

常见问题
安装及环境配置问题
如果没有本地 GPU 的话,本地CPU能训练ERNIE模型吗,例如文本分类任务?
可以使用单机CPU训练,但速度很慢。还是建议在GPU上训练效率会高一些。但如果只是为了调试方便,可以直接在CPU上进行。
- 如果只是直接在CPU上训练,只需要将examples/xxx.json中的 PADDLE_PLACE_TYPE设置为cpu. 指定好自己的python路径,其余的环境变量不需要设置。本地运行的话,请确认本地paddle支持CPU运行。
- 如果希望在CPU上调试代码,可以上面配置的基础上更进一步将ERNIE模型config文件中的层数由12层改为1层,就可以运行得非常快了,方便进行本地调试。确保代码没有错误之后,再在GPU上按正常的12层的ERNIE模型进行训练即可。
每个任务目录下的env.sh中的默认配置,是不是基于本地GPU训练的方式配置的?
是的,用户在本地进行训练时需要按照提示配置env.sh,并使用以下命令进行加载。
source env.shpython3环境的wenxin import 报错:ImportError: dynamic module does not define module export function (PyInit_base_trainer)
文心依赖的python版本需要使用python3.7.x的;如果您的Python版本低于3.7,比如python 3.6.4,就会报错。
训练时cuda环境不匹配导致报错,如何解决?
cuda环境不匹配的最常见原因为cuda及cudnn版本不正确,以CentOS为例,文心训练包对CUDA和cuDNN版本支持如下所示:
- CentOS 7 支持 CUDA 9.0/9.1/9.2/10.0/10.1,但对于 CUDA 9.1 仅支持单卡模式
- CentOS 6 支持 CUDA 9.0/9.1/9.2/10.0/10.1,仅支持单卡模式
- 需要使用 cuDNN 7.3+
- 如果您需要多卡模式,请安装 NCCL 2 ,更多信息可见:PaddlePaddle 对 NCCL 支持情况
常见的报错信息及其解决方法总结如下所示:
| 报错信息 | 问题描述 | 问题解答 |
|---|---|---|
| Error: no CUDA-capable device is detected | 使用paddle时出现no CUDA-capable device is detected错误 | 没装对cuda。建议查找libcudart.so在哪个目录下,并将其加到LD_LIBRARY_PATH中。例如: find / -name libcudart.so, 可以发现libcudart.so在/usr/local/cuda-8.0/targets/x86_64-linux/lib/libcudart.so, 然后使用命令export LD_LIBRARY_PATH=/usr/local/cuda-8.0/targets/x86_64-linux/lib/libcudart.so$LD_LIBRARY_PATH即可 |
| Error: after cudaFuncGetAttributes: invalid device function | 在A机器上编译的paddle,在B机器上跑报错Runtime Error: function_attributes(): after cudaFuncGetAttributes: invalid device function | 应该是在A上编译的时候选择的GPU的架构与B机器上的GPU架构不兼容,建议用户在B上重新编译 |
| driver version is insufficient for runtime version | 在使用PaddlePaddle GPU的Docker镜像的时候,出现 Cuda Error: CUDA driver version is insufficient for CUDA runtime version? | 通常出现 Cuda Error: CUDA driver version is insufficient for CUDA runtime version, 原因在于机器上CUDA驱动偏低,需要升级CUDA驱动加以解决。Ubuntu和CentOS环境,可以把相关的驱动和库映射到容器内部。 Windows环境,需要升级CUDA驱动。Ubuntu和CentOS下如果使用GPU的docker环境,需要用nvidia-docker来运行。更多请参考nvidia-docker |
| CUDNN_STATUS_NOT_INITIALIZED | CUDNN_STATUS_NOT_INITIALIZED at [/paddle/paddle/fluid/platform/device_context.cc:216] | cuDNN与CUDA版本不一致导致。PIP安装的GPU版本默认使用CUDA 9.0和cuDNN 7编译,请根据您的环境配置选择在官网首页选择对应的安装包进行安装,例如paddlepaddle-gpu==1.2.0.post87 代表使用CUDA 8.0和cuDNN 7编译的1.2.0版本。 |
更多可能出现的错误和解决方案请咨询paddle安装与编译-GPU 。
数据处理问题
如何识别脏数据(观察训练日志正常走了几个step后程序失败)?
当出现读取部分数据后报错的情况时,可以怀疑训练数据中有脏数据,即数据不符合正确格式,包括缺少域、数据编码错误(需为utf-8)等,文心各任务所需的数据格式请参考NLP任务详细说明中各任务页面内关于数据部分的解释。
此时可通过二分查找或专门的数据格式校验工具,剔除或修改缺乏标签的脏数据。
训练过程中出现报错:Error: line contains NULL byte 怎么办?
报错原因是训练数据有特殊字符,文心在训练、预测的过程中,会使用目录下面的所有文件,包括隐藏文件,如果目录下有un~, swp为结尾的隐藏文件,会报上述错误。
对于大数据读取太慢怎么改进?
文心默认采用warmup + linear decay训练模型,需要提前知道数据量的大小,所以默认读取全量数据以统计。这使得对于大数据读取就会变慢。可以提前计算好数据量的大小通过配置文件直接传入程序进行训练。
训练集、测试集和验证集之间的区别是什么?
- train_set(训练集):用于确定模型参数。
- val_set(验证集):用于调节模型超参数(如多个网络结构、正则化权重的最优选择)。
- test_set(测试集):用于估计应用效果(没有在模型中应用过的数据,更贴近模型在真实场景应用的效果)。
文心大部分任务的训练集、测试集和验证集三者格式一致。主要的不同是数据读取路径不同。当训练与评估的范式不一样时,比如pairwise 匹配任务,训练集与验证集的格式会有较大差别。
如何增加数值特征、离散非文本特征?
数值特征和离散非文本特征的添加方式为在json中对field进行配置,如下所示。
{
"dataset_reader": {
"train_reader": { ## 训练、验证、测试各自基于不同的数据集,数据格式也可能不一样,可以在json中配置不同的reader,此处为训练集的reader。
"name": "train_reader",
"type": "BasicDataSetReader", ## 采用BasicDataSetReader,其封装了常见的读取tsv文件、组batch等操作。
"fields": [ ## 域(field)是文心的高阶封装,对于同一个样本存在不同域的时候,不同域有单独的数据类型(文本、数值、整型、浮点型)、单独的词表(vocabulary)等,可以根据不同域进行语义表示,如文本转id等操作,field_reader是实现这些操作的类。
## 如果每一个样本有多个特征域(文本类型、数值类型均可),可以仿照前面对每个域进行设置,依次增加每个域的配置即可。此时样本的域之间是以\t分隔的。
{
"name": "label", ## 标签也是一个单独的域,命名为"label"。如果多个不同任务体系的标签存在于多个域中,则可实现最基本的多任务学习。
"data_type": "int", ## 标签是整型数值。
"reader":{
"type":"ScalarFieldReader" ## 整型数值域的reader为"ScalarFieldReader"。
},
"tokenizer":null,
"need_convert": false,
"vocab_path": "",
"max_seq_len": 1,
"truncation_type": 0,
"padding_id": 0,
"embedding": null
}
],
……
}工具版序列标注报错:Emission和Input的Dimension不一致
序列标注中如果配置的FullTokenizer,会对英文做subword操作的,导致labels的shape跟原始文本的shape对不上。所以需要更换Tokenizer,保证标注与token一一对应。
组网问题
如何找到json配置对应的网络并修改其组网方式?
json中的model部分关联了model中的预制网络。
以文本分类预制json配置文件为例,其中type的值对应的类名为“CnnClassification”,它就是预制网络的类名,该网络可在网络../../wenxin/models/文件夹中找到,其小写下划线写法(cnn_classification.py)为其对应的文件名,打开该文件可以修改其中网络结构。
{
...
"model": {
"type": "CnnClassification", ## 文心采用模型(models)的方式定义神经网络的基本操作,本例采用预置的模型CnnClassification实现文本分类,具体网络可参考models目录。
"optimization": { ## 预置模型的优化器所需的参数配置,如学习率等。
"learning_rate": 2e-05
}
},
...
}如何在inference过程中输出自己想要的任意输出?
只需要在组网时将前向网络forward的target_predict_list = []的列表中放入您想要的任何Tensor即可。
以分类任务的bow_classification预置模型为例,其target_predict_list如下所示:
if phase == InstanceName.SAVE_INFERENCE:
"""保存模型时需要的入参:表示模型预测时需要输入的变量名称和顺序"""
target_feed_name_list = [text_a.name, text_a_lens.name]
"""保存模型时需要的入参:表示预测时最终输出的结果"""
target_predict_list = [predictions]
forward_return_dict = {
InstanceName.TARGET_FEED_NAMES: target_feed_name_list,
InstanceName.TARGET_PREDICTS: target_predict_list
}
return forward_return_dict表明该预置网络在inference过程中的输出为Tensor predictions。
序列标注任务的label_map如何配置?
文心套件采用域的概念来处理标签,序列标注任务的标签配置label_map为词表的形式,以IOB方式标注为例,其label_map.txt词表文件如下所示,更多详情请参考序列标注-标签词表 .
B-PER 0
I-PER 1
B-ORG 2
I-ORG 3
B-LOC 4
I-LOC 5
O 6什么时候需要使用不基于域的数据处理方式?
在复杂任务中(如阅读理解任务,可参考../../wenxin/data/data_set_reader/basic_dataset_reader_without_fields.py),分域的方式很可能无法满足数据读取的需求,我们提供了在文心套件范围内的自定义方式,具体实现方式请参考核心接口-完全自定义数据集读取器 。
训练问题
不同ernie模型推荐的batch size是多少?
请参考预训练模型介绍-ERNIE使用-ERNIE推荐batch_size大小,一般是2的整数次幂。可以选择让GPU利用率最高的batch_size。
eval_step 和 save_model_step 如何设置?
一般模型评估与模型保存比较耗时,建议用户调大eval_step 和 save_model_step两个值。如eval_step比train_log_step大10倍以上,save_model_step比eval_step大10倍以上。
评估集大小如何设置?
用户跑train任务时,评估集设置太大,会导致评估阶段过长,可以考虑适当缩小评估集数量。
可以配置哪些参数用于提升训练迭代速度?
训练迭代速度与数据规模有关,核心是关注GPU利用率。在训练大规模数据时,可以调整如下参数来提升训练速度。
- batch_size(一次训练所选取的样本数):该参数越大,训练速度越快。但是该参数受显存大小限制,与单个数据样本的长度和Embedding的维度相关,较长的数据样本或使用较大维度的Embedding时,大batch_size容易导致超显存的情况出现,需要适当缩小。
- epoch(将所有训练样本训练一遍的次数):一个数据集完整地通过神经网络进行训练的过程称为一次epoch。epoch越大,整体的训练速度越慢,当然模型的效果可能会因为epoch的增加而提高(也存在因为epoch过多导致模型过拟合的情况)。
- is_eval_test和is_eval_dev(是否使用测试集和验证集来评估模型):训练过程中进行模型评估时,测试集和验证集的大小会极大的影响模型训练的整体速度,建议训练集、测试集和验证集的比例为6:2:2。在数据集较大时,应适当减少测试集和验证集。
- eval_step(模型评估的间隔步数):数据量较大时,应将模型评估的相隔步数放大,否则会影响训练速度。
如何调整学习率?
- 学习率往往是深度学习里最常要调整的参数。
- 最简单的方式是选用adam等优化器,自动调整学习率,并且一般能够收敛到比较好的效果。
- 如果希望手动调整学习率,一般可按照等比数列调整,如每次放大(缩小)10倍\5倍进行调参。
- ERNIE系列预训练模型对学习率更加敏感,一般建议直接采用预制学习率,如果需要调整,可进行2倍3倍的放缩进行试验。
如何调整epoch?
一次epoch是指将所有数据训练一遍的次数,epoch所代表的数字是指所有数据被训练的总轮数。
epoch越大整体的训练速度越慢,当然模型的效果可能会因为epoch的增加而提高(也存在因为epoch过多导致模型过拟合的情况)。
使用ERNIE Large,经常出现OOM怎么办?
ERNIE预训练模型生成的词向量维度较大(最少为768维),因此使用ernie时,是否会出现OOM与数据长度强相关。尤其是ERNIE Large模型,生成的词向量维度为1024维,当数据长度较大时,极易出现OOM的情况。
对于OOM,优先的解决方案是将batchsize调小。
在训练的时候怎么冻结Ernie参数
对于Ernie的参数,需要更新参数时,将tasks/model_files/config中对应版本的ernie_xx_config.json中的freeze_emb设为false,freeze_num_layers设为0;不需要更新参数时,将config中的freeze_emb设为true,freeze_num_layers设为12(freeze_num_layers的最大值为num_hidden_layers的取值),attention_probs_dropout_prob设置为0.0,hidden_dropout_prob设置为0.0。
对于非Ernie的参数,直接将其梯度关掉即可,举例如下:
x_param = fluid.default_main_program().global_block().var("x_param_name")
x_param.stop_gradient = True在保存模型时遇到报错ValueError: var read_file_0.tmp_X(X为数字编号,例如4)not in this block怎么办?
该报错的原因在于,paddlepaddle在生成inference_model的时候,会进行模型剪裁,将组网过程中没有用到的变量去除。若此时用户在组网部分的SAVE_INFERENCE部分添加了没有用到变量,那么就会报上述错误。
解决方法:将多余的变量从组网代码中forward_return_dict[target_feed_name_list]中去除即可。
应该在哪里查看paddle的一些op及其说明?
paddlepaddle的相关api说明请参考API Reference 。
如何实现一个新的网络?
我们提供了建模核心接口类:model(./wenxin/models/model.py),您可以通过继承该基类来实现接口对齐,具体实现方式请参考核心接口-建模核心接口。
json中新加field后,组网forward提示找不到对应filed
dev_reader的配置和test_reader的配置需保持一致,wenxin的controler中,test和dev的网络共用同一个,仅reader不一样,所以当两个reader配置不一样时会报错。
如何GPU单机多卡训练
若训练环境为本地开发机时,要进行GPU单机多卡训练,只需在开始训练前运行以下命令即可。
# 选择要使用的GPU编号,0和1即为GPU0和GPU1,指此时使用这两卡进行单机多卡训练,然后使用fleetrun开始训练。
export CUDA_VISIBLE_DEVICES=0,1
fleetrun --gpus=0,1 run_trainer.py --param_paht ./example/some_example.json训练过程中遇到报错:KeyError: ‘predict_result’。
当测试数据文件为空的时候,会出现上述问题,请检查测试数据情况。
文本分类任务中如何实现多分类?
首先跑通文本分类的demo,默认demo是二分类。
保证训练评估数据的标签为多分类格式,如示例数据为3分类,标签标注分别为0\1\2,文本经过分词预处理。并且训练数据、测试数据和验证数据格式相同。数据分为两列,第一列为分词处理后的文本,第二列为标签。列与列之间用\t进行分隔,如下所示:
房间 太 小 。 其他 的 都 一般 。 。 。 。 。 。 。 。 。 0
LED屏 就是 爽 , 基本 硬件 配置 都 很 均衡 , 镜面 考 漆 不错 , 小黑 , 我喜欢 。 2
差 得 要命 , 很大 股霉味 , 勉强 住 了 一晚 , 第二天 大早 赶紧 溜 1并且,需要在json配置中将num_labels设置为相应的类别数。
- 在本例中”dataset_reader”=>”train_reader”=>”fields”的列表里对应”name”为”label”的配置中新增 “num_labels”: 3 。
- 同时在”model”中新增 “num_labels”: 3 。
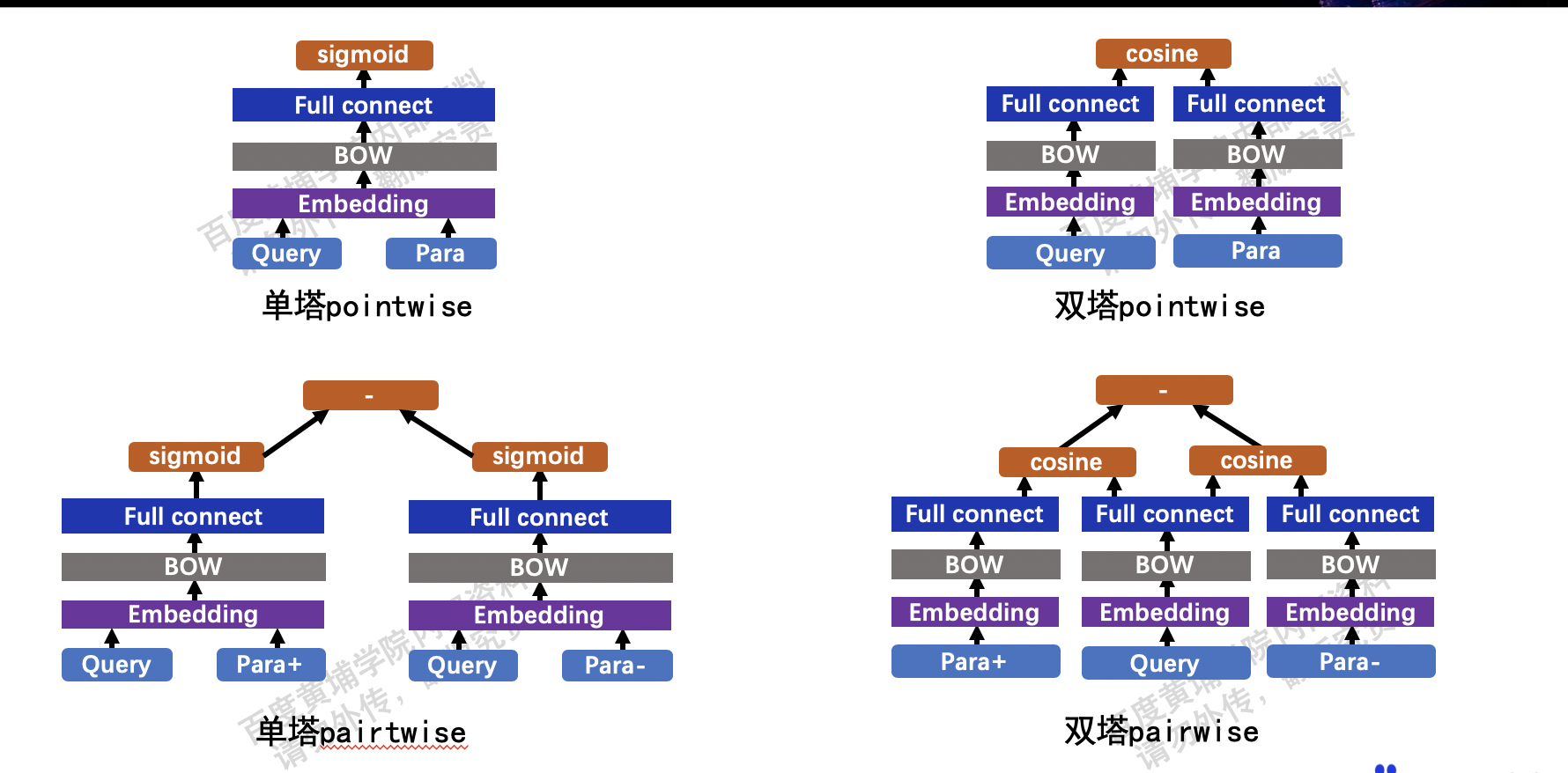
文本匹配的任务中,如何将单塔改为双塔
- 对应使用ernie的模型,单塔就是两段文本拼在一起输入ernie,匹配任务的默认FC网络就是单塔。双塔就是每段文本单独过一个ernie。
- 预制网络json中名字带有simnet的就是双塔。
- 非ernie匹配预制网络默认都是双塔。
- 双塔匹配有两种训练方式,分别是pointwise与pairwise。
- 使用ernie进行双塔的建模的两个预制网络可在./models 文件夹中找到,文件名分别为:ernie_matching_siamese_pairwise.py、ernie_matching_siamese_pointwise.py。
为什么文心的PN指标的上限会是128.0这个值而不是正无穷?
pn的计算是right_cnt / wrong_cnt, 如果除数为0 的时候,结果应该是inf(正无穷), 但是由于inf无法像一般的float值那样可以可视化展示出来,所以默认就用128.0这个固定值来表示这个情况, 128.0这个值可以按自己的需要修改。
预测任务和test任务指标ACC无法对齐,是什么原因?
出现无法对齐的原因之一,是在预测时没有使用对应正确的tokenizer。