

主动学习
更新时间:2022-12-17
任务简介
- 主动学习的目标:从大量的未标注数据中筛选出最有用的、最有意义的、最值得花人力的样本去给标注者标注,由此得到性能较好的模型。
- 主动学习标注流程:
- 用户数据准备:标注样本集L和无标注样本集U,无标注样本集为待标注数据。
- 主动学习模型:A=(C, Q, S, L, U)
其中C为一组或者一个分类器,L是用于训练已标注的样本。Q是查询函数,用于从未标注样本池U中查询最值得标注的数据,S是督导者(标注者),可以为U中未标注样本标注正确的标签。 - 具体流程:模型C通过少量初始标记样本L开始学习,通过查询函数Q选择出一个或一批最有用的样本,并交由督导者S进行标注,然后将标注好的样本填充到标注样本集,然后再利用获得的新知识来训练(可热启)分类器和进行下一轮查询。主动学习是一个循环的过程,直至达到某一停止准则(如标注样本个数达到一定值或模型效果达到需求)为止。
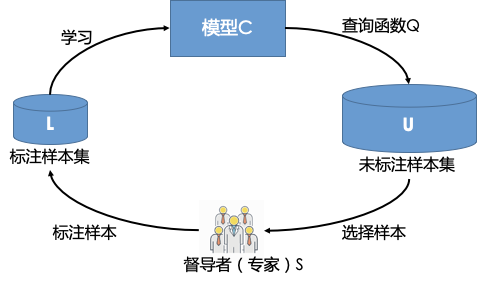
- 适用场景:数据收集成本较低、数据标注成本较高的场景。
主动学习策略
目前文心共提供三种主动学习策略,具体介绍如下:
-
Least Confident (LC):
- 原理:该策略筛选的目标为:模型预测概率最大但是可信度较低的样本数据,即对未标注数据进行预测,若该样本的最大概率比其余样本的最大概率要小,则认为该样本比其余样本更值得标注。
- 公式:
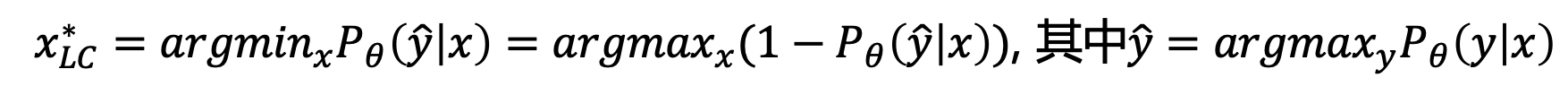
-
Margin:
- 原理:该策略筛选的目标:极容易被判定成两类的样本数据,或者说该样本的最大概率和第二大概率的差值较小,则认为该样本更值得标注。
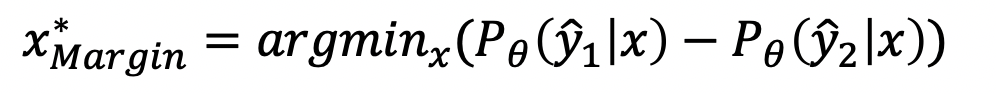
- 原理:该策略筛选的目标:极容易被判定成两类的样本数据,或者说该样本的最大概率和第二大概率的差值较小,则认为该样本更值得标注。
-
Discriminative Active Learning (DAL):
- 思想:假设大量的未标注数据可反映或者近似反映真实的数据分布,我们希望有标注数据也能尽可能的反映真实的数据分布,那就意味着希望有标注数据和未标注数据可表示同一个数据分布。
- 做法:DAL对有标注的样本打上标签0,未标注的样本打上标签1,使用二分类模型对标注好的样本进行训练,训练后对未标注样本进行预测,若未标注集样本以高置信度分为未标注集,意味该未标注样本和标注样本区别大,该样本信息多,标注集应该加入这个样本促使两者分布相似。其中可利用有标注数据学习到的样本的embedding作为二分类模型样本的输入特征。
- 参考论文:Gissin D, Shalev-Shwartz S. Discriminative active learning[J]. arXiv preprint arXiv:1907.06347, 2019.
- 其中序列标注任务中的LC和Margin策略的置信度为各token的置信度平均值(即结果不受序列长度的影响)。
快速开始
- 目前主动学习已支持文本分类和序列标注任务,已对ernie_fc_classification.py(文本分类)以及ernie_crf_sequence_label.py和ernie_fc_sequence_label.py(序列标注)进行修改,若想使用其他网络可参考上述网络保存预测模型时active_learning部分。
- 下面将以分类任务为例子进行说明。
模型训练
对有标注数据集L进行训练得到模型C
- 下载ernie预训练模型,以ernie_2.0_base为例:
# ernie_3.0_base_ch_dir 模型下载
# 进入models_hub目录下
# 运行下载脚本
sh ernie_3.0_base_ch_dir- 在text_classification目录下运行训练模型的脚本,其中json配置文件为./examples/cls_ernie_fc_ch_with_active_learning.json。
和cls_ernie_fc_ch.json对比,修改内容为在model字段中加入主动学习的字段,即:
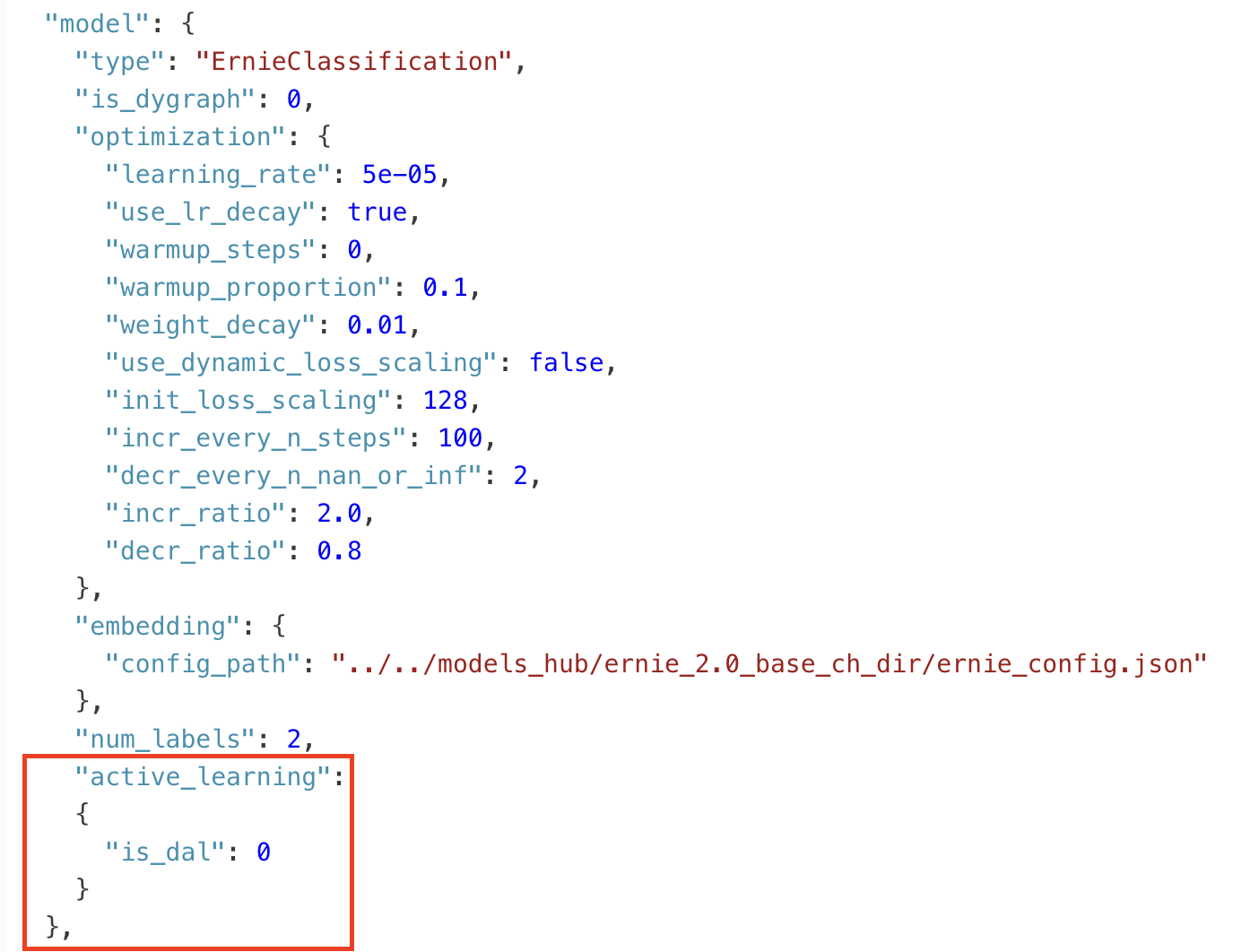
其中,若采用LC或Margin策略,则is_dal设为0,若采用DAL策略,该值设为1。 然后执行命令:
cd ../text_classification
python run_trainer.py --param_path ./examples/cls_ernie_fc_ch_with_active_learning.json.训练运行的日志会自动保存在./log/test.log文件中;
训练中以及结束后产生的模型文件会默认保存在./output/目录下,其中save_inference_model/文件夹会保存用于预测的模型文件,save_checkpoint/文件夹会保存用于热启动的模型文件。
模型预测
根据预测策略的不同,各预测配置文件不同,具体如下:
- LC/Margin策略 需未标注样本的各类别的预测概率值。 其中json配置文件: cls_ernie_fc_ch_infer_with_active_learning.json

- DAL策略
需已标注样本和未标注样本的样本特征(embedding),为此需分别对未标注数据和训练数据进行预测
a. 未标注数据预测配置 上述active_learning字段修改为:
"active_learning":
{
"is_dal": 1,
"emb_size": 768
},b.
训练数据预测配置
可参考:
cls_ernie_fc_ch_train_with_dal_infer.json
其中和未标注数据的预测配置文件的区别在于
i.
reader中加入label字段的配置;
ii.
待预测数据为训练集;
iii.
预测结果输出文件。
3.开始预测:
a.LC/Margin策略
python run_infer_with_active_learning.py --param_path ./examples/cls_ernie_fc_ch_infer_with_active_learning.jsonb.DAL策略
# 对未标注数据进行预测
python run_infer_with_active_learning.py --param_path ./examples/cls_ernie_fc_ch_infer_with_active_learning.json
# 对标注数据进行预测
python run_infer_with_active_learning.py --param_path ./examples/cls_ernie_fc_ch_train_with_dal_infer.json主动学习查询待标注数据
进入主动学习目录:
cd ../../tools/data/hard_sample/代码结构:
├── config ## 主动学习策略配置文件
│ ├── sequence_labeling.yml ## 序列标注任务配置文件
│ └── text_classification.yml ## 文本分类任务配置文件
├── hard_sample_job.py ## 主动学习策略的入口脚本
├── __init__.py
└── strategies ## 主动学习策略代码
├── dal_strategy.py ## DAL策略
├── hard_sample_strategy.py ## 主动学习策略基类
├── __init__.py
├── lc_strategy.py ## LC策略
├── margin_strategy.py ## Margin策略
└── sequence_label_strategy.py ## 序列标注策略(调用LC和Margin策略)开始查询
- 修改配置文件 以./config/text_classification.yml进行字段说明:
hard_sample_num_config: ## 待挑选难例样本的个数设置
mode: num ## 分别有num模式和ratio模型,num模式为返回value值个数的最值得标注的数据,ratio模式返回的样本个数为总未标注样本数*value。
value: 200
DAL: ## DAL二分类网络配置
iteration: 5
mlp_hidden_layer_sizes:
- 256
- 256
- 256
mlp_max_iter: 10- 执行主动学习策略进行查询
python hard_sample_job.py [--task] [--fun] [--predict_file] [--train_predict_file]脚本接口参数说明
usage: hard_sample_job.py [--task] [--fun] [--predict_file] [--train_predict_file]
## task: 任务名称
## fun: 主动学习策略
## predict_file: 待挑选数据的预测文件
## train_predict_file: 若为DAL策略需提供训练数据的预测文件 - 主动学习策略结果保存在./hard_sample_result目录下,结果共三列,以\t分割,分别为文本、难例的权重(权重越大越值得标注,结果已排好序)和训练模型预测出的标签,具体如下所示:

- 效果评估
| 文本分类 | 序列标注 | |
|---|---|---|
| 数据集 | chnsenticorp | MSRA-NER |
| 启动条件 | 每个标签的样本数为50 | 每个标签的标注数至少为500 |
| 新增数量 | 每次采用主动学习策略新增200条数据 | 每次采用主动学习策略新增200条数据 |
效果:DAL策略效果较差,LC/Margin策略可实现只需标注30%左右的数据可达到全量数据的效果。
5.注意事项
因Margin默认加入阈值限制,认为如果top1标签的概率值大于0.65时则不认为是难例,因此在模型较好的情况下的难例分值多为0,与随机效果无区别,可删掉该阈值限制进行评测,具体可参考tools/data/hard_sample/strategies/margin_strategy.py。