ERNIE 3.0介绍
更新时间:2022-08-03
基本介绍
- 文心ERNIE开发套件提供ERNIE 3.0 Base 和 ERNIE 3.0 Large 中文通用模型。
-
ERNIE 3.0系列模型是针对ERNIE模型优化的最新版本,通过提出字词混合的自监督对比学习预训练技术和字词混合数据增强自对抗微调技术,使得模型在8个中文主流下游任务上获得了明显的效果提升。
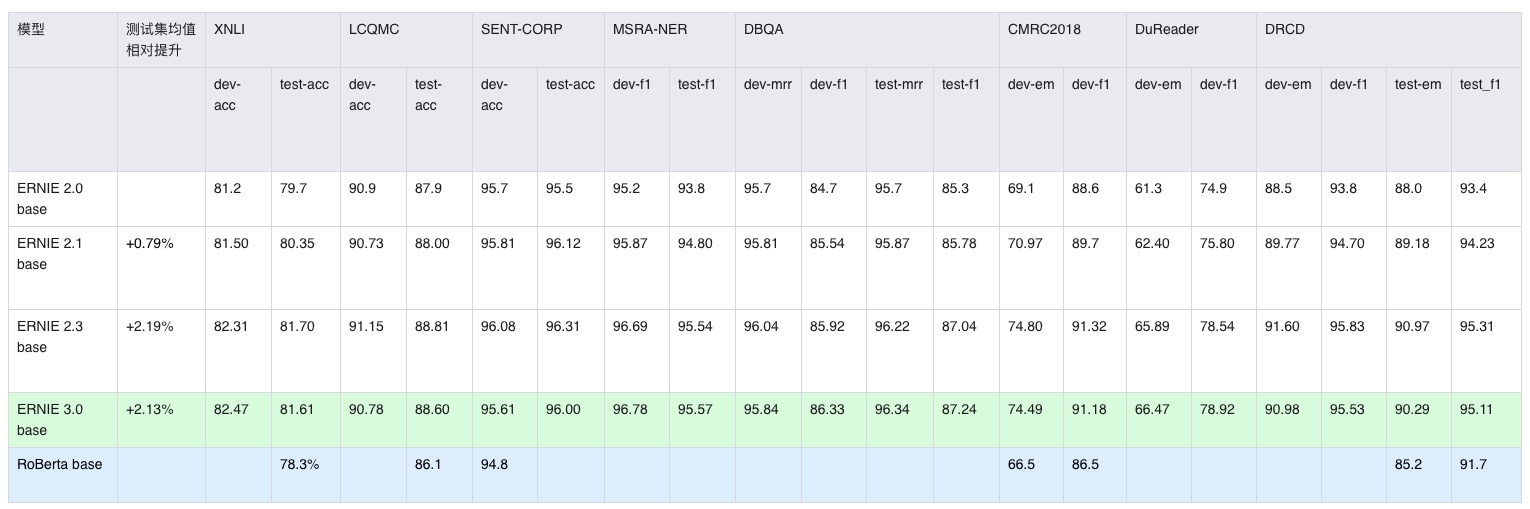
- Large模型:8个下游任务的平均性能相较于ERNIE 2.0 Large 提升2.30%。
- Base模型:8个下游任务的平均性能相较于ERNIE 2.0 Base 提升2.13%。
原理介绍
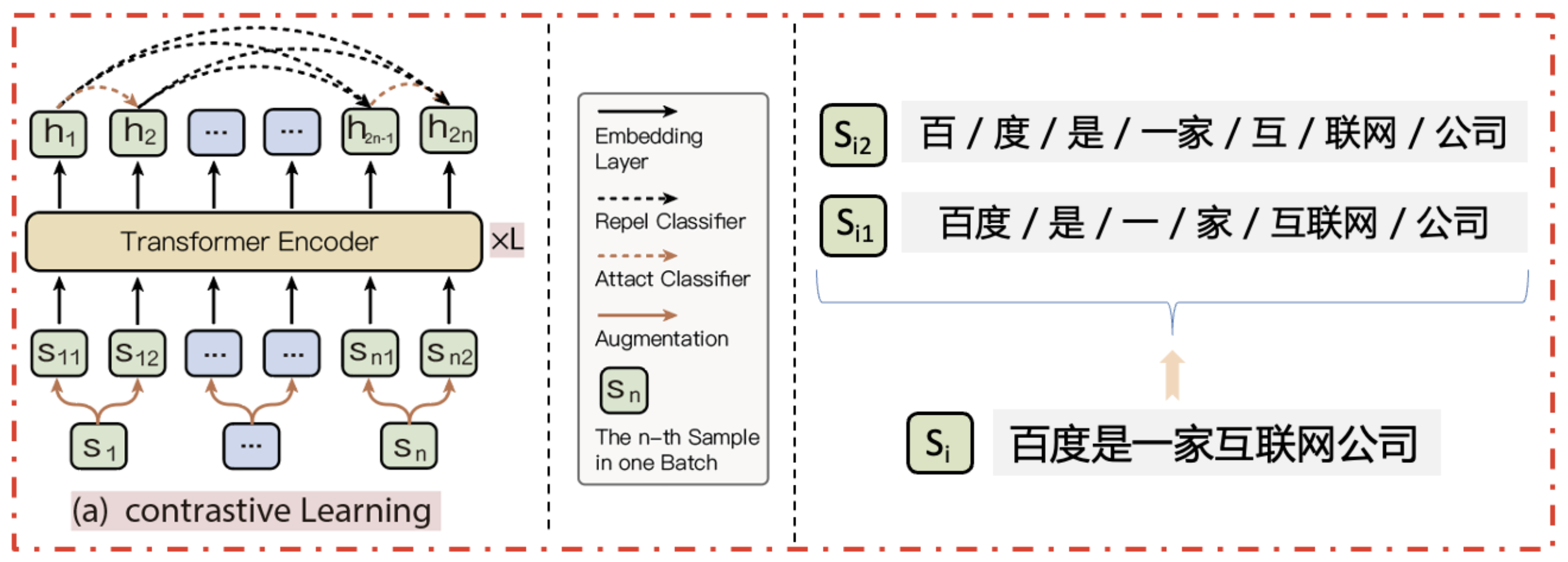
字词混合的自监督对比学习预训练技术 :
- 对比学习直接学习数据本身,能够探索数据结构信息来帮助模型学习,缓解传统模型训练策略对直接语义监督的依赖,提升模型鲁棒性和泛化能力。其可以应用于预训练阶段和finetune阶段,当前已将该任务适配至阅读理解任务、句对分类任务、句对匹配任务、单句分类任务和序列标注任务。
-
学术界当前对比训练中引入对比样本的方式分为两种:
- 通过增加、删除或者修改部分token的方式构建对比样本 —> 易改变原始文本的语义
- 利用dropout的随机性构建对比样本 –-> 不会原始文本的语义,但 却倾向于认为相同或相似长度的句子在语义上更相似
- 本策略 通过基于字词混合粒度切分构建对比样本同时解决了上述两个问题。如下图所示:
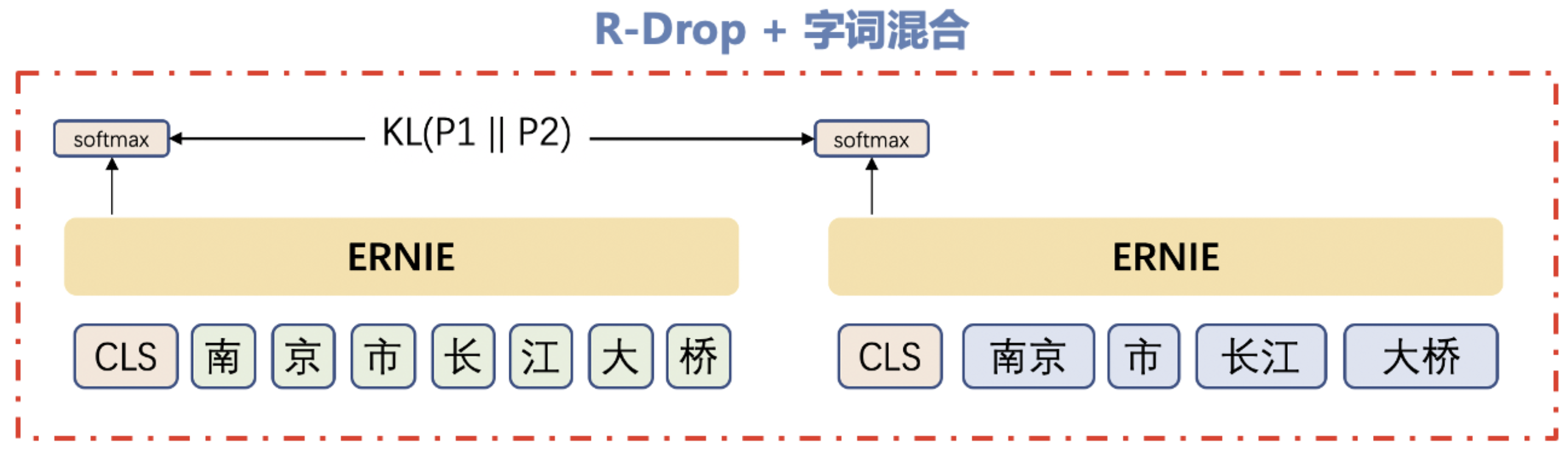
字词混合数据增强自对抗微调策略:
- 为了在微调阶段有效利用预训练中引入的词信息,在传统字词混合Finetune策略效果不佳的情况下,该策略是在通过dropout获取对抗样本的基础上引入字词混合粒度切分,该策略增强了对抗样本的随机性,还引入了词信息,是一种全新词信息使用方案
- 如图所示:
模型效果