

8.Trainer
简介
在文心中,我们把模型训练过程中常用的操作进行了统一封装、统一调度,形成一套标准流程,这套标准流程的调度就是Trainer(训练器)。一个Trainer实例中的标准操作有初始化运行环境、初始化各项参数、构造神经网络(通过调用Model实现)、数据读取(通过调用Reader实现)、模型训练、模型效果评估、模型保存等。
基本结构
一个Trainer实例中包含一个Reader和Model的实例,Reader实例负责读取明文数据集并将其处理为飞桨可用的Tensor结构;Model实例负责构建神经网络、确定模型指标计算。Trainer实例在train方法(模型训练)中启动一个循环,不断的调用Reader获取数据、然后将数据传递到Model的网络结构中进行计算,并根据用户对模型评估频率和保存频率参数的设置,在指定的时机进行模型评估和模型保存,直到整个训练任务结束。其结构如下所示:
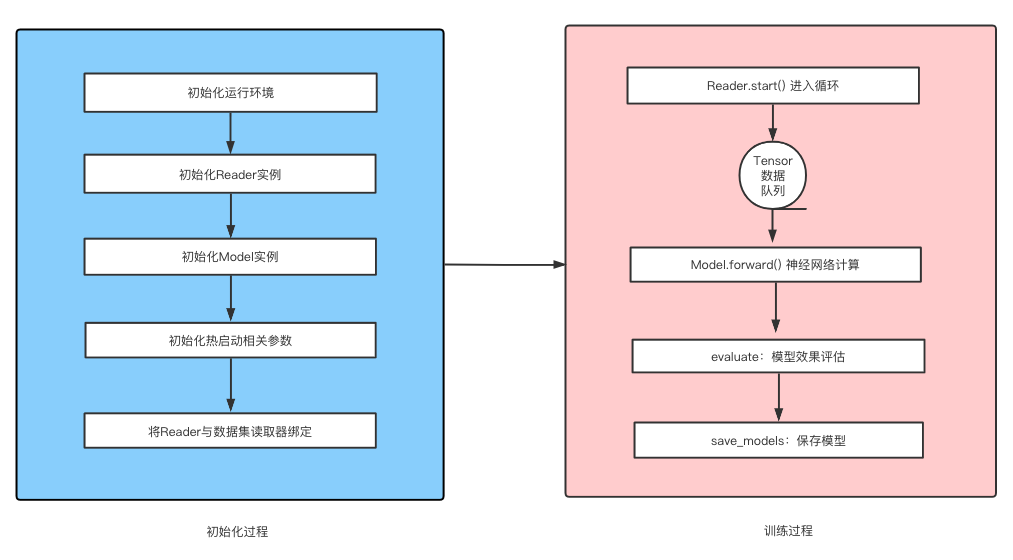
基础操作
Trainer的基类为BaseStaticTrainer和BaseDynamicTrainer,分别定义在 ./wenxin/controller/static_trainer.py 和 ./wenxin/controller/dynamic_trainer.py中。BaseDynamicTrainer为动态图模式的Trainer基类,BaseStaticTrainer为静态图模式的Trainer基类。
BaseStaticTrainer
- 运行环境初始化:根据当前用户的安装环境,初始化飞桨的运行时环境。这部分的代码在基类中已经实现,用户无需自己编码实现,仅需要配置好对应的参数即可,参数定义详见实战演练:使用文心进行模型训练。
-
构造神经网络:调用Model实例的forward和set_optimizer完成神经网络的构造,这部分的代码在基类中已经实现,部分代码如下所示。用户无需自定义编码实现。关于Model介绍请移步Model。
def init_static_model_net(self): """ 初始化神经网络 """ .... self.data_set_reader.train_reader.dataset.create_reader() fields_dict = self.data_set_reader.train_reader.dataset.instance_fields_dict() ## 构造神经网络 self.model_class.structure() self.forward_train_output = self.model_class.forward(fields_dict, phase=InstanceName.TRAINING) loss = self.forward_train_output[InstanceName.LOSS] self.model_class.set_optimizer() if self.use_fleet: self.optimizer = fleet.distributed_optimizer(self.model_class.optimizer) else: self.optimizer = self.model_class.optimizer self.optimizer.minimize(loss) .... -
模型训练:启动训练任务,不断通过Reader读取数据集,送入Model中进行计算,并得到评估结果,直到循环结束。这部分的代码在基类中只是定义了虚方法,需要用户继承来自定义实现。文心目前在每个task中提供了通用的CustomTrainer类(wenxin_appzoo/tasks/xxx/trainer/custom_trainer.py),能够覆盖大部分训练评估流程,用户如果对自定义训练评估要求不高,可以直接使用,部分代码如下所示:
def do_train(self): """ 启动数据集循环,开始训练 :return: """ .... dg = self.data_set_reader.train_reader steps = 1 time_begin = time.time() # 开始迭代训练集数据 for batch_id, data in enumerate(dg()): feed_dict = self.data_set_reader.train_reader.dataset.convert_input_list_to_dict(data) if steps % self.params["train_log_step"] != 0: if self.use_fleet: self.train_exe.run(program=self.train_program, feed=feed_dict, fetch_list=[], return_numpy=True) else: self.train_exe.run(feed=feed_dict, fetch_list=[], return_numpy=True) else: if self.use_fleet: fetch_output = self.train_exe.run(program=self.train_program, feed=feed_dict, fetch_list=self.fetch_list_train, return_numpy=True) else: fetch_output = self.train_exe.run(feed=feed_dict, fetch_list=self.fetch_list_train, return_numpy=True) fetch_output_dict = collections.OrderedDict() for key, value in zip(self.fetch_list_train_key, fetch_output): if key == InstanceName.LOSS and not self.return_numpy: value = np.array(value) fetch_output_dict[key] = value time_end = time.time() used_time = time_end - time_begin meta_info = collections.OrderedDict() meta_info[InstanceName.STEP] = steps meta_info[InstanceName.GPU_ID] = self.gpu_id meta_info[InstanceName.TIME_COST] = used_time # 调用model中的get_metrics方法进行效果评估计算。 metrics_output = self.model_class.get_metrics(fetch_output_dict, meta_info, InstanceName.TRAINING) if self.model_class.lr_scheduler: # 这一步一定要有,没有的话lr_scheduler不会生效,学习率一直为0 self.model_class.lr_scheduler.step() # 在合适的step对验证集和测试集进行评估 if steps % self.params["eval_step"] == 0: if self.params["is_eval_dev"]: self.do_evaluate(self.data_set_reader.dev_reader, InstanceName.EVALUATE, steps) if self.params["is_eval_test"]: self.do_evaluate(self.data_set_reader.test_reader, InstanceName.TEST, steps) if self.trainer_id == 0: # 在合适的时候进行模型保存 if steps % self.params["save_model_step"] == 0: self.save_model(steps) steps += 1 if self.params["is_eval_dev"]: logging.info("Final evaluate result: ") metrics_output = self.do_evaluate(self.data_set_reader.dev_reader, InstanceName.EVALUATE, steps) self.eval_metrics = metrics_output if self.params["is_eval_test"]: logging.info("Final test result: ") self.do_evaluate(self.data_set_reader.test_reader, InstanceName.TEST, steps) if self.trainer_id == 0: self.save_model(steps) -
模型评估:启动待测试数据集对应的Reader,从Reader中读取数据集,送入Model中进行计算,得到每个batch的计算结果并保存,直到循环结束。将所有batch的计算结果汇总起来传入Model的get_metrics方法进行整个评估数据集上的指标计算。这部分的代码在基类中只是定义了虚方法,需要用户继承来自定义实现。文心目前提供了通用的CustomTrainer类(wenxin_appzoo/tasks/xxx/trainer/custom_trainer.py),能够覆盖大部分训练评估流程,用户如果对自定义训练评估要求不高,可以直接使用,部分代码如下所示:
def do_evaluate(self, reader, phase, step): """在当前的训练状态下,对某个测试集进行评估 :param reader:待评估数据集 :param phase:当前的运行阶段 :param step:当前的运行步数 """ all_metrics_tensor_value = [] i = 0 time_begin = time.time() for batch_id, data in enumerate(reader()): feed_dict = reader.dataset.convert_input_list_to_dict(data) metrics_tensor_value = self.executor.run(program=self.test_program, feed=feed_dict, fetch_list=self.fetch_list_evaluate, return_numpy=True) if i == 0: all_metrics_tensor_value = [[tensor] for tensor in metrics_tensor_value] else: for j in range(len(metrics_tensor_value)): one_tensor_value = all_metrics_tensor_value[j] all_metrics_tensor_value[j] = one_tensor_value + [metrics_tensor_value[j]] i += 1 fetch_output_dict = collections.OrderedDict() for key, value in zip(self.fetch_list_evaluate_key, all_metrics_tensor_value): if key == InstanceName.LOSS and not self.return_numpy: value = [np.array(item) for item in value] fetch_output_dict[key] = value time_end = time.time() used_time = time_end - time_begin meta_info = collections.OrderedDict() meta_info[InstanceName.STEP] = step meta_info[InstanceName.GPU_ID] = self.gpu_id meta_info[InstanceName.TIME_COST] = used_time metrics_output = self.model_class.get_metrics(fetch_output_dict, meta_info, phase) return metrics_output -
模型保存:可分为checkpoints和inference model两种形式。这部分代码由基类实现,用户无需自定义实现,直接调用save_models方法即可,其基类中的部分代码实现如下所示:
def save_model(self, steps, save_checkpoint=True, save_inference=True): logging.info("save model on static....") if save_checkpoint: self.save_checkpoint(self.executor, self.train_program, steps) if save_inference: self.save_inference(self.executor, self.feed_target_tensor, self.inference_output, self.save_inference_program, steps, self.infer_dict)
BaseDynamicTrainer
BaseDynamicTrainer为动态图模式的Trainer基类,其主要的方法和能力为:
- 运行环境初始化:根据当前用户的安装环境,初始化飞桨的运行时环境。这部分的代码在基类中已经实现,用户无需自己编码实现,仅需要配置好对应的参数即可,参数定义详见实战演练:使用文心进行模型训练。
- 构造神经网络:调用Model实例的structure和set_optimizer方法完成神经网络的构造,调用load_pretrain_model方法加载热启动或者预训练模型的参数文件,这部分的代码在基类中已经实现,部分代码如下所示。用户无需自定义编码实现。关于Model介绍请移步Model。
- 模型训练:启动训练任务,不断通过Reader读取数据集,送入Model中进行计算,并得到评估结果,直到循环结束。这部分的代码在基类中只是定义了虚方法,需要用户继承来自定义实现。文心目前提供了通用的CustomDynamicTrainer类(wenxin_appzoo/tasks/xxx/custom_dynamic_trainer.py),能够覆盖大部分训练评估流程,用户如果对自定义训练评估要求不高,可以直接使用该类,部分代码如下所示:
def do_train(self):
"""
:return
"""
dg = self.data_set_reader.train_reader
steps = 1
opt_params = self.original_model.model_params.get('optimization', None)
# 设置混合精度相关的参数,可以没有,
init_loss_scaling = opt_params.get("init_loss_scaling", 1.0)
incr_every_n_steps = opt_params.get("incr_every_n_steps", 1000)
decr_every_n_nan_or_inf = opt_params.get("decr_every_n_nan_or_inf", 2)
incr_ratio = opt_params.get("incr_ratio", 2.0)
decr_ratio = opt_params.get("decr_ratio", 0.8)
if self.use_amp:
self.scaler = paddle.amp.GradScaler(enable=self.use_amp,
init_loss_scaling=init_loss_scaling,
incr_ratio=incr_ratio,
decr_ratio=decr_ratio,
incr_every_n_steps=incr_every_n_steps, decr_every_n_nan_or_inf=decr_every_n_nan_or_inf)
if self.multi_devices:
self.scaler = fleet.distributed_scaler(self.scaler)
time_begin = time.time()
# 启动训练集数据读取器
for batch_id, data in enumerate(dg()):
self.model_class.train()
with paddle.amp.auto_cast(enable=self.use_amp):
example = self.data_set_reader.train_reader.dataset.convert_fields_to_dict(data, need_emb=False)
forward_out = self.model_class(example, phase=InstanceName.TRAINING)
loss = forward_out[InstanceName.LOSS]
if self.use_amp:
loss = self.scaler.scale(loss)
loss.backward()
self.scaler.minimize(self.optimizer, loss)
else:
loss.backward()
self.optimizer.minimize(loss)
self.optimizer.step()
self.model_class.clear_gradients()
if self.original_model.lr_scheduler:
cur_lr = self.original_model.lr_scheduler.get_lr()
self.original_model.lr_scheduler.step()
else:
cur_lr = self.original_model.lr
self.optimizer.clear_grad()
# 在合适的时机进行当前step的数据评估
if steps % self.params["train_log_step"] == 0:
metrics_output = self.original_model.get_metrics(forward_out, meta_info, InstanceName.TRAINING)
time_begin = time.time()
# 在合适的时机对测试集、验证集上的数据进行评估
if steps % self.params["eval_step"] == 0:
if self.params["is_eval_dev"]:
self.do_evaluate(self.data_set_reader.dev_reader, InstanceName.EVALUATE, steps)
if self.params["is_eval_test"]:
self.do_evaluate(self.data_set_reader.test_reader, InstanceName.TEST, steps)
# 适当的时候进行模型保存
if steps % self.params["save_model_step"] == 0 and self.worker_index == 0:
self.save_models(steps, example)
steps += 1
....- 模型评估:启动待测试数据集对应的Reader,从Reader中读取数据集,送入Model中进行计算,得到每个batch的计算结果并保存,直到循环结束。将所有batch的计算结果汇总起来传入Model的get_metrics方法进行整个评估数据集上的指标计算。这部分的代码在基类中只是定义了虚方法,需要用户继承来自定义实现。文心目前提供了通用的CustomDynamicTrainer类(wenxin_appzoo/tasks/xxx/custom_dynamic_trainer.py),能够覆盖大部分训练评估流程,用户如果对自定义训练评估要求不高,可以直接使用,部分代码如下所示:
def do_evaluate(self, reader, phase, step):
"""
:param reader:
:param phase:
:param step:
:return loss
"""
step = 0
with paddle.no_grad():
time_begin = time.time()
# 先切换到eval模式
self.model_class.eval()
fetch_output_dict = collections.OrderedDict()
for batch_id, data in enumerate(reader()):
step += 1
example = reader.dataset.convert_fields_to_dict(data, need_emb=False)
forward_out = self.model_class(example, phase=phase)
for key, value in forward_out.items():
fetch_output_dict.setdefault(key, []).append(value)
time_end = time.time()
used_time = time_end - time_begin
meta_info = collections.OrderedDict()
meta_info[InstanceName.STEP] = step
meta_info[InstanceName.TIME_COST] = used_time
metrics_output = self.original_model.get_metrics(fetch_output_dict, meta_info, phase)
self.model_class.train()
logging.info("eval step = {0}".format(step))- 模型保存:可分为checkpoints和inference model两种形式。这部分代码由基类实现,用户无需自定义实现,直接调用save_models方法即可,其基类中的部分代码实现如下所示:
def save_models(self, step, fields_dict, save_checkpoint=True, save_inference=True):
"""模型保存:checkpoints文件用来热启动,inference文件用来预测推理
:param step:
:param fields_dict:
:param save_checkpoint
:param save_inference
:return
"""
path_dict = get_model_paths(self.save_checkpoints_path, self.save_inference_model_path, step)
if save_checkpoint:
save_path = os.path.join(path_dict["checkpoints_model_path"], "wenxin")
paddle.save(self.original_model.state_dict(), "{0}.pdparams".format(save_path))
paddle.save(self.original_model.optimizer.state_dict(), "{0}.pdopt".format(save_path))
meta_path = path_dict["checkpoints_meta_path"]
save_meta_data(self.meta_dict, meta_path)
if save_inference:
save_path = os.path.join(path_dict["inference_model_path"], "wenxin")
logging.info("save path: {0}".format(save_path))
# 通过飞桨提供的TraceLayer方式讲动态图模式模型保存成静态图类型,方便做预测加速。
output, static_wenxin = WenxinTracedLayer.trace(self.original_model,
inputs=fields_dict,
phase="save_inference")
static_wenxin.save_inference_model(save_path)
meta_path = path_dict["inference_meta_path"]
save_meta_data(self.meta_dict, meta_path)
infer_dict = {"fields": output[InstanceName.TARGET_FEED_NAMES]}
infer_meta_path = path_dict["inference_infer_meta_path"]
save_meta_data(infer_dict, infer_meta_path)文心中的预置Trainer
文心目前为所有的Task都提供了2个通用的Trainer,一个静态图Trainer,一个动态图Trainer,覆盖文本分类、文本匹配、序列标注、信息抽取、term重要性、情感分析等,所有的预置Trainer文件位于./wenxin_appzoo/tasks/xxx/training/目录下。
├── __init__.py
├── custom_trainer.py ## 通用trainer,支持文本分类、匹配、序列标注、信息抽取等常见任务。
├── mrc_trainer.py ## 阅读理解任务使用的trainer
├── trainer_config.py ## 定义trainer所需参数的类进阶使用
文心中提供了通用的Trainer流程,如果用户需要针对自己的业务场景进行自定义优化使用的话,请参考详细的接口设计与自定义Trainer。