

9.Inference
更新时间:2022-07-27
简介
在文心中,我们把模型推理预测过程中常用的操作进行了统一封装、统一调度,形成一套标准流程,这套标准流程的调度就是Inference(预测器)。一个Inference实例中的标准操作有初始化运行环境、加载模型文件、数据读取(通过调用Reader实现)、预测推理、预测结果解析。
基本流程
一个Inference实例中包含了一个Reader实例和一个Paddle.Inference实例,Reader实例负责读取明文数据集并将其处理为飞桨可用的Tensor结构;Paddle.Inference实例对Reader传入的Tensor数据按加载的网络结构进行计算,并将计算结果返回给文心的Inference实例,Inference对结果进行 自定义解析回传给用户。其具体流程下所示:
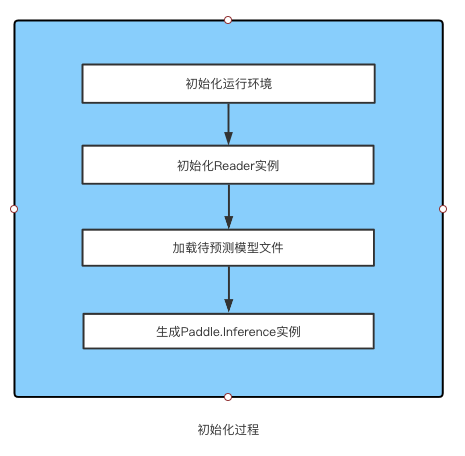
基础操作
以下以wenxin_appzoo/tasks/text_classification/,分类任务的预测为例。
-
批量预测:
def inference_batch(self): """ 批量预测 """ logging.info("start do inference....") total_time = 0 output_path = self.params.get("output_path", None) if not output_path or output_path == "": if not os.path.exists("./output"): os.makedirs("./output") output_path = "./output/predict_result.txt" output_file = open(output_path, "w+") dg = self.data_set_reader.predict_reader for batch_id, data_t in enumerate(dg()): data = data_t[0] samples = data_t[1] feed_dict = dg.dataset.convert_fields_to_dict(data) predict_results = [] for index, item in enumerate(self.input_keys): kv = item.split("#") name = kv[0] key = kv[1] item_instance = feed_dict[name] input_item = item_instance[InstanceName.RECORD_ID][key] # input_item是tensor类型,需要改为numpy数组 self.input_handles[index].copy_from_cpu(input_item.numpy()) wrap_load(self.input_handles, self.input_keys) begin_time = time.time() self.predictor.run() end_time = time.time() total_time += end_time - begin_time output_names = self.predictor.get_output_names() for i in range(len(output_names)): output_tensor = self.predictor.get_output_handle(output_names[i]) predict_results.append(output_tensor) # 回调给解析函数 write_result_list = self.parser_handler(predict_results, sample_list=samples, params_dict=self.params) for write_item in write_result_list: size = len(write_item) for index, item in enumerate(write_item): output_file.write(str(item)) if index != size - 1: output_file.write("\t") output_file.write("\n") logging.info("total_time:{}".format(total_time)) output_file.close() -
单样本预测:与批量预测的方式一样,不再赘述。
def inference_query(self, query): """单条query预测 :param query : list """ total_time = 0 reader = self.data_set_reader.predict_reader.dataset data, sample = reader.api_generator(query) feed_dict = reader.convert_fields_to_dict(data) predict_results = [] for index, item in enumerate(self.input_keys): kv = item.split("#") name = kv[0] key = kv[1] item_instance = feed_dict[name] input_item = item_instance[InstanceName.RECORD_ID][key] # input_item 是ndarray self.input_handles[index].copy_from_cpu(np.array(input_item)) wrap_load(self.input_handles, self.input_keys) begin_time = time.time() self.predictor.run() end_time = time.time() total_time += end_time - begin_time output_names = self.predictor.get_output_names() for i in range(len(output_names)): output_tensor = self.predictor.get_output_handle(output_names[i]) predict_results.append(output_tensor) # 回调给解析函数 result_list = self.parser_handler(predict_results, sample_list=sample, params_dict=self.params) return result_list
文心现有的预置Inference
文心目前的内置task中都提供了1个通用的Inference,覆盖了一些比较常见的NLP领域的经典任务,包括文本分类、文本匹配、序列标注、信息抽取等,位于各个task的inference目录下。
进阶使用
文心中提供了通用的Inference流程,如果用户需要针对自己的业务场景进行自定义优化使用的话,请参考详细的接口设计自定义Inference。