(new)模型蒸馏-匹配任务
更新时间:2022-12-17
代码结构
任务代码位于:./wenxin_appzoo/tasks/model_distillation_cls
.
├── data
│ ├── download_general_data.sh
│ ├── download_task_data.sh
│ ├── predict_demo
│ ├── wiki_wenxin
│ └── xnli
├── examples
│ ├── xnli
├── inference
│ ├── custom_inference.py
├── model
│ ├── base_cls.py
│ ├── ernie_classification.py
│ ├── general_enhanced_distill_minilm.py
│ ├── task_distill_minilm.py
├── reader
│ ├── cls_field_reader.py
│ ├── ernie_classification_dataset_reader.py
├── run_infer.py
├── run_trainer.py
└── trainer
├── custom_dynamic_trainer.py开始使用
数据准备
使用xnli作为任务数据集,中文wiki百科作为通用数据集。
- 下载方式
cd ./wenxin_appzoo/tasks/model_distillation_cls/data
bash download_task_data.sh
bash download_general_data.sh分阶段运行
-
准备预训练教师模型和学生模型
cd wenxin_appzoo/models_hub bash download_ernie_3.0_large_distill_ch.sh bash download_ernie_3.0_tiny_ch.sh cd wenxin_appzoo/tasks/model_distillation_cls -
fine-tune 教师模型
python run_trainer.py --param_path ./examples/xnli/ernie_3.0_large_ft.json -
任务蒸馏通用数据增强阶段:GED
- 首先需要根据评估指标选择最优的fine-tuned教师模型,然后运行:
python run_trainer.py --param_path ./examples/xnli/minilm_ged.json -
任务蒸馏二阶段:TD1
python run_trainer.py --param_path ./examples/xnli/minilm_td1.json -
任务蒸馏二阶段:TD2
python run_trainer.py --param_path ./examples/xnli/minilm_td2.json -
对学生模型的效果进行预测
python run_infer.py --param_path ./examples/xnli/minilm_student_infer.json
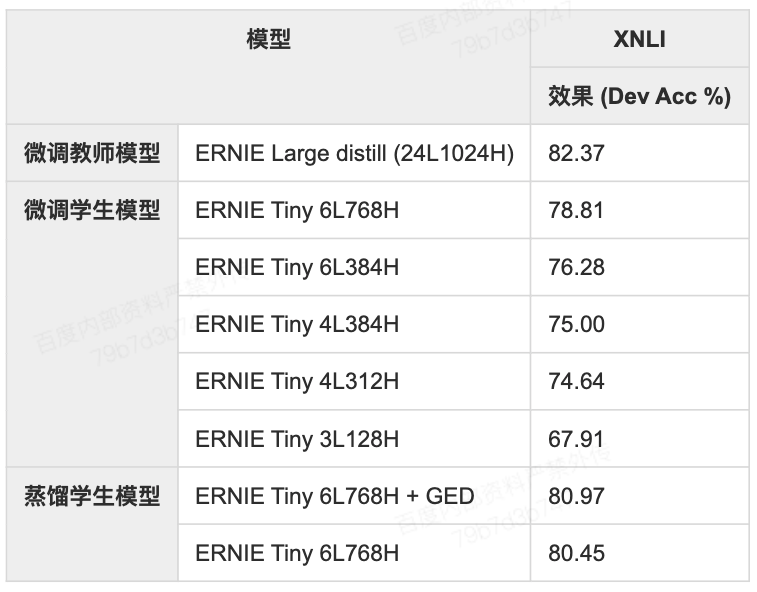
效果验证
- 教师模型与学生模型的微调 (fine-tune) 和蒸馏 (distill) 效果对比