

ERNIE-Word
更新时间:2022-08-03
基本介绍
- ERNIE-Word是利用百度研发的先进中文预训练语言模型ERNIE产出的静态词向量。
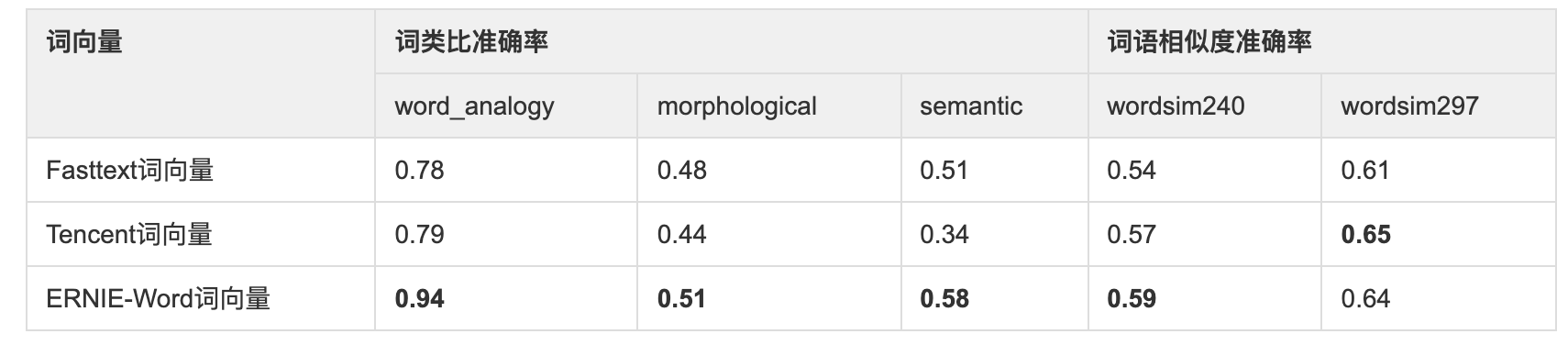
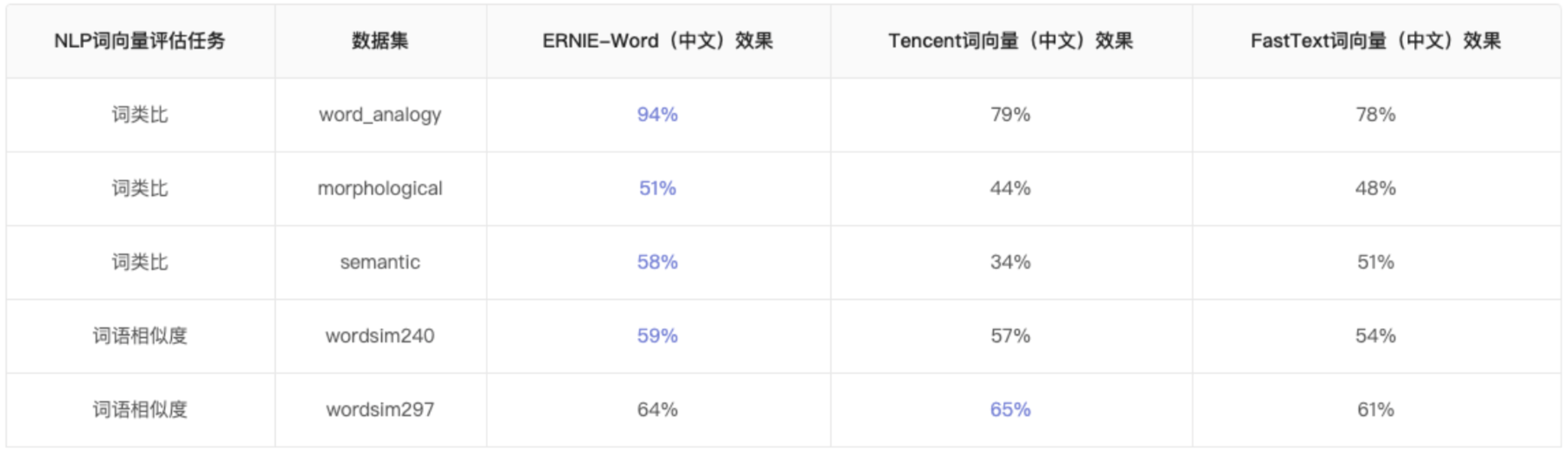
- 其充分利用ERNIE编码的丰富语义信息,将ERNIE与词向量训练相结合,产出了收敛更快、效果更好的静态词向量,在多个公开的词向量内部任务评价上达到业界领先的效果。详细对比如下表所示。
- ERNIE-Word在不同的NLP任务中均可以作为预训练词向量使用,有助于开发者提升模型效果,特别是浅层模型或训练数据量较少的情况下,建议使用预训练ERNIE-Word词向量,使用方式请参考文本分类(Text Classification)#通过ERNIE-Word进行文本分类。
- ernie_word的下载脚本位于./wenxin_app/models_hub/目录下,为download_ernie_word_ch.sh 执行下载脚本,会下载并生成对应的目录。
效果验证
- 我们选择公开的review情感分析数据进行实验,其中训练集仅3950条,较适合验证在训练数据量较少的情况下,使用预训练ERNIE-Word词向量带来的提升。通过重复5次实验,结果如下:
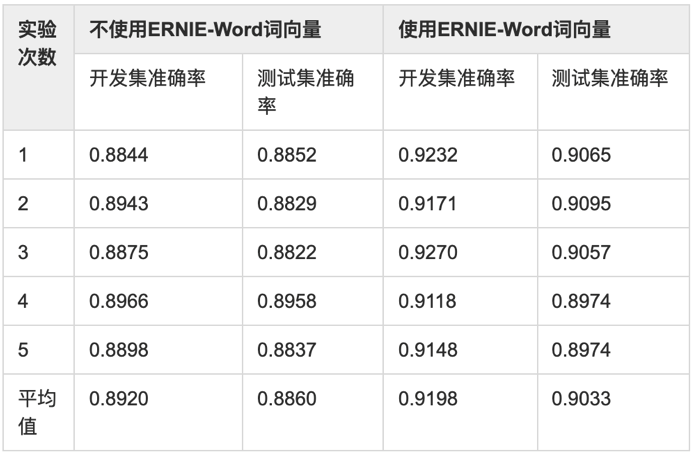
- 可以看到使用ERNIE-Word有较稳定的提升,在开发集上平均提升2.78%,在测试集上平均提升1.73%,因此建议开发者在训练数据量较少的情况下尝试使用预训练ERNIE-Word词向量。
- 模型效果
 注意事项
注意事项
使用ernie-word时,用户数据没有分词,可以使用ernie-tiny的分词工具进行分词(需提前在models_hub目录下下载ernie-tiny:sh download_ernie_tiny_1.0_ch.sh),json中关于tokenizer的配置如下:
"tokenizer": {
"type": "WSSPTokenizer",
"split_char": " ",
"unk_token": "[UNK]",
"params": {
"sp_model_dir": "../../models_hub/ernie_tiny_1.0_ch_dir/subword/spm_cased_simp_sampled.model",
"wordseg_dict": "../../models_hub/ernie_tiny_1.0_ch_dir/subword/dict.wordseg.pickle.2"
}
},
当用户数据不需要分词时(已分好词),json中关于tokenizer的配置如下
"tokenizer": {
"type": "CustomTokenizer",
"split_char": " ",
"unk_token": "[UNK]",
"params": null
},