ERNIE-Tiny介绍
更新时间:2022-07-05
基本介绍
- 其网络结构与ERNIE 1.0 base 中文模型不完全相同,有独立的模型配置json文件和dict。
- 与传统基于字粒度的ERNIE中文模型不同,ERNIE Tiny是基于词粒度的预训练模型。文心会默认对未分词文本进行分词。
- ernie_tiny的模型下载脚本位于./wenxin_app/models_hub/目录下,为download_ernie_tiny_1.0_ch.sh。
- 如何在文本分类任务中使用ERNIE-Tiny模型进行训练请参考:文本分类(Text Classification)中使用ernie_tiny进行分类任务训练。
原理介绍
- 为了提升ERNIE模型在实际工业应用中的落地能力,我们推出ERNIE-tiny模型。
-
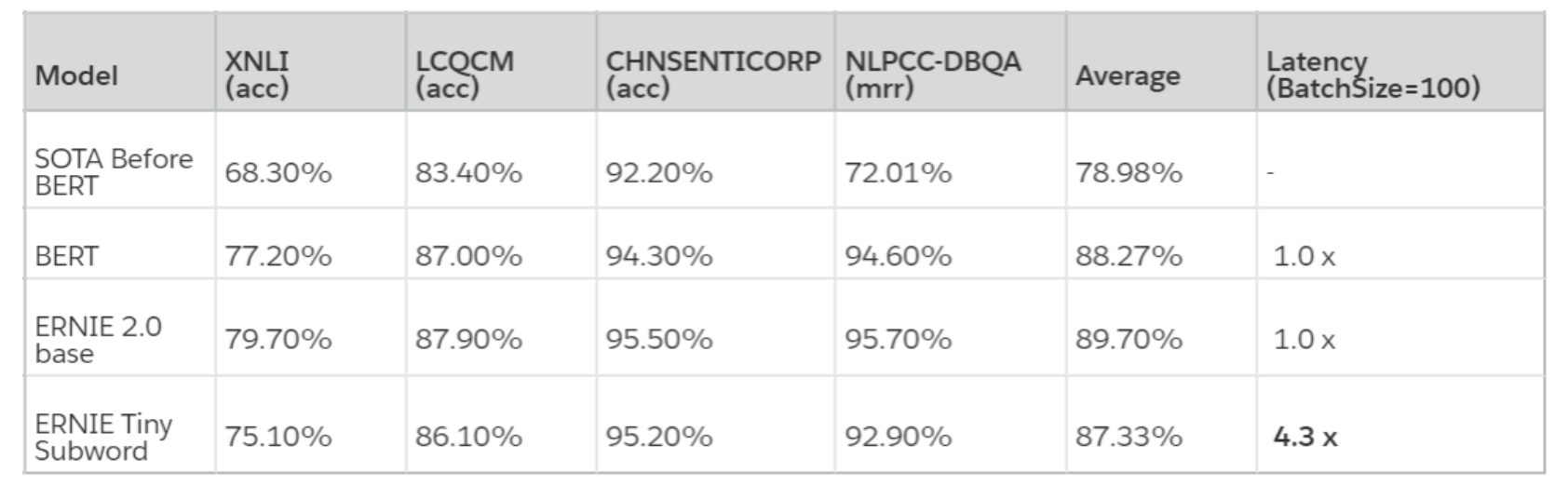
ERNIE-tiny作为小型化ERNIE,采用了以下4点技术,保证了在实际真实数据中将近4.3倍的预测提速。
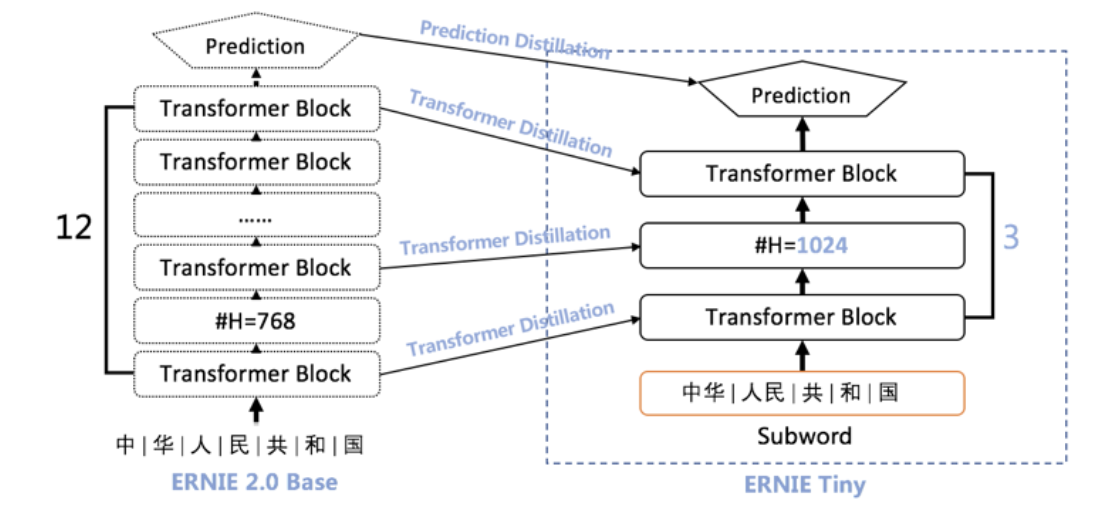
- 浅:12层的ERNIE Base模型直接压缩为3层,线性提速4倍,但效果也会有较大幅度的下降;
- 胖:模型变浅带来的损失可通过hidden size的增大来弥补。由于fluid inference框架对于通用矩阵运算(gemm)的最后一维(hidden size)参数的不同取值会有深度的优化,因为将hidden size从768提升至1024并不会带来速度线性的增加;
- 短:ERNIE Tiny是首个开源的中文subword粒度的预训练模型。这里的短是指通过subword粒度替换字(char)粒度,能够明显地缩短输入文本的长度,而输入文本长度是和预测速度有线性相关。统计表明,在XNLI dev集上采用subword字典切分出来的序列长度比字表平均缩短40%;
- 萃:为了进一步提升模型的效果,ERNIE Tiny扮演学生角色,利用模型蒸馏的方式在Transformer层和Prediction层去学习教师模型ERNIE模型对应层的分布或输出,这种方式能够缩近ERNIE Tiny和ERNIE的效果差异。
- 通过以上四个方面的压缩,ERNIE Tiny 模型的效果相对于 ERNIE 2.0 Base 平均只下降了 2.37%,但相对于「SOTA Before BERT」提升了 8.35%,而速度提升了 4.3 倍。