

ERNIE-ViL 2.0介绍
ERNIE-ViL 2.0 基于多视角对比学习的跨模态预训练模型
介绍
多模态语义理解是人工智能领域重要研究方向之一,如何让机器像人类一样具备理解和思考的能力,需要融合语言、语音、视觉等多模态的信息。近年来,视觉、语言、语音等单模态语义理解技术取得了重大进展。但更多的人工智能真实场景实质上同时涉及到多个模态的信息。例如,理想的人工智能助手需要根据语言、语音、动作等多模态的信息与人类进行交流,这就要求机器具备多模态语义理解能力。 基于交互结构(cross encoder)的跨模态预训练模型(如ViLBERT、ERNIE-ViL等)在诸多的跨模态任务上取得了很大的效果提升,尤其在如视觉常识推理等复杂的跨模态任务上提升更大。但模态间的交互注意力机制(cross-modal attention)带来大量的计算代价,在大规模跨模态检索等线上系统中的应用面临巨大的挑战。近期,基于对比学习的双塔预训练框架(dual encoder)能够充分利用大规模图文对齐数据,在跨模态检索等任务上展现出较大的效果提升,同时,由于计算效率高,受到了广泛的关注。 传统的视觉-语言预训练技术基于单视角的对比学习,无法学习多种模态间和模态内的关联性,ERNIE-ViL 2.0提出了一种基于多视角对比学习的预训练框架,通过构建丰富的视觉/文本视角,能够同时学习模态间和模态内的多种关联性,从而学习到更鲁棒的跨模态对齐,在跨模态检索等任务上取得了SOTA。
原理
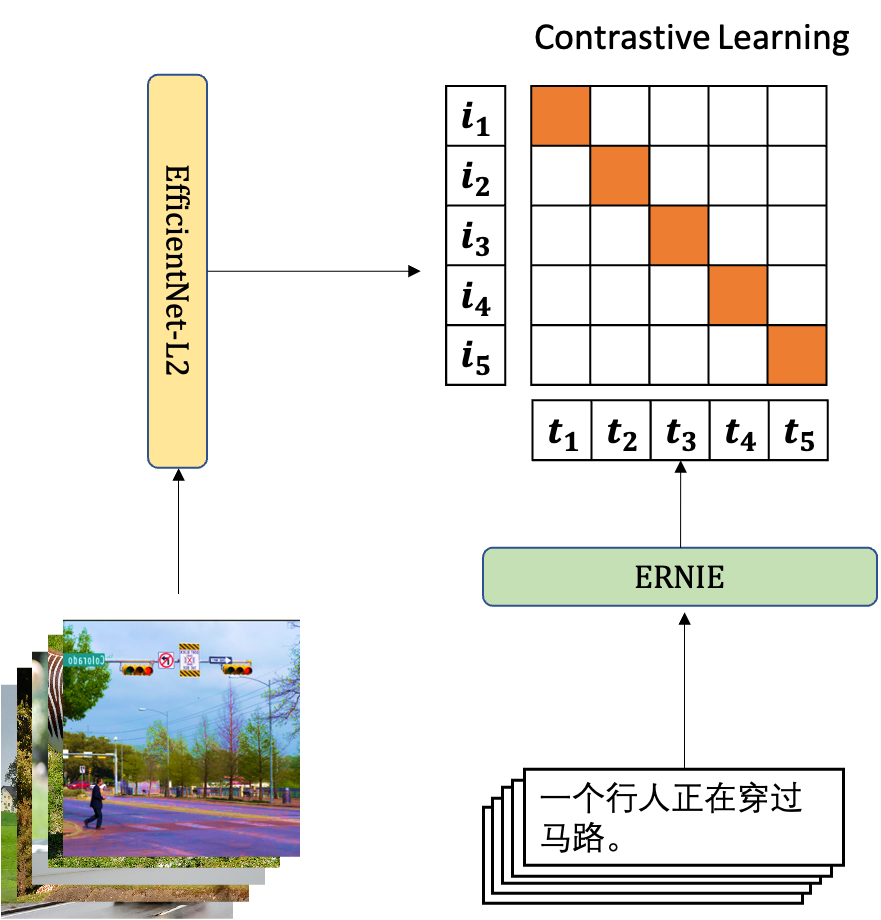
ERNIE-ViL 2.0,图像端encoder使用EfficientNet-L2, 文本端使用ERNIE2.0-large模型。基于多视角对比学习,在大规模的网络无监督数据上进行训练,在中英文多个跨模态检索任务上取得了巨大的效果提升,其中,在中文公开数据集COCO-CN和AIC-ICC取得SOTA。
效果
公开数据集
| 模型 | COCO-CN图文检索(mean Recall) | AIC-ICC |
|---|---|---|
| UC2 | 84.60 | |
| wenlan | 31.13 | |
| ERNIE-ViL 双塔 | 80.85 | |
| ERNIE-ViL 2.0 | 89.04 | 33.81 |
自建中文数据集
| 模型 | 图文相似度-图文广告数据集(% of AUC) | 图文相似度-nlp自建数据集(% of AUC) | sohu图文检索(mean Recall) | 视频主题分类(Mean F1) |
|---|---|---|---|---|
| ERNIE-ViL 双塔 | 81.86 | 89.63 | 59.02 | 79.08 |
| ERNIE-ViL 2.0 | 85.78 | 91.14 | 74.73 | 82.70 |
文心中的支持
见跨模态检索任务。