

(升级)模型蒸馏任务
任务简介
- 基于ERNIE预训练模型效果上达到业界领先,但是由于模型比较大,预测性能可能无法满足上线需求。
- 直接使用ERNIE-Tiny系列轻量模型fine-tune,效果可能不够理想。如果采用数据蒸馏策略,又需要提供海量未标注数据,可能并不具备客观条件。
- 因此,本专题采用主流的知识蒸馏的方案来压缩模型,在满足用户预测性能、预测效果的需求同时,不依赖海量未标注数据,提升开发效率。
- 文心提供多种不同大小的基于字粒度的ERNIE-Tiny学生模型,满足不同用户的需求。
注:知识蒸馏(KD)是将复杂模型(teacher)中的dark knowledge迁移到简单模型(student)中去,teacher具有强大的能力和表现,而student则更为紧凑。通过知识蒸馏,希望student能尽可能逼近亦或是超过teacher,从而用更少的复杂度来获得类似的预测效果。
模型蒸馏原理
- 知识蒸馏是一种模型压缩常见方法,指的是在teacher-student框架中,将复杂、学习能力强的网络(teacher)学到的特征表示"知识"蒸馏出来,传递给参数量小、学习能力弱的网络(student)。
- 在训练过程中,往往以最优化训练集的准确率作为训练目标,但真实目标其实应该是最优化模型的泛化能力。显然如果能直接以提升模型的泛化能力为目标进行训练是最好的,但这需要正确的关于泛化能力的信息,而这些信息通常不可用。如果我们使用由大型模型产生的所有类概率作为训练小模型的目标,就可以让小模型得到不输大模型的性能。这种把大模型的知识迁移到小模型的方式就是蒸馏。
- 基本原理可参考Hinton经典论文:https://arxiv.org/abs/1503.02531
ERNIE-Tiny 模型蒸馏
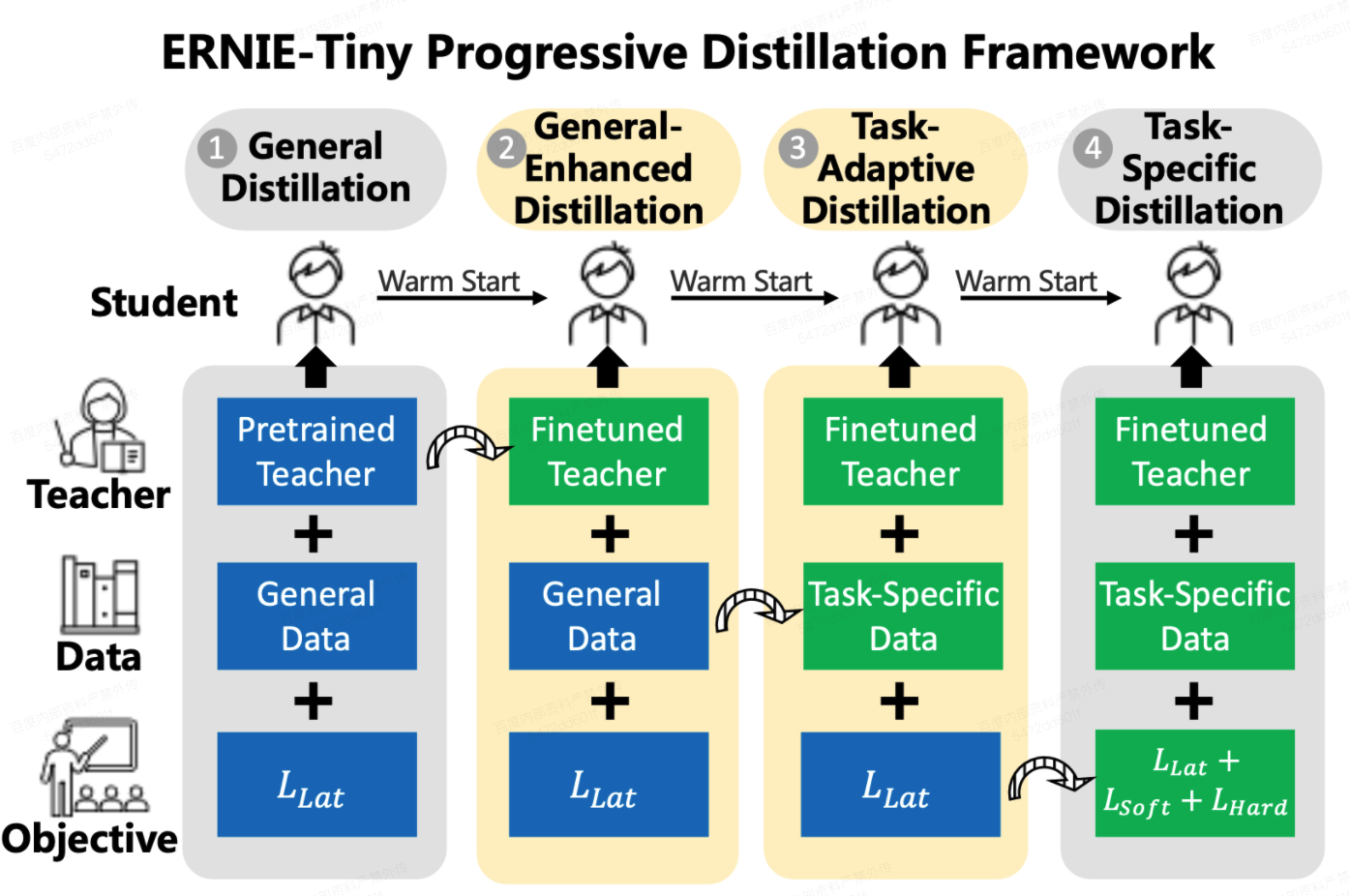
- 模型蒸馏原理可参考论文 ERNIE-Tiny。不同于原论文的实现,为了和开发套件中的通用蒸馏学生模型保持一致,我们将蒸馏loss替换为Attention矩阵的KQ loss和 VV loss,原理可参考论文 MiniLM 和 MiniLMV2。实验表明通用蒸馏阶段和任务蒸馏阶段的蒸馏loss不匹配时,学生模型的效果会受到影响。
-
二阶段蒸馏:
- 通用蒸馏(General Distillation,GD):在预训练阶段训练,使用大规模无监督的数据, 帮助学生网络学习到尚未微调的教师网络中的知识,有利于提高泛化能力。为方便用户使用,我们提供了多种尺寸的通用蒸馏学生模型,可用的通用蒸馏学生模型可参考文档:通用模型 - ERNIE3.0 Tiny。
- 任务蒸馏(Task-specific Distillation,TD):使用具体任务的数据,学习到更多任务相关的具体知识。
- 如果已提供的通用蒸馏学生模型尺寸符合需求,用户可以主要关注接下来的任务蒸馏过程。
任务蒸馏步骤
- FT阶段:基于ERNIE 3.0 Large蒸馏模型fine-tune得到教师模型,注意这里用到的教师模型和ERNIE 3.0 Large是两个不同的模型;
-
GED阶段(可选):使用fine-tuned教师模型和通用数据*继续用通用蒸馏的方式蒸馏学生模型,进一步提升学生模型的效果;
a. 热启动fine-tuned的教师模型和通用学生模型。其中,通用的学生模型由文心平台提供,从bos上下载。
-
TD1阶段:蒸馏中间层
a. 只对学生模型的最后一层进行蒸馏,将学生模型transformer的attention层的k-q矩阵和v-v矩阵与教师模型的对应矩阵做KL loss,可参考 :MiniLMV2。
b. 热启动fine-tuned的教师模型和GED阶段得到的学生模型。其中,通用的学生模型由文心平台提供,从bos上下载,下载链接所在文档:通用模型 - ERNIE3.0 Tiny,或参考预置的下载脚本:
cd wenxin_appzoo/models_hub bash download_ernie_3.0_tiny_ch_all.sh $指定模型尺寸c. 反向传播阶段只更新学生模型参数,教师模型参数不更新;
-
TD2阶段:蒸馏预测层,产出最终的学生模型。
a. 热启动fine-tuned的教师模型和TD1阶段训练的学生模型;
b. loss包括两部分: 1) pred_loss:软标签,学生模型的预测层输出与教师模型的预测层输出的交叉熵; 2) student_ce_loss:硬标签,学生模型的预测层输出与真实label的交叉熵;
c. pred_loss与student_ce_loss之和作为最终loss,进行反向传播;
d. 反向传播阶段只更新学生模型参数,教师模型参数不更新;
注:关于GED阶段使用的通用数据:开发套件中的通用数据是由开源项目 https://github.com/brightmart/nlp_chinese_corpus 中的中文维基百科语料(wiki2019zh)经过预处理得到。该数据只用于demo展示,实际使用时替换为业务无标注数据效果提升更明显。
开始使用
常见问题
-
问题1:怎么修改学生模型的层数?上面提供了多种不同的学生模型,但每个学生模型的层数、hidden size等都是固定的,如果想更改,需要在哪些地方更改?
-
文心提供了三种不同结构的预训练学生模型,如果修改层数、hidden size等,会导致预训练学生模型参数无法加载,在此情况下,蒸馏出来的学生模型效果无法保证,建议用户还是使用文心提供的预训练模型,不更改模型结构;如果用户认为更改学生模型的结构非常有必要,需要对文心做以下改动:
-
修改TD1阶段json配置文件的pre_train_model配置项,删除预训练学生模型的加载,只保留微调后的教师模型:
"pre_train_model": [ # 热启动fine-tune的teacher模型 { "name": "finetuned_teacher_model", "params_path": "./output/cls_ernie_3.0_large_ft/save_checkpoints/checkpoints_step_6000" } ] -
将json文件中的"student_embedding"替换为自定义的学生模型
"student_embedding": { "config_path": "../../models_hub/ernie_3.0_tiny_ch_dir/ernie_config.json" }, - 再次强调,上述修改后,由于无法加载预训练学生模型,蒸馏出来的学生模型效果无法保证。(用户训练数据量到百万样本以上可以考虑尝试一下)
-
-