

6. Metrics
简介
在文心中,我们把NLP领域常见的模型评估的方法进行了统一封装,称作Metics。在文心中,我们在模型训练过程通过对测试集和评估集上的样本先进行预测,然后用预测结果与标注结果进行比较从而得出模型效果。文心中的模型评估方法由Trainer调用,具体评估指标计算在每个Model的get_metrics方法中。
基本结构
评估指标计算模块位于./wenxin/metrics/目录下,其结构及说明如下所示:
├── __init__.py
├── metrics.py ## 通用的评估脚本,依赖sklearn库实现多数常用评估指标的计算,例如Acc、Precision、Recall和F1等。
└── chunk_metrics.py ## 序列标注常用的指标与评估方式基础操作
文心模型评估模块通过对建模核心接口类model(./wenxin/models/model.py)中的get_metrics()方法重写来实现,其功能和参数定义如下所示:
def get_metrics(self, forward_return_dict, meta_info, phase):
"""指标评估部分的动态计算和打印
:param forward_return_dict: executor.run过程中fetch出来的forward中定义的tensor
:param meta_info:常用的meta信息forward_return_dict如step, used_time, gpu_id等
:param phase: 当前调用的阶段forward_return_dict包含训练和评估
:return:metrics_return_dict:该dict中存放的是各个指标的结果forward_return_dict以文本分类为例forward_return_dict该dict内容如下所示:
{
"acc": acc,
"precision": precision
}
"""使用方式:文心提供以下三种方式进行模型评估,这三种方式灵活性依次提升,开发难度同时依次增加。
- 在所使用Model(模型网络)的get_metrics()方法里调用预置的评估指标实例进行计算: ./wenxin/metrics/metrics.py为通用的评估脚本,依赖sklearn库实现多数常用评估指标的计算,例如Acc、Precision、Recall和F1等。以Acc指标为例,在get_metrics()中的调用方式如下所示:
from wenxin.metrics import metrics
def get_metrics(self, forward_return_dict, meta_info, phase):
metrics_acc = metrics.Acc()
acc = metrics_acc.eval([predictions, label])
metrics_return_dict = collections.OrderedDict()
metrics_return_dict["acc"] = acc
return metrics_return_dict-
不使用预置的评估方式,直接在get_metrics()方法中自定义所需评估指标的计算:
该方法只需保证get_metrics()方法的输出以metrics_return_dict的形式即可。以语言模型任务的指标ppl为例,其实现方式如下所示:
def get_metrics(self, forward_return_dict, meta_info, phase): loss = forward_return_dict[InstanceName.LOSS] infer_label_lens = forward_return_dict[InstanceName.INFER_LABEL_SEQ_LENS] total_ppl = 0.0 for seq_loss in loss: avg_ppl = np.exp(seq_loss) seq_ppl = np.mean(avg_ppl) total_ppl += seq_ppl ave_ppl = int(total_ppl / len(loss)) metrics_return_dict = collections.OrderedDict() metrics_return_dict["ppl"] = ave_ppl return metrics_return_dict -
不使用get_metrics()方法,在训练流程中自定义评估:
训练流程与核心调度模块详情请参考文心core设计和Trainer设计,以分类任务种的trainer(wenxin_appzoo/tasks/text_classification/trainer/custom_trainer.py)为例,可以通过在以下语句部分直接进行操作来实现自由度最高的自定义评估:
metrics_output = self.model_class.get_metrics(fetch_output_dict, meta_info, phase)
文心支持的常用评估指标
-
ACC
- 说明:Acc(准确率)是指所有分类正确的百分比。
- 公式:
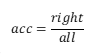
- 取值:在0-1之间,值越大越好
-
实现形式:
accuracy_score(y_true, y_pred)
-
Precision
- 说明:Precision(精确率)是指在所有预测出来的正例中有多少是真的正例。
- 计算方式:
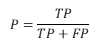 ,其中,TP为正例预测正确的个数,FP为负例预测错误的个数。
,其中,TP为正例预测正确的个数,FP为负例预测错误的个数。 - 取值:在0-1之间,值越大越好。
-
实现形式:参数average:string, [None, ‘micro’, ‘macro’(default), ‘samples’, ‘weighted’]。文心默认为macro(宏平均)。
precision_score(y_true, y_pred, average="macro")
-
AUC
- 说明:Auc(Area Under ROC Curve)即ROC曲线下面积,是一个模型的评价指标,用于分类任务。文心采用sklearn通过梯形规则计算曲线下面积。
- 计算方式:请参考Auc计算方法。
- 取值:在0-1之间。AUC值越大,分类模型性能越好。
-
实现形式:
fpr, tpr, thresholds = sklearn.metrics.roc_curve(label_arr, predict_arr) auc_score = sklearn.metrics.auc(fpr, tpr)
-
Recall
- 说明:召回率Recall(也称为敏感度)是指得到的相关实例数占相关实例总数的比例。
- 计算方式:
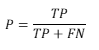 ,其中,TP为正例预测正确的个数,FN为将正类预测为负类的个数。
,其中,TP为正例预测正确的个数,FN为将正类预测为负类的个数。 - 取值:在0-1之间,值越大越好。
-
实现形式:
recall_score(y_true, y_pred)
-
F1
- 说明:为了能够评价不同算法的优劣,F1值用来对Precision和Recall进行整体评价。
- 计算方式:
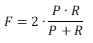 ,其中P代表Precision值,R代表Recall值。
,其中P代表Precision值,R代表Recall值。 - 取值:在0-1之间,值越大越好。
-
PPL
- 说明:ppl,即perplexity(困惑度),是用来度量一个概率分布或概率模型预测样本的好坏程度的指标。文心中该指标用于Seq2Seq文本生成任务。
- 计算方式:
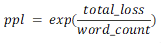 ,其中word_count为样本中词的个数,total_loss为该样本的总平均损失值。
,其中word_count为样本中词的个数,total_loss为该样本的总平均损失值。 - 取值:一般情况下,困惑度ppl越小,模型越好。
-
PN
- 说明:正序数、逆序数可作为模型效果的衡量指标,Pn(正逆序比)即为正序数量与逆序数量的比值。,当正序数量越多、逆序数量越少时,表明模型对序关系的刻画越准确,模型效果越好。
- 计算方式:
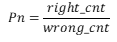 ,其中,right_cnt为正序数,wrong_cnt为逆序数。
,其中,right_cnt为正序数,wrong_cnt为逆序数。 - 取值:0-inf(正无穷)。当正序数量越多、逆序数量越少时,表明模型对序关系的刻画越准确,模型效果越好。
- Chunk:用于序列标注任务的评估指标,计算块检测(chunk detection)的准确率,召回率和F1值。更多详情请参考ChunkEvaluator接口。
-
LmPPL
- 说明:针对文心中语言模型(language model)任务的ppl计算。
- 计算方式:
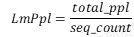 ,其中total_ppl为整个batch的ppl,seq_count为该batch中样本的个数。
,其中total_ppl为整个batch的ppl,seq_count为该batch中样本的个数。
-
PairWiseAcc
- 说明:针对pairwise模式匹配任务的acc指标计算。
- 计算方式:
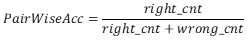 ,其中,pos_score小于等于neg_score时计入wrong_cnt,pos_score大于neg_score时计入right_cnt。
,其中,pos_score小于等于neg_score时计入wrong_cnt,pos_score大于neg_score时计入right_cnt。