

ERNIE 3.0-10B
ERNIE 3.0
简介
ERNIE 3.0 (Large-Scale Knowledge Enhanced Pre-Training for Language Understanding And Generation) 是基于知识增强的多范式统一预训练框架。在ERNIE 3.0中,自回归和自编码网络被创新型地融合在一起进行预训练,其中自编码网络采用ERNIE 2.0的多任务学习增量式构建预训练任务,持续的进行语义理解学习。 通过新增的实体预测、句子因果关系判断、文章句子结构重建等语义任务。同时,自编码网络创新性地增加了知识增强的预训练任务。自回归网络基于Tranformer-XL结构,支持长文本语言模型建模。多范式的统一预训练模式使得ERNIE 3.0能够在理解任务、生成任务和零样本学习任务上获取SOTA的表现。
ERNIE 3.0论文链接地址:https://arxiv.org/pdf/2107.02137.pdf
技术原理
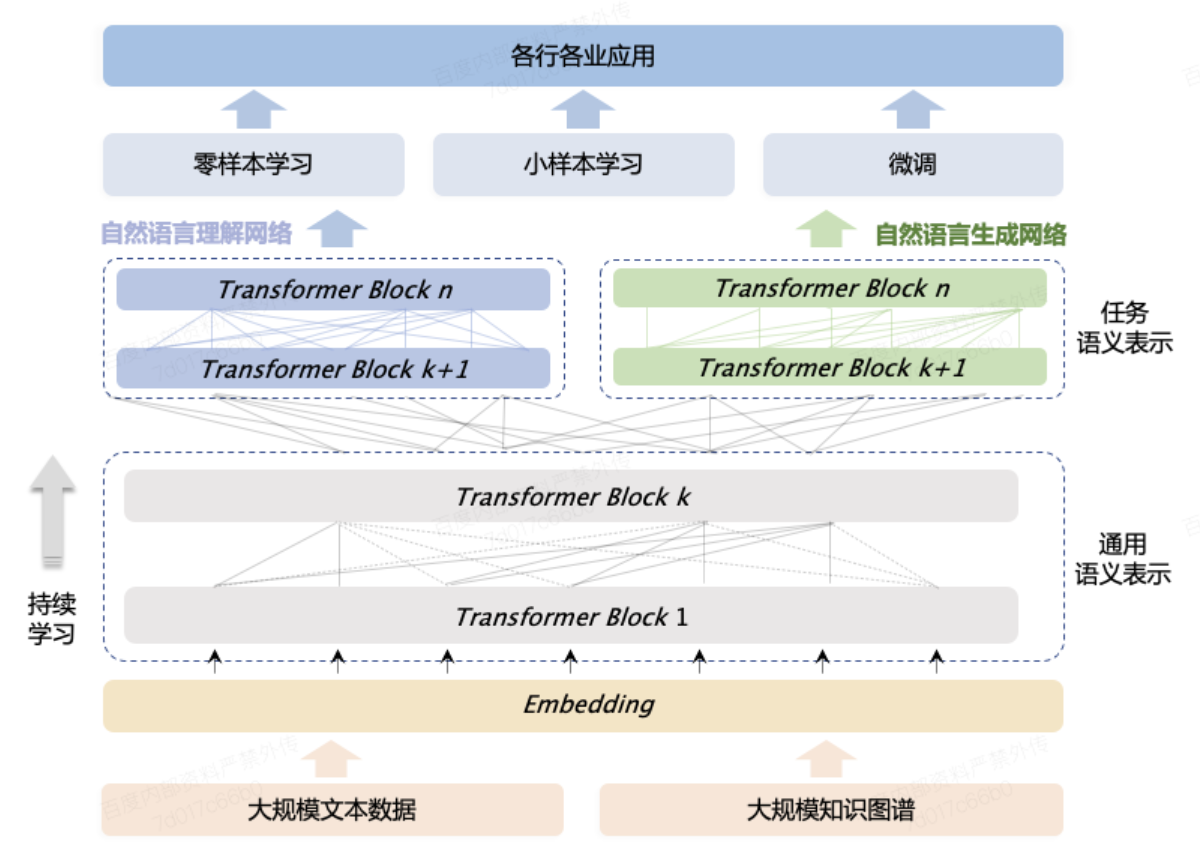
传统的大规模pre-training 模型主要基于纯文本数据进行预训练,忽略了常识知识或世界知识等信息,此外,目前绝大多数的大规模预训练语言模型均是基于自回归网络进行预训练,并在zero-shot/few-shot任务上展现了很强的能力,但却无法很好地处理传统的Finetune任务。为了解决上述问题,在ERNIE 3.0中,提出了一个多范式统一的大规模预训练框架,基于该框架,ERNIE 3.0融合了自回归网络和自编码网络,同时由于大规模知识图谱类数据的引入,使得模型能够在理解任务、生成任务、零样本学习任务和常识推理任务上均获取优秀的表现。基本框架如下图所示,核心特点是多范式统一训练和通用知识文本预测:
-
多范式统一预训练
多范式统一预训练即是基于同一个网络进行多种自然语言处理学习范式的统一学习,例如自然语言理解和自然语言生成的统一学习。我们相信不同的任务范式所需要的底层抽象语义信息是相同的,例如词汇和语法信息,但是顶层的具象信息确实不同的,例如,自然语言理解更倾向于学习semantic coherence,而自然语言生成则需要进一步的上下文信息。因此通过设置通用语义表示结构和任务特定表示结构进行多范式的统一预训练。
-
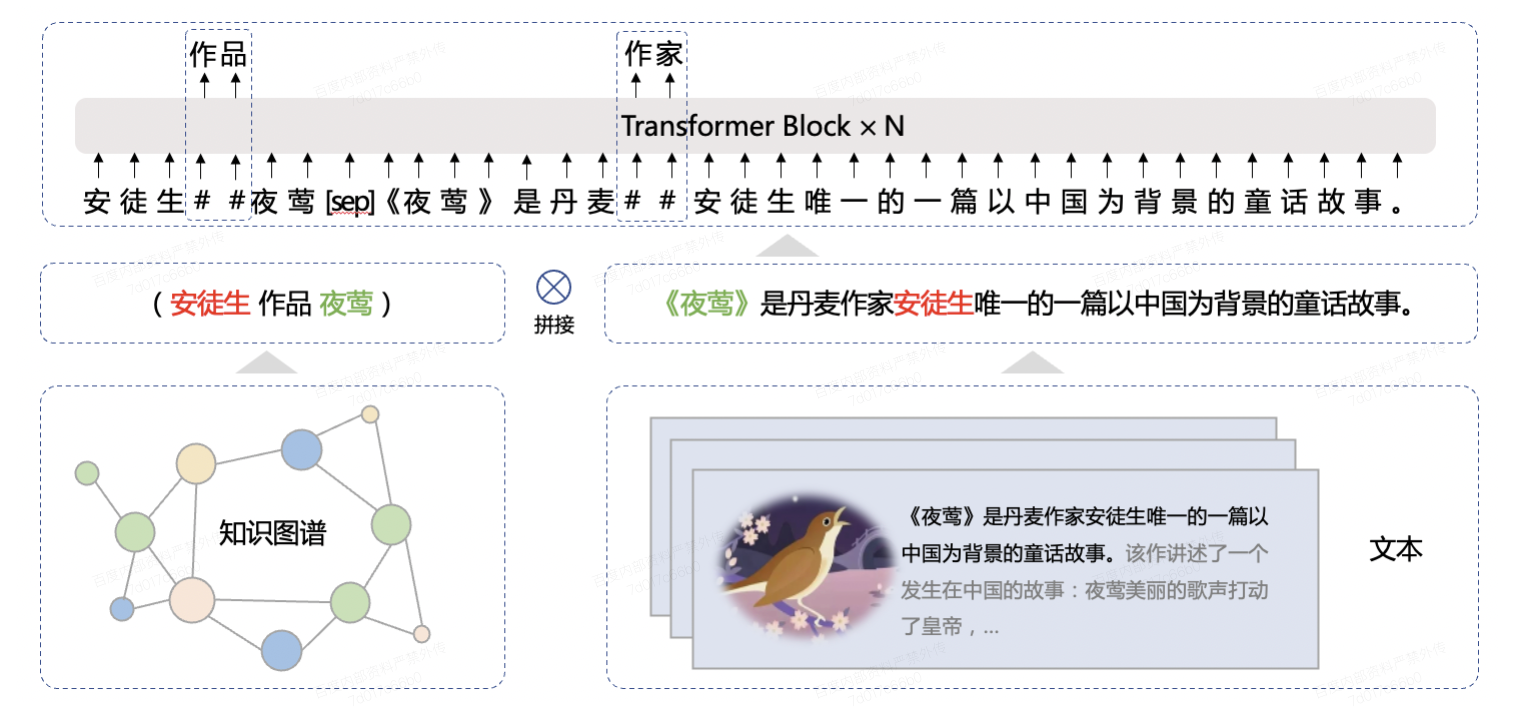
通用知识文本预测
通用知识文本预测是基于知识的MLM任务的扩展,特殊之处在于,需要基于知识图谱数据mask实体与实体之间的关系,如下图所示:
模型效果
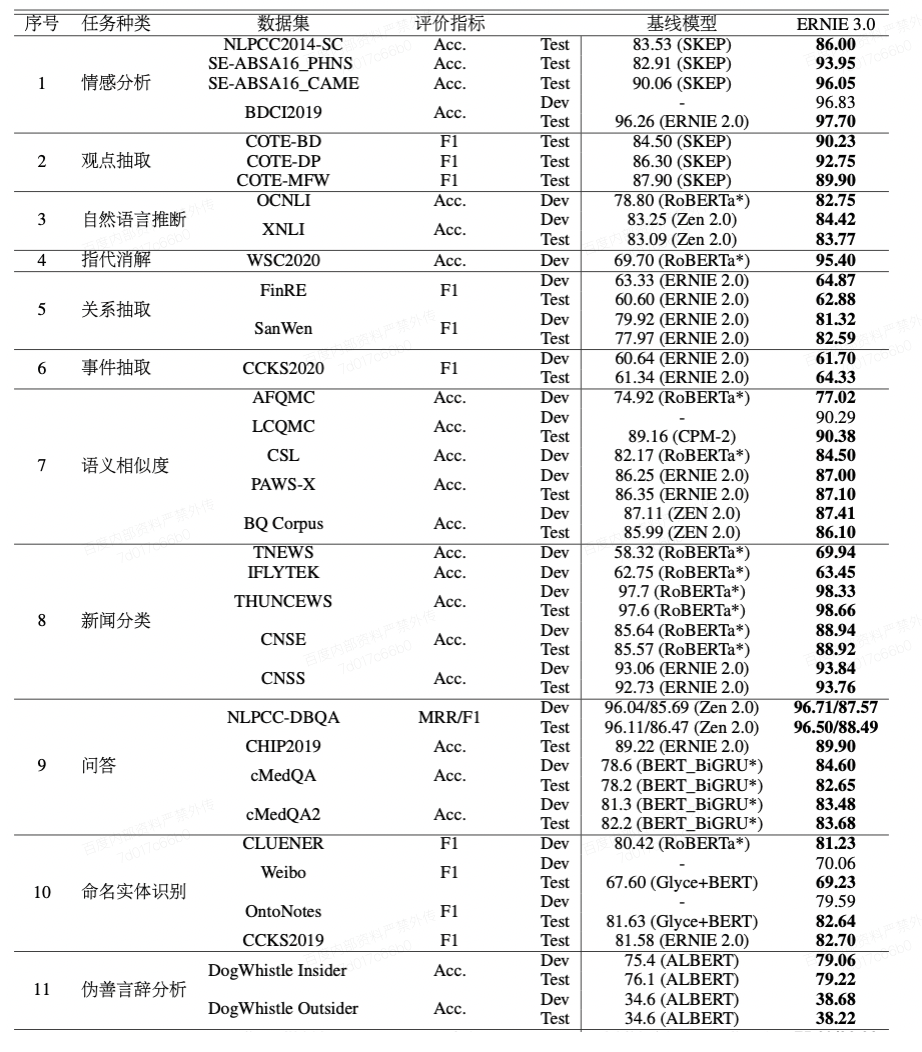
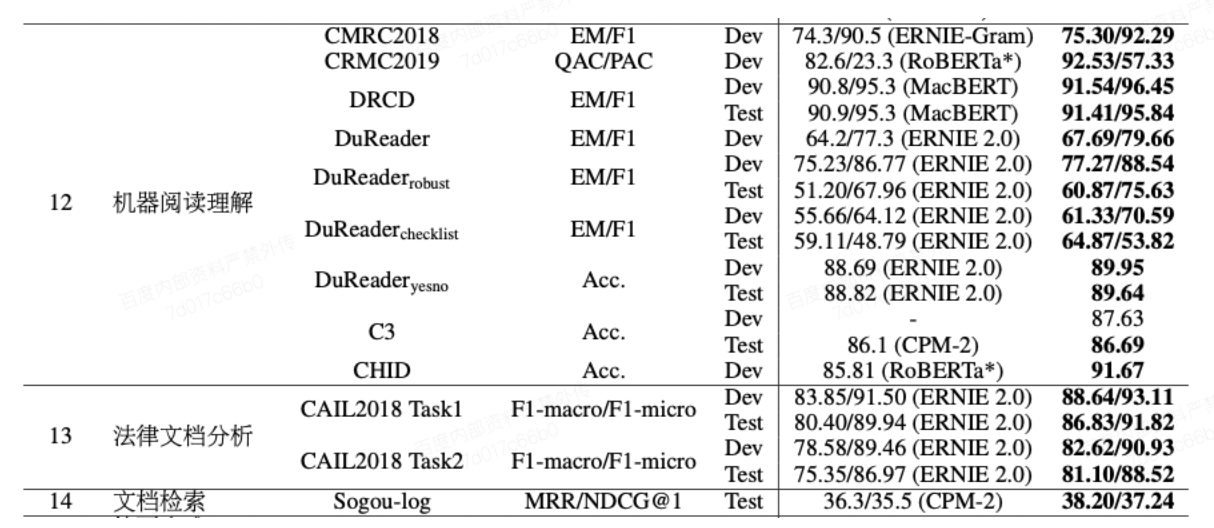
- ERNIE 3.0在14种类型共计45个自然语言理解数据集上取得了SOTA的结果
- ERNIE 3.0在9个自然语言生成任务上取得了SOTA的效果
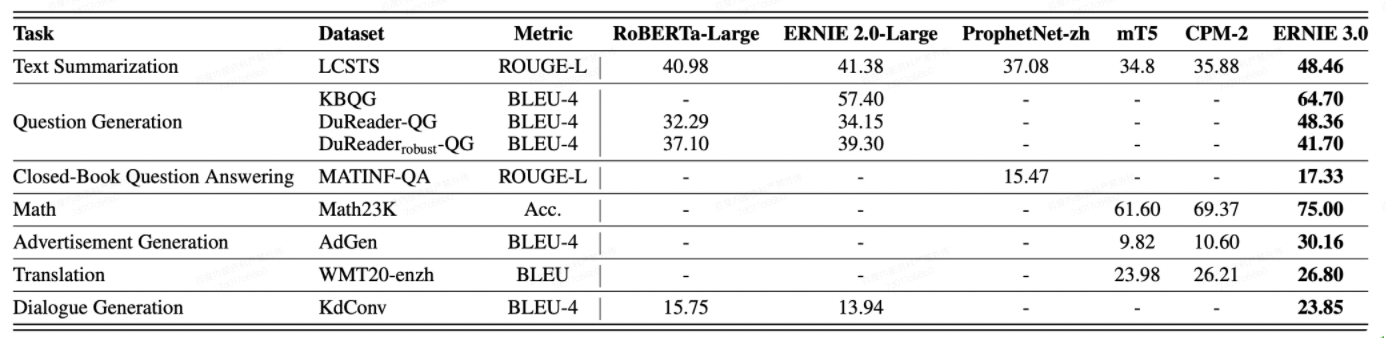
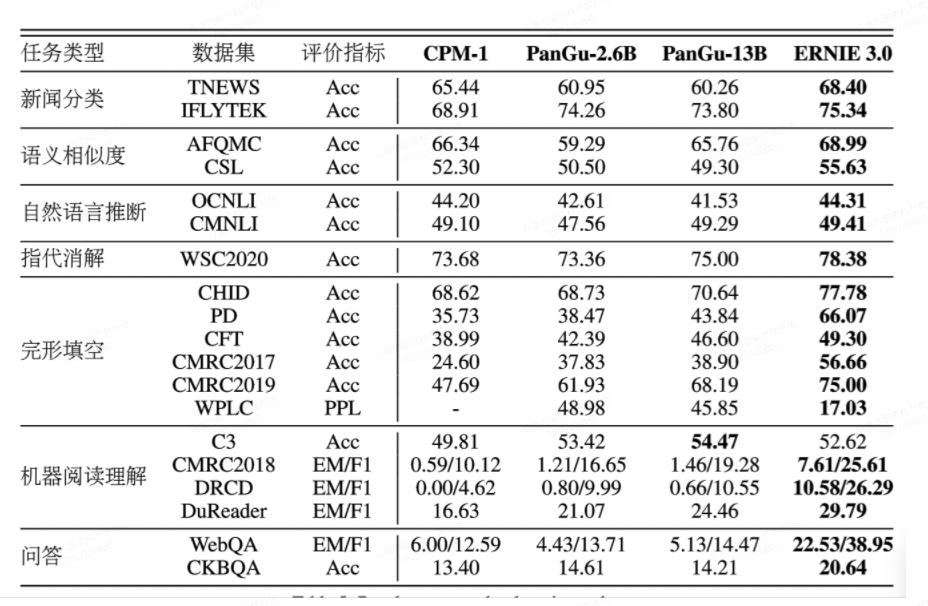
- ERNIE 3.0在18个数据集上刷新了zero-shot的SOTA效果
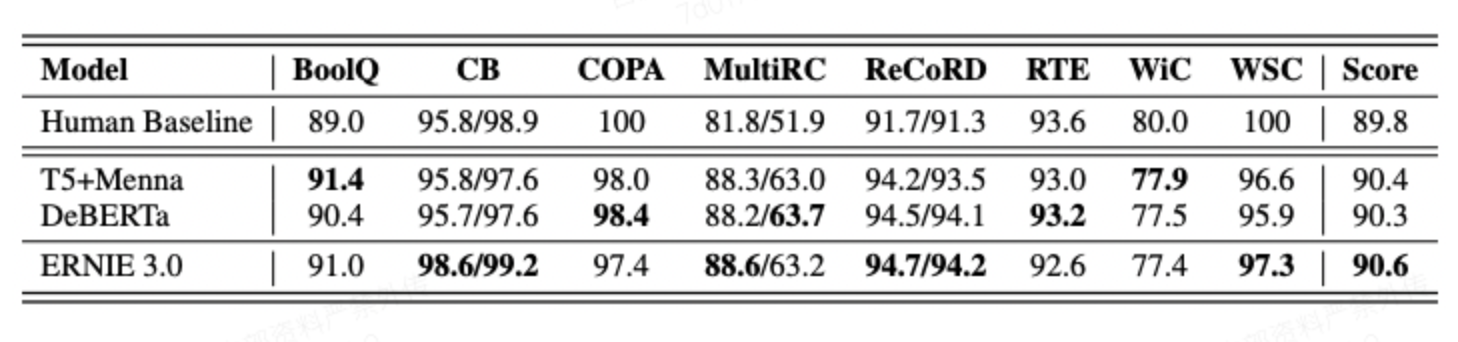
- ERNIE 3.0 在SuperGLUE上的效果
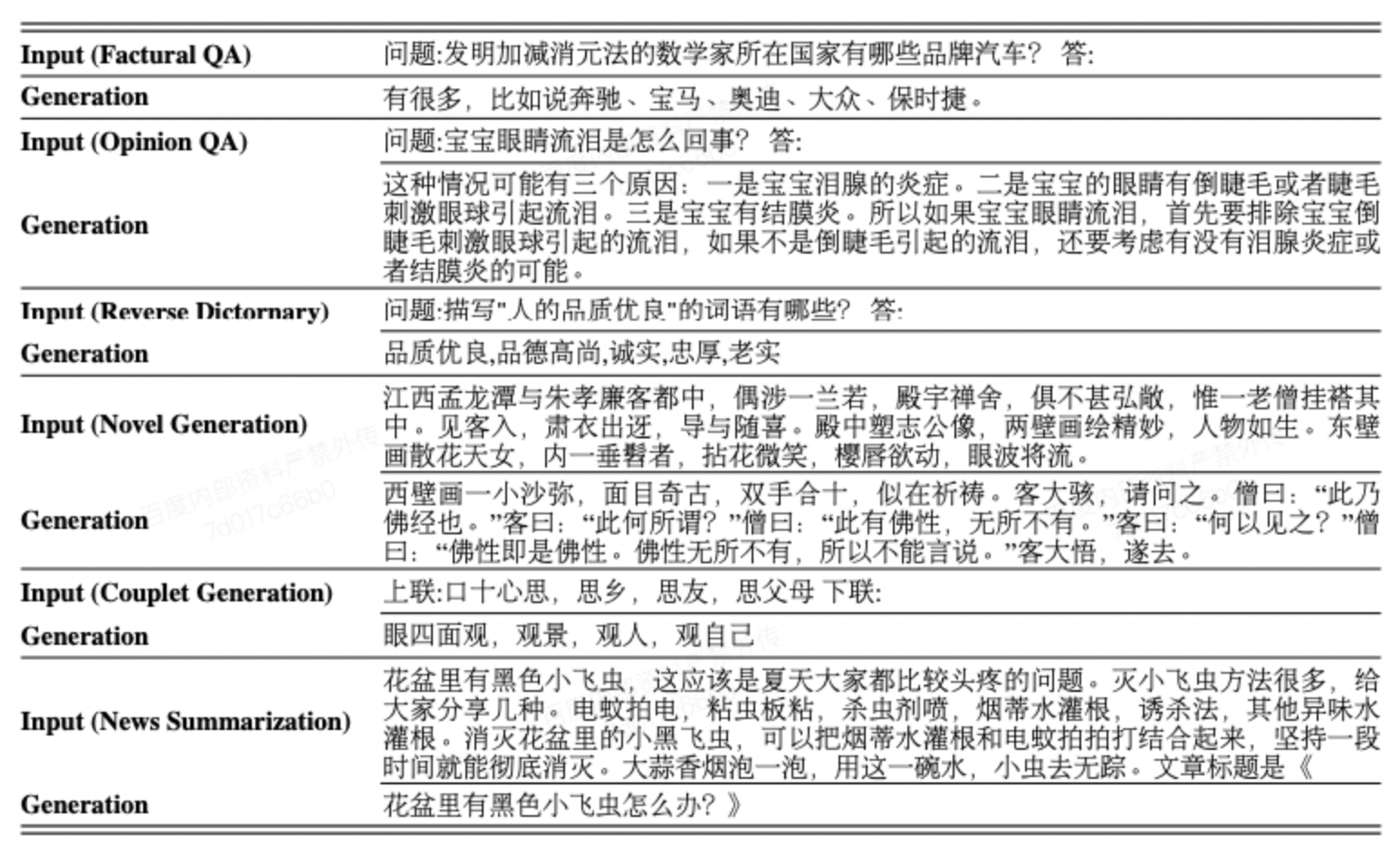
- ERNIE 3.0 文本生成能力展示
文心中ERNIE 3.0-10B的支持
目前文心提供ERNIE 3.0 百亿规模的中文模型。ERNIE 3.0 中文模型模型结构不同于之前的ERNIE 1.0 / ERNIE 2.0,基于Transformer-XL结构,并带有NLU和NLG的双分支结构。ERNIE 3.0的模型下载脚本位于./wenxin_appzoo/models_hub/目录下,为download_ernie_3.0_ch.sh。执行下载脚本,会下载并生成对应的目录,其中包含模型参数文件、词表文件、网络配置文件、模型版本信息文件 。
- ERNIE 3.0百亿模型是ERNIE系列的首个大规模版本,较之其他版本效果更优,但性能消耗更大,Finetune任务至少需要8卡32G V100,Inference任务至少需要单卡32G V100,模型结构分为48层通用表示层(词向量维度为4096维)和两个12层任务特定层(词向量维度为768维)。