

ERNIE 1.0介绍
更新时间:2022-07-05
简介
ERNIE(Enhanced Representation through kNowledge IntEgration)是百度提出的语义表示模型,基于Transformer Encoder,相较于BERT,ERNIE1.0 通过建模海量数据中的词、实体及实体关系,学习真实世界的语义知识。相较于 BERT 学习原始语言信号,ERNIE 直接对先验语义知识单元进行建模,增强了模型语义表示能力。
技术原理
-
ERNIE采用了Transformer Encoder进行语义表示,Transformer 是由论文Attention is All You Need首先提出的机器翻译模型,在效果上比传统的 RNN 机器翻译模型更加优秀。NLP领域中好多优秀的预训练模型都用到了Transformer,比如BERT、GPT等,其结构图如下所示:
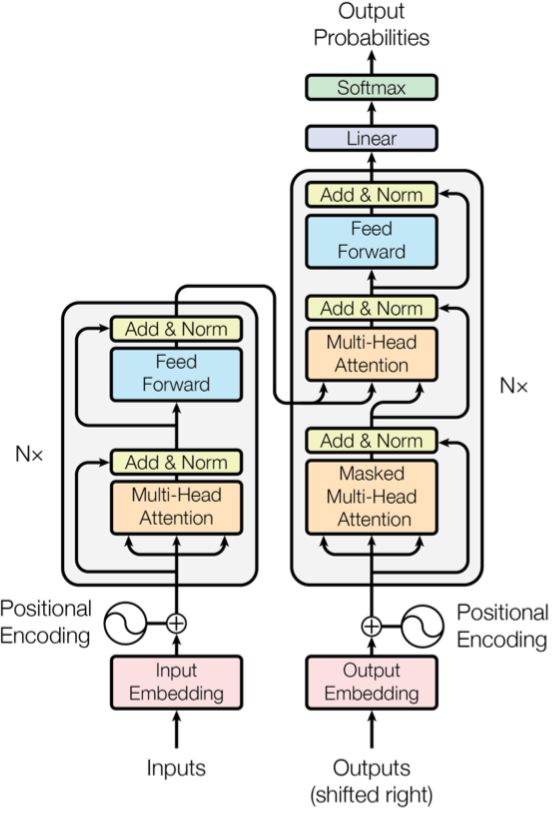
-
相较于 BERT 学习原始语言信号,ERNIE 直接对先验语义知识单元进行建模,增强了模型语义表示能力。示例如下:
Learnt by BERT :哈 [mask] 滨是 [mask] 龙江的省会,[mask] 际冰 [mask] 文化名城。 Learnt by ERNIE:[mask] [mask] [mask] 是黑龙江的省会,国际 [mask] [mask] 文化名城。
- 在 BERT 模型中,我们通过『哈』与『滨』的局部共现,即可判断出『尔』字,模型没有学习与『哈尔滨』相关的任何知识。
- 在ERNIE通过学习词与实体的表达,使模型能够建模出『哈尔滨』与『黑龙江』的关系,学到『哈尔滨』是 『黑龙江』的省会以及『哈尔滨』是个冰雪城市。
- 训练数据方面,除百科类、资讯类中文语料外,ERNIE还引入了论坛对话类数据,利用 DLM(Dialogue Language Model)建模 Query-Response 对话结构,将对话 Pair 对作为输入,引入 Dialogue Embedding 标识对话的角色,利用 Dialogue Response Loss 学习对话的隐式关系,进一步提升模型的语义表示能力。
- 预训练任务方面,ERNIE1.0与BERT一致,采用完形填空和上下句判断两个预训练任务。
模型效果
- 语义相似度任务 LCQMC:LCQMC 是哈尔滨工业大学在自然语言处理国际顶会 COLING2018 构建的问题语义匹配数据集,其目标是判断两个问题的语义是否相同。
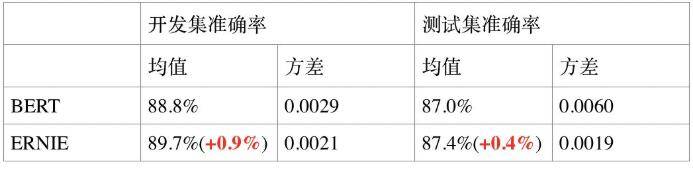
- 情感分析任务 ChnSentiCorp:ChnSentiCorp 是中文情感分析数据集,其目标是判断一段话的情感态度。
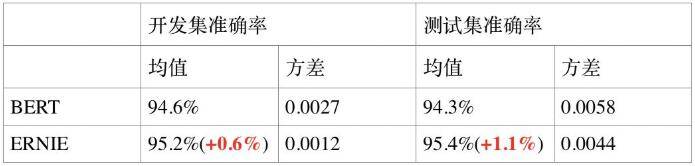
- 命名实体识别任务 MSRA-NER:MSRA-NER 数据集由微软亚研院发布,其目标是命名实体识别,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名等。
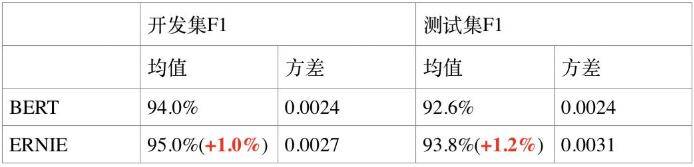
- 检索式问答匹配任务 NLPCC-DBQA :NLPCC-DBQA 是由国际自然语言处理和中文计算会议 NLPCC 于 2016 年举办的评测任务,其目标是选择能够回答问题的答案。
文心中ERNIE1.0的支持
目前文心暂不提供ERNIE1.0的使用,您可以前往下载开源包