

ERNIE介绍
更新时间:2022-08-03
ERNIE
简介
ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE在情感分析、文本匹配、自然语言推理、词法分析、阅读理解、智能问答等16个公开数据集上全面显著超越世界领先技术,在国际权威的通用语言理解评估基准GLUE上,得分首次突破90分,获得全球第一。在2020年的全球最大语义评测SemEval2020上,ERNIE摘得5项世界冠军,该技术也被全球顶级科技商业杂志《麻省理工科技评论》官方网站报道,相关创新成果也被国际顶级学术会议AAAI、IJCAI收录。ERNIE在工业界得到了大规模应用,如搜索引擎、新闻推荐、广告系统、语音交互、智能客服等。
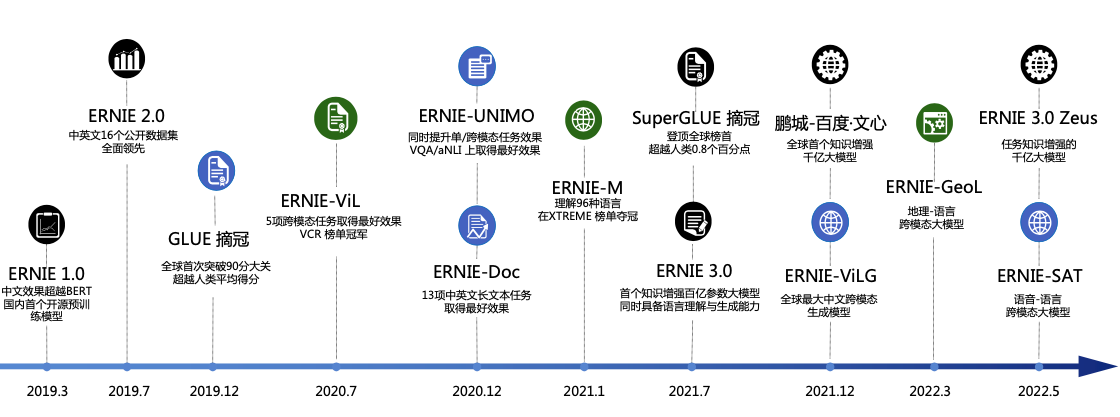
文心中的ERNIE
文心目前支持的ERNIE预训练模型如下所示:
| 模型名称 | 简介 |
|---|---|
| ERNIE 1.0 | ERNIE 1.0 通过建模海量数据中的词、实体及实体关系,学习真实世界的语义知识。相较于 BERT 学习原始语言信号,ERNIE 直接对先验语义知识单元进行建模,增强了模型语义表示能力。 |
| ERNIE 3.0-Tiny | 由于预训练语言模型越来愈大,过大的参数量导致了模型难以使用。ERNIE 3.0-Tiny 通过知识蒸馏的方式将大模型压缩到若干个不同大小的小模型,以便满足不同的需求。同时,ERNIE 3.0-Tiny采用task-agnostic蒸馏方案,与以往蒸馏不同,ERNIE 3.0-Tiny 模型开箱即用,在下游任务上直接finetune就能取得不错的效果,无需额外使用下游老师模型进行蒸馏。 |
| ERNIE 2.0 | ERNIE 2.0 是基于持续学习的语义理解预训练框架,使用多任务学习增量式构建预训练任务。ERNIE 2.0中,新构建的预训练任务类型可以无缝的加入训练框架,持续的进行语义理解学习。 通过新增的实体预测、句子因果关系判断、文章句子结构重建等语义任务,ERNIE 2.0语义理解预训练模型从训练数据中获取了词法、句法、语义等多个维度的自然语言信息,极大地增强了通用语义表示能力。 |
| ERNIE 2.3 | ERNIE2.3是针对ERNIE 2.0优化后的一个版本,通过提出多视角对抗预训练语言技术、随机位置编码策略和对比自监督预训练技术,使得模型在8个中文主流下游任务上获得了明显的效果提升。 |
| ERNIE 3.0 Base/Large | ERNIE 3.0系列模型是针对ERNIE模型优化的最新版本,通过提出字词混合的自监督对比学习预训练技术和字词混合数据增强自对抗微调技术,使得模型在8个中文主流下游任务上获得了明显的效果提升。 |
| ERNIE 3.0-10B | ERNIE 3.0中,提出了一个多范式统一的大规模预训练框架,基于该框架,ERNIE 3.0融合了自回归网络和自编码网络,同时由于大规模知识图谱类数据的引入,使得模型能够在理解任务、生成任务、零样本学习任务和常识推理任务上均获取优秀的表现。 |
| ERNIE 3.0-1.5B | ERNIE3.0-1.5B是针对理解任务训练的大模型,模型规模处于ERNIE-Large和ERNIE3.0(10B)模型之间。通过增大模型规模以及提出Pretrain-RDrop技术,使得模型在多个中文主流下游任务上获得了明显的效果提升。在6大中文数据集上,1.5B模型相对ERNIE 2.3 Large模型平均提升+0.49%。 |
| ERNIE-Word | ERNIE-Word是利用百度研发的先进中文预训练语言模型ERNIE产出的静态词向量。 |
| ERNIE-M | ERNIE-M 是一个多语言模型,它通过大规模的单语语料和双语语料来捕捉语言之间的语义,可以同时建模96种语言,适用于各项多语言任务,跨语言任务。 |
| ERNIE-Doc | 传统预训练模型(ERNIE、BERT等)的最大建模长度一般不超过512,因此在处理长度超过512的文本时,或是选择随机截断成512个字符长度,或是选择裁剪为多个长度不超过512的文本片段。上述的两种策略均会造成信息丢失或者文本语义割裂的问题,也即传统的预训练模型并不适用于超长文本的应用场景。ERNIE_DOC是一种基于Transformer-XL架构的长文本预训练语言模型。 |
其他模型详细: