dict/目录下,vocab_ernie_2.0_base_ch.txt 和vocab_ernie_2.0_large_ch.txt 。