ERNIE预训练模型介绍
ERNIE 1.0: Enhanced Representation through kNowledge IntEgration
ERNIE 1.0 通过建模海量数据中的词、实体及实体关系,学习真实世界的语义知识。相较于 BERT 学习原始语言信号,ERNIE 直接对先验语义知识单元进行建模,增强了模型语义表示能力。
这里我们举个例子:
Learnt by BERT :哈 [mask] 滨是 [mask] 龙江的省会,[mask] 际冰 [mask] 文化名城。
Learnt by ERNIE:[mask] [mask] [mask] 是黑龙江的省会,国际 [mask] [mask] 文化名城。
在 BERT 模型中,我们通过『哈』与『滨』的局部共现,即可判断出『尔』字,模型没有学习与『哈尔滨』相关的任何知识。而 ERNIE 通过学习词与实体的表达,使模型能够建模出『哈尔滨』与『黑龙江』的关系,学到『哈尔滨』是 『黑龙江』的省会以及『哈尔滨』是个冰雪城市。
训练数据方面,除百科类、资讯类中文语料外,ERNIE 还引入了论坛对话类数据,利用 DLM(Dialogue Language Model)建模 Query-Response 对话结构,将对话 Pair 对作为输入,引入 Dialogue Embedding 标识对话的角色,利用 Dialogue Response Loss 学习对话的隐式关系,进一步提升模型的语义表示能力。
ERNIE 2.0: A Continual Pre-training Framework for Language Understanding
ERNIE 2.0 是基于持续学习的语义理解预训练框架,使用多任务学习增量式构建预训练任务。ERNIE 2.0 中,新构建的预训练任务类型可以无缝的加入训练框架,持续的进行语义理解学习。 通过新增的实体预测、句子因果关系判断、文章句子结构重建等语义任务,ERNIE 2.0 语义理解预训练模型从训练数据中获取了词法、句法、语义等多个维度的自然语言信息,极大地增强了通用语义表示能力。
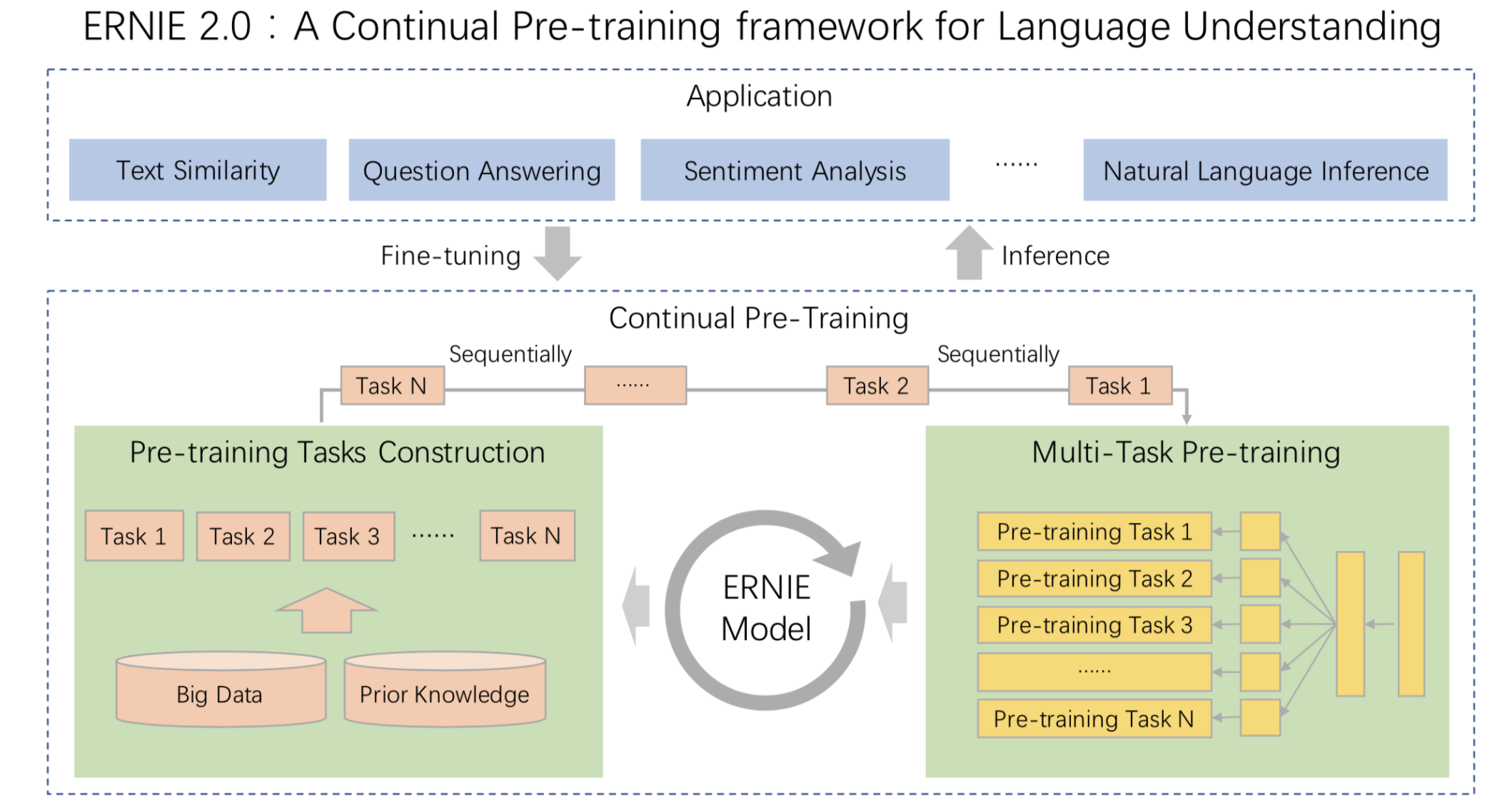
我们对 ERNIE 2.0 模型和现有 SOTA 预训练模型在 9 个中文数据集、以及英文数据集合 GLUE 上进行效果比较。结果表明:ERNIE 2.0 模型在英语任务上几乎全面优于 BERT 和 XLNet,在 7 个 GLUE 任务上取得了最好的结果;中文任务上,ERNIE 2.0 模型在所有 9 个中文 NLP 任务上全面优于 BERT。
Pre-Training 任务
针对 ERNIE 2.0 模型,我们构建了多个预训练任务,试图从 3 个层面去更好的理解训练语料中蕴含的信息:
- Word-aware Tasks: 词汇 (lexical) 级别信息的学习
- Structure-aware Tasks: 语法 (syntactic) 级别信息的学习
- Semantic-aware Tasks: 语义 (semantic) 级别信息的学习
同时,针对不同的 pre-training 任务,ERNIE 2.0 引入了 Task Embedding 来精细化地建模不同类型的任务。不同的任务用从 0 到 N 的 ID 表示,每个 ID 代表了不同的预训练任务。
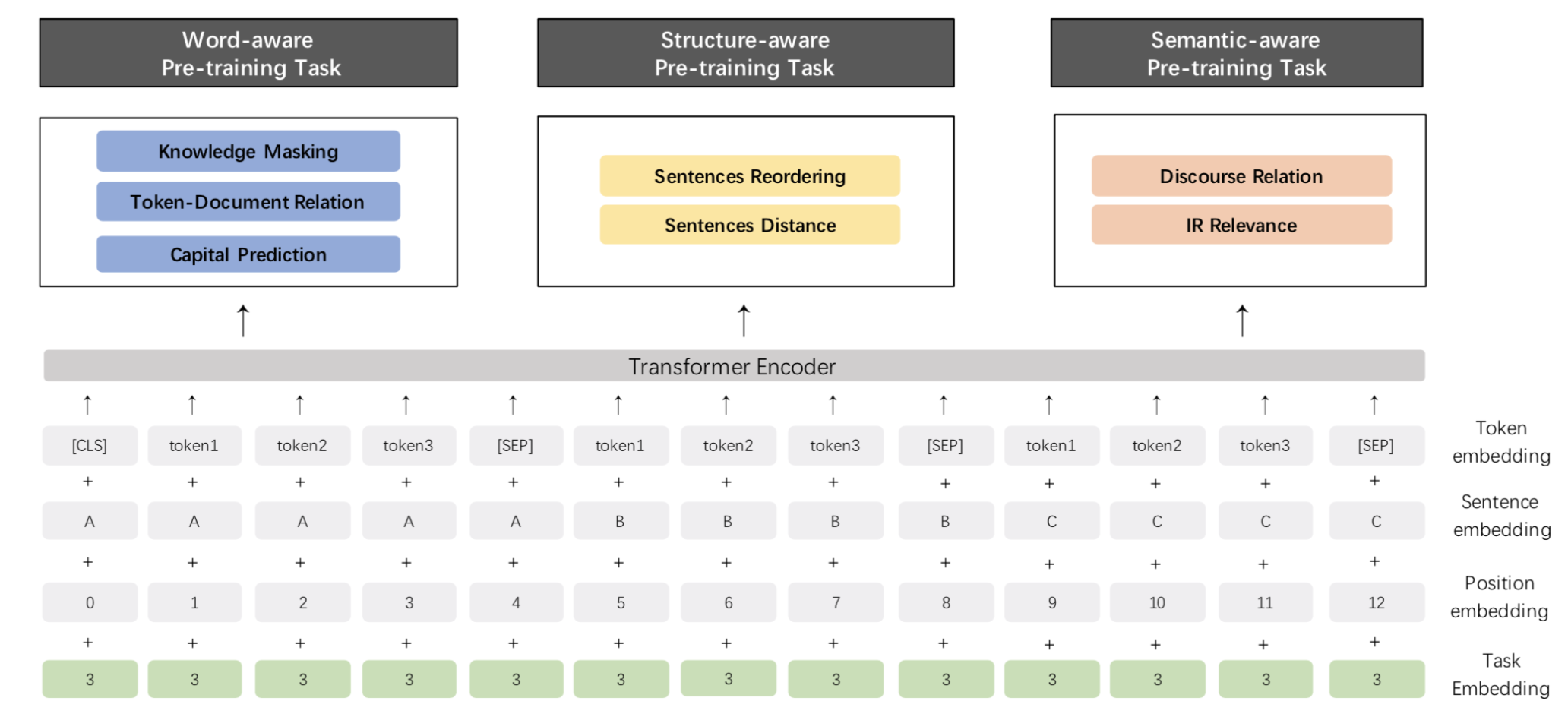
Word-aware Tasks
Knowledge Masking Task
- ERNIE 1.0 中已经引入的 phrase & named entity 知识增强 masking 策略。相较于 sub-word masking, 该策略可以更好的捕捉输入样本局部和全局的语义信息。
Capitalization Prediction Task
- 针对英文首字母大写词汇(如 Apple)所包含的特殊语义信息,我们在英文 Pre-training 训练中构造了一个分类任务去学习该词汇是否为大写。
Token-Document Relation Prediction Task
- 针对一个 segment 中出现的词汇,去预测该词汇是否也在原文档的其他 segments 中出现。
Structure-aware Tasks
Sentence Reordering Task
- 针对一个 paragraph (包含 M 个 segments),我们随机打乱 segments 的顺序,通过一个分类任务去预测打乱的顺序类别。
Sentence Distance Task
- 通过一个 3 分类任务,去判断句对 (sentence pairs) 位置关系 (包含邻近句子、文档内非邻近句子、非同文档内句子 3 种类别),更好的建模语义相关性。
Semantic-aware Tasks
Discourse Relation Task
- 通过判断句对 (sentence pairs) 间的修辞关系 (semantic & rhetorical relation),更好的学习句间语义。
IR Relevance Task
- 学习 IR 相关性弱监督信息,更好的建模句对相关性。
对比 ERNIE 1.0 和 ERNIE 2.0
Pre-Training Tasks
| 任务 | ERNIE 1.0 模型 | ERNIE 2.0 英文模型 | ERNIE 2.0 中文模型 |
|---|---|---|---|
| Word-aware | ✅ Knowledge Masking | ✅ Knowledge Masking ✅ Capitalization Prediction ✅ Token-Document Relation Prediction |
✅ Knowledge Masking |
| Structure-aware | ✅ Sentence Reordering | ✅ Sentence Reordering ✅ Sentence Distance |
|
| Semantic-aware | ✅ Next Sentence Prediction | ✅ Discourse Relation | ✅ Discourse Relation ✅ IR Relevance |
效果验证
中文效果验证
我们在 9 个任务上验证 ERNIE 2.0 中文模型的效果。这些任务包括:自然语言推断任务 XNLI;阅读理解任务 DRCD、DuReader、CMRC2018;命名实体识别任务 MSRA-NER (SIGHAN2006);情感分析任务 ChnSentiCorp;语义相似度任务 BQ Corpus、LCQMC;问答任务 NLPCC2016-DBQA 。任务的详情和效果会在如下章节中介绍。
自然语言推断任务
| 数据集
|
||
|---|---|---|
|
评估
指标
|
|
|
|
dev
|
test
|
|
|
BERT Base
|
78.1 | 77.2 |
|
ERNIE 1.0 Base
|
79.9 (+1.8) | 78.4 (+1.2) |
|
ERNIE 2.0 Base
|
81.2 (+3.1) | 79.7 (+2.5) |
|
ERNIE 2.0 Large
|
82.6 (+4.5) | 81.0 (+3.8) |
- XNLI
XNLI 是由 Facebook 和纽约大学的研究者联合构建的自然语言推断数据集,包括 15 种语言的数据。我们用其中的中文数据来评估模型的语言理解能力。[链接: https://github.com/facebookresearch/XNLI]阅读理解任务
| 数据集
|
DRCD | |||||||
|---|---|---|---|---|---|---|---|---|
|
评估
指标
|
|
f1-score
|
em
|
f1-score
|
em
|
f1-score
|
||
|
dev
|
dev
|
dev
|
test
|
dev
|
test
|
|||
| BERT Base | 59.5 | 73.1 | 66.3 | 85.9 | 85.7 | 84.9 | 91.6 | 90.9 |
| ERNIE 1.0 Base | 57.9 (-1.6) | 72.1 (-1.0) | 65.1 (-1.2) | 85.1 (-0.8) | 84.6 (-1.1) | 84.0 (-0.9) | 90.9 (-0.7) | 90.5 (-0.4) |
| ERNIE 2.0 Base | 61.3 (+1.8) | 74.9 (+1.8) | 69.1 (+2.8) | 88.6 (+2.7) | 88.5 (+2.8) | 88.0 (+3.1) | 93.8 (+2.2) | 93.4 (+2.5) |
| ERNIE 2.0 Large | 64.2 (+4.7) | 77.3 (+4.2) | 71.5 (+5.2) | 89.9 (+4.0) | 89.7 (+4.0) | 89.0 (+4.1) | 94.7 (+3.1) | 94.2 (+3.3) |
- DuReader
DuReader 是百度在自然语言处理国际顶会 ACL 2018 发布的机器阅读理解数据集,所有的问题、原文都来源于百度搜索引擎数据和百度知道问答社区,答案是由人工整理的。实验是在 DuReader 的单文档、抽取类的子集上进行的,训练集包含15763个文档和问题,验证集包含1628个文档和问题,目标是从篇章中抽取出连续片段作为答案。[链接: https://arxiv.org/pdf/1711.05073.pdf]- CMRC2018
CMRC2018 是中文信息学会举办的评测,评测的任务是抽取类阅读理解。[链接: https://github.com/ymcui/cmrc2018]- DRCD
DRCD 是台达研究院发布的繁体中文阅读理解数据集,目标是从篇章中抽取出连续片段作为答案。我们在实验时先将其转换成简体中文。[链接: https://github.com/DRCKnowledgeTeam/DRCD]命名实体识别任务
| 数据集
|
||
|---|---|---|
|
评估
指标
|
|
|
|
dev
|
test
|
|
| BERT Base | 94.0 | 92.6 |
| ERNIE 1.0 Base | 95.0 (+1.0) | 93.8 (+1.2) |
| ERNIE 2.0 Base | 95.2 (+1.2) | 93.8 (+1.2) |
| ERNIE 2.0 Large | 96.3 (+2.3) | 95.0 (+2.4) |
- MSRA-NER (SIGHAN2006)
MSRA-NER (SIGHAN2006) 数据集由微软亚研院发布,其目标是识别文本中具有特定意义的实体,包括人名、地名、机构名。情感分析任务
| 数据集
|
||
|---|---|---|
|
评估
指标
|
|
|
|
dev
|
test
|
|
| BERT Base | 94.6 | 94.3 |
| ERNIE 1.0 Base | 95.2 (+0.6) | 95.4 (+1.1) |
| ERNIE 2.0 Base | 95.7 (+1.1) | 95.5 (+1.2) |
| ERNIE 2.0 Large | 96.1 (+1.5) | 95.8 (+1.5) |
- ChnSentiCorp
ChnSentiCorp 是一个中文情感分析数据集,包含酒店、笔记本电脑和书籍的网购评论。问答任务
| 数据集
|
||||
|---|---|---|---|---|
|
评估
指标
|
|
|
||
|
dev
|
test
|
dev
|
test
|
|
| BERT Base | 94.7 | 94.6 | 80.7 | 80.8 |
| ERNIE 1.0 Base | 95.0 (+0.3) | 95.1 (+0.5) | 82.3 (+1.6) | 82.7 (+1.9) |
| ERNIE 2.0 Base | 95.7 (+1.0) | 95.7 (+1.1) | 84.7 (+4.0) | 85.3 (+4.5) |
| ERNIE 2.0 Large | 95.9 (+1.2) | 95.8 (+1.2) | 85.3 (+4.6) | 85.8 (+5.0) |
- NLPCC2016-DBQA
NLPCC2016-DBQA 是由国际自然语言处理和中文计算会议 NLPCC 于 2016 年举办的评测任务,其目标是从候选中找到合适的文档作为问题的答案。[链接: http://tcci.ccf.org.cn/conference/2016/dldoc/evagline2.pdf]语义相似度
| 数据集
|
||||
|---|---|---|---|---|
|
评估
指标
|
|
|
||
|
dev
|
test
|
dev
|
test
|
|
| BERT Base | 88.8 | 87.0 | 85.9 | 84.8 |
| ERNIE 1.0 Base | 89.7 (+0.9) | 87.4 (+0.4) | 86.1 (+0.2) | 84.8 |
| ERNIE 2.0 Base | 90.9 (+2.1) | 87.9 (+0.9) | 86.4 (+0.5) | 85.0 (+0.2) |
| ERNIE 2.0 Large | 90.9 (+2.1) | 87.9 (+0.9) | 86.5 (+0.6) | 85.2 (+0.4) |
* LCQMC 、BQ Corpus 数据集需要向作者申请,LCQMC 申请地址:http://icrc.hitsz.edu.cn/info/1037/1146.htm, BQ Corpus 申请地址:http://icrc.hitsz.edu.cn/Article/show/175.html
- LCQMC
LCQMC 是在自然语言处理国际顶会 COLING 2018 发布的语义匹配数据集,其目标是判断两个问题的语义是否相同。[链接: http://aclweb.org/anthology/C18-1166]- BQ Corpus
BQ Corpus 是在自然语言处理国际顶会 EMNLP 2018 发布的语义匹配数据集,该数据集针对银行领域,其目标是判断两个问题的语义是否相同。[链接: https://www.aclweb.org/anthology/D18-1536]英文效果验证
ERNIE 2.0 的英文效果验证在 GLUE 上进行。GLUE 评测的官方地址为 https://gluebenchmark.com/ ,该评测涵盖了不同类型任务的 10 个数据集,其中包含 11 个测试集,涉及到 Accuracy, F1-score, Spearman Corr,. Pearson Corr,. Matthew Corr., 5 类指标。GLUE 排行榜使用每个数据集的平均分作为总体得分,并以此为依据将不同算法进行排名。
GLUE - 验证集结果
| 数据集 | CoLA | SST-2 | MRPC | STS-B | QQP | MNLI-m | QNLI | RTE |
|---|---|---|---|---|---|---|---|---|
| 评测指标 | matthews corr. | acc | acc | pearson corr. | acc | acc | acc | acc |
| BERT Large | 60.6 | 93.2 | 88.0 | 90.0 | 91.3 | 86.6 | 92.3 | 70.4 |
| XLNet Large | 63.6 | 95.6 | 89.2 | 91.8 | 91.8 | 89.8 | 93.9 | 83.8 |
| ERNIE 2.0 Large | 65.4 (+4.8,+1.8) |
96.0 (+2.8,+0.4) |
89.7 (+1.7,+0.5) |
92.3 (+2.3,+0.5) |
92.5 (+1.2,+0.7) |
89.1 (+2.5,-0.7) |
94.3 (+2.0,+0.4) |
85.2 (+14.8,+1.4) |
我们使用单模型的验证集结果,来与 BERT/XLNet 进行比较。
GLUE - 测试集结果
| 数据集 | - | CoLA | SST-2 | MRPC | STS-B | QQP | MNLI-m | MNLI-mm | QNLI | RTE | WNLI | AX |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 评测指标 | score | matthews corr. | acc | f1-score/acc | spearman/pearson corr. | f1-score/acc | acc | acc | acc | acc | acc | matthews corr. |
| BERT Base | 78.3 | 52.1 | 93.5 | 88.9/84.8 | 85.8/87.1 | 71.2/89.2 | 84.6 | 83.4 | 90.5 | 66.4 | 65.1 | 34.2 |
| ERNIE 2.0 Base | 80.6 (+2.3) |
55.2 (+3.1) |
95.0 (+1.5) |
89.9/86.1 (+1.0/+1.3) |
86.5/87.6 (+0.7/+0.5) |
73.2/89.8 (+2.0/+0.6) |
86.1 (+1.5) |
85.5 (+2.1) |
92.9 (+2.4) |
74.8 (+8.4) |
65.1 | 37.4 (+3.2) |
| BERT Large | 80.5 | 60.5 | 94.9 | 89.3/85.4 | 86.5/87.6 | 72.1/89.3 | 86.7 | 85.9 | 92.7 | 70.1 | 65.1 | 39.6 |
| ERNIE 2.0 Large | 83.6 (+3.1) |
63.5 (+3.0) |
95.6 (+0.7) |
90.2/87.4 (+0.9/+2.0) |
90.6/91.2 (+4.1/+3.6) |
73.8/90.1 (+1.7/+0.8) |
88.7 (+2.0) |
88.8 (+2.9) |
94.6 (+1.9) |
80.2 (+10.1) |
67.8 (+2.7) |
48.0 (+8.4) |
由于 XLNet 暂未公布 GLUE 测试集上的单模型结果,所以我们只与 BERT 进行单模型比较。上表为ERNIE 2.0 单模型在 GLUE 测试集的表现结果。
ERNIE tiny
为了提升ERNIE模型在实际工业应用中的落地能力,我们推出ERNIE-tiny模型。
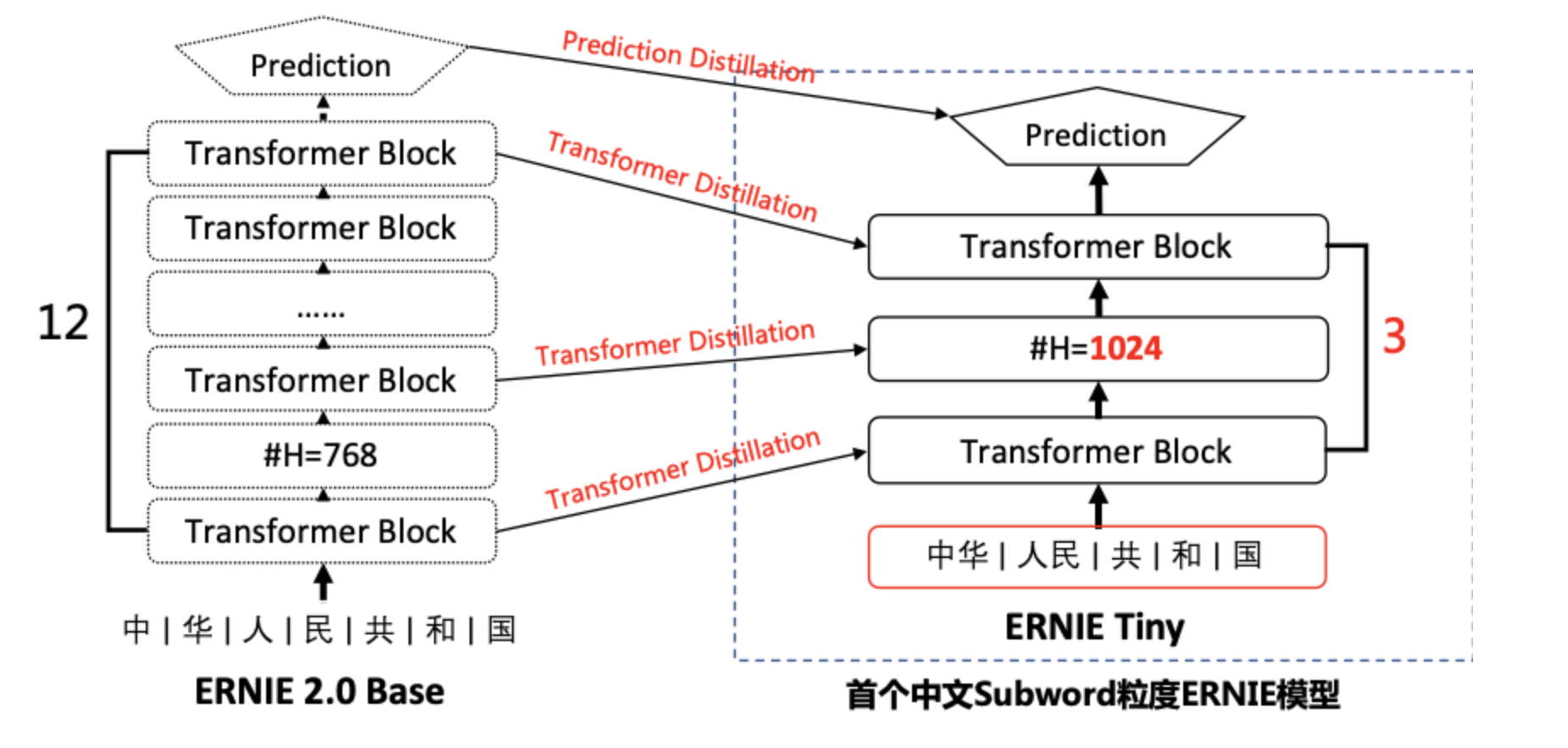
ERNIE-tiny作为小型化ERNIE,采用了以下4点技术,保证了在实际真实数据中将近4.3倍的预测提速。
- 浅:12层的ERNIE Base模型直接压缩为3层,线性提速4倍,但效果也会有较大幅度的下降;
- 胖:模型变浅带来的损失可通过hidden size的增大来弥补。由于fluid inference框架对于通用矩阵运算(gemm)的最后一维(hidden size)参数的不同取值会有深度的优化,因为将hidden size从768提升至1024并不会带来速度线性的增加;
- 短:ERNIE Tiny是首个开源的中文subword粒度的预训练模型。这里的短是指通过subword粒度替换字(char)粒度,能够明显地缩短输入文本的长度,而输入文本长度是和预测速度有线性相关。统计表明,在XNLI dev集上采用subword字典切分出来的序列长度比字表平均缩短40%;
- 萃:为了进一步提升模型的效果,ERNIE Tiny扮演学生角色,利用模型蒸馏的方式在Transformer层和Prediction层去学习教师模型ERNIE模型对应层的分布或输出,这种方式能够缩近ERNIE Tiny和ERNIE的效果差异。
Benchmark
ERNIE Tiny轻量级模型在公开数据集的效果如下所示,任务均值相对于ERNIE Base只下降了2.37%,但相对于“SOTA Before BERT”提升了8%。在延迟测试中,ERNIE Tiny能够带来4.3倍的速度提升 (测试环境为:GPU P4,Paddle Inference C++ API,XNLI Dev集,最大maxlen=128,测试结果10次均值)
| model | XNLI(acc) | LCQCM(acc) | CHNSENTICORP(acc) | NLPCC-DBQA(mrr/f1) | Average | Latency |
|---|---|---|---|---|---|---|
| SOTA-before-ERNIE | 68.3 | 83.4 | 92.2 | 72.01/- | 78.98 | - |
| ERNIE2.0-base | 79.7 | 87.9 | 95.5 | 95.7/85.3 | 89.70 | 633ms(1x) |
| ERNIE-tiny-subword | 75.1 | 86.1 | 95.2 | 92.9/78.6 | 87.33 | 146ms(4.3x) |
ERNIE-Gen
基本介绍
- ERNIE-GEN是针对通用生成任务的预训练模型,在4类生成任务的5个英文公开数据集上超过微软 MASS 和 UNILM、Facebook BART、谷歌 T5 等参数规模更大、预训练数据更多的竞品模型取得SOTA效果,在中文任务上较通用ERNIE模型提升显著。
- 目前文心提供ERNIE-GEN中文模型。
原理介绍
ERNIE-GEN的核心技术和创新主要体现在以下三个方面:
- 针对encoder-decoder 联合建模能力较弱的问题,提出了多片段-多粒度预训练采样策略,增强了 encoder 和 decoder 的交互。
- 针对seq2seq 曝光偏差问题, 提出基于 Infilling 机制的 pretrain-finetune 框架, 并进一步引入噪声增强策略。
- 考虑到人类的思考模式,提出将 span 预测引入生成预训练中,增强语义学习。
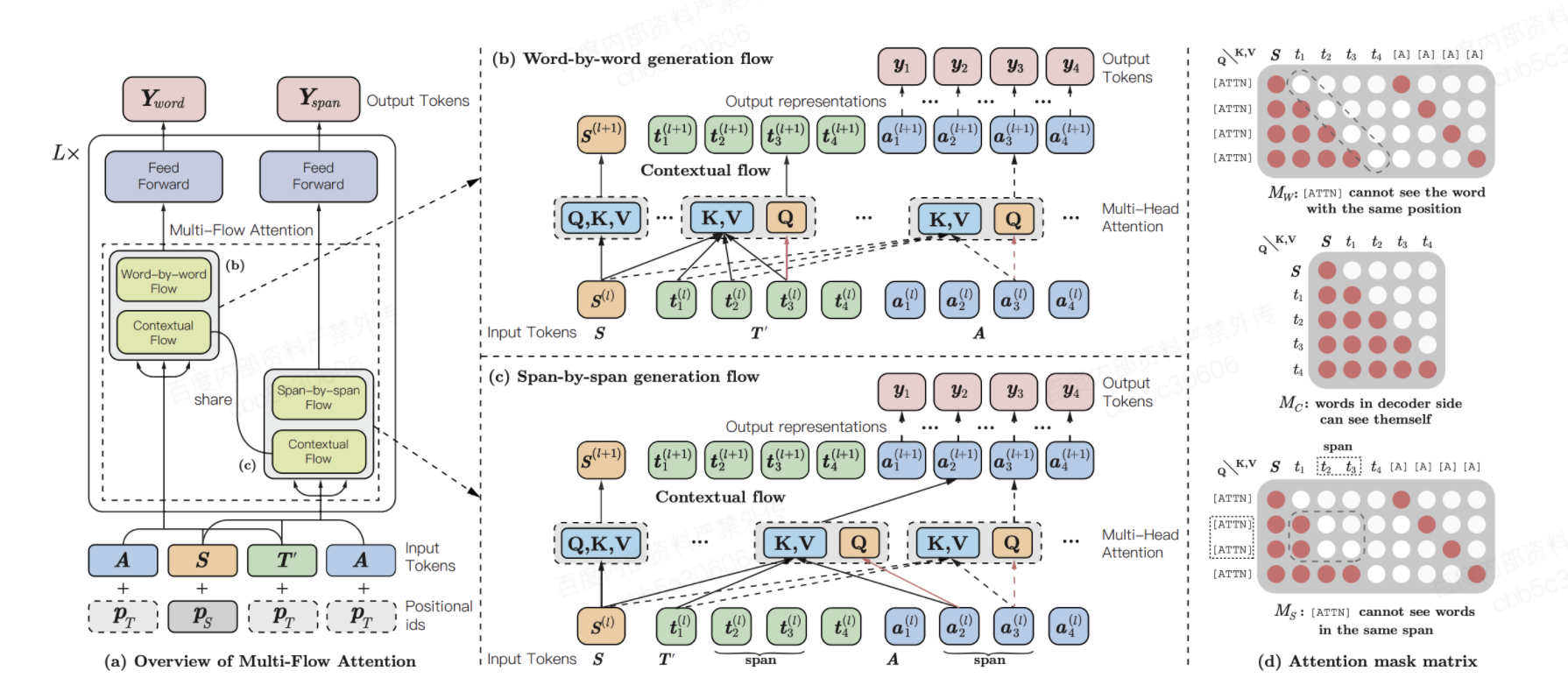
模型效果
ERNIE-Word
基本介绍
- ERNIE-Word是利用百度研发的先进中文预训练语言模型ERNIE产出的静态词向量。
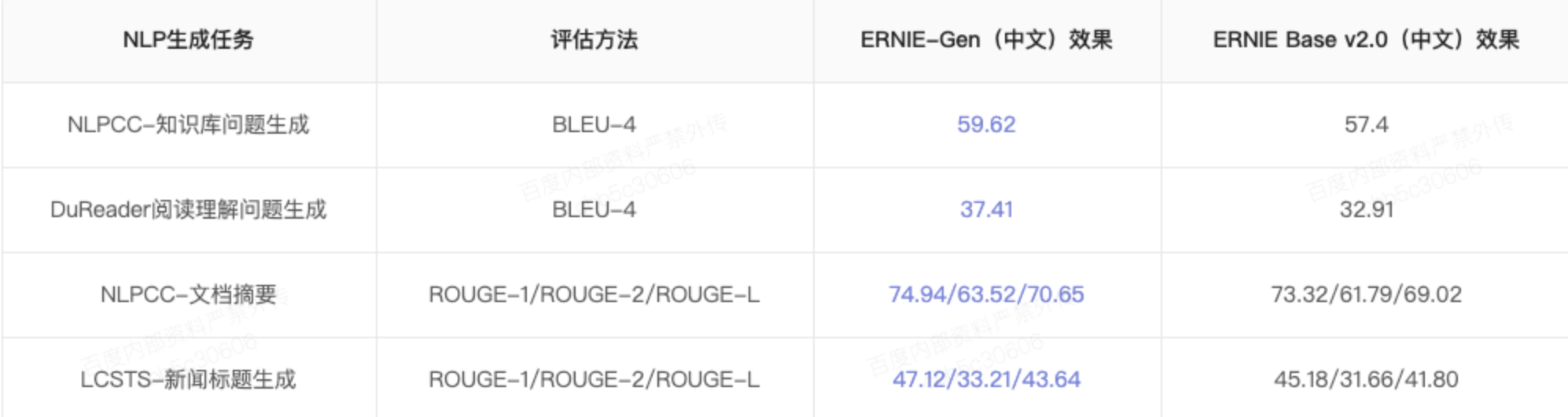
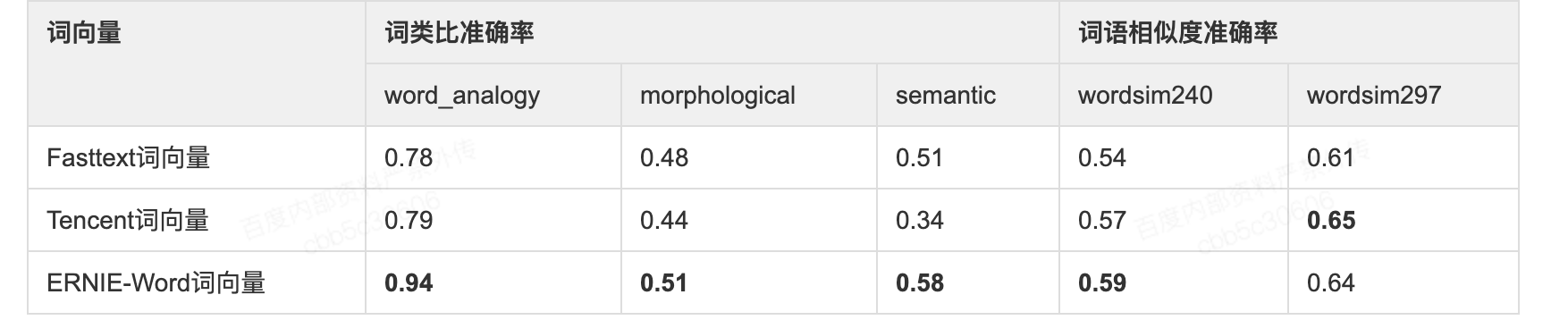
- 其充分利用ERNIE编码的丰富语义信息,将ERNIE与词向量训练相结合,产出了收敛更快、效果更好的静态词向量,在多个公开的词向量内部任务评价上达到业界领先的效果。详细对比如下表所示。
- ERNIE-Word在不同的NLP任务中均可以作为预训练词向量使用,有助于开发者提升模型效果,特别是浅层模型或训练数据量较少的情况下,建议使用预训练ERNIE-Word词向量
效果验证
- 我们选择公开的review情感分析数据进行实验,其中训练集仅3950条,较适合验证在训练数据量较少的情况下,使用预训练ERNIE-Word词向量带来的提升。通过重复5次实验,结果如下:
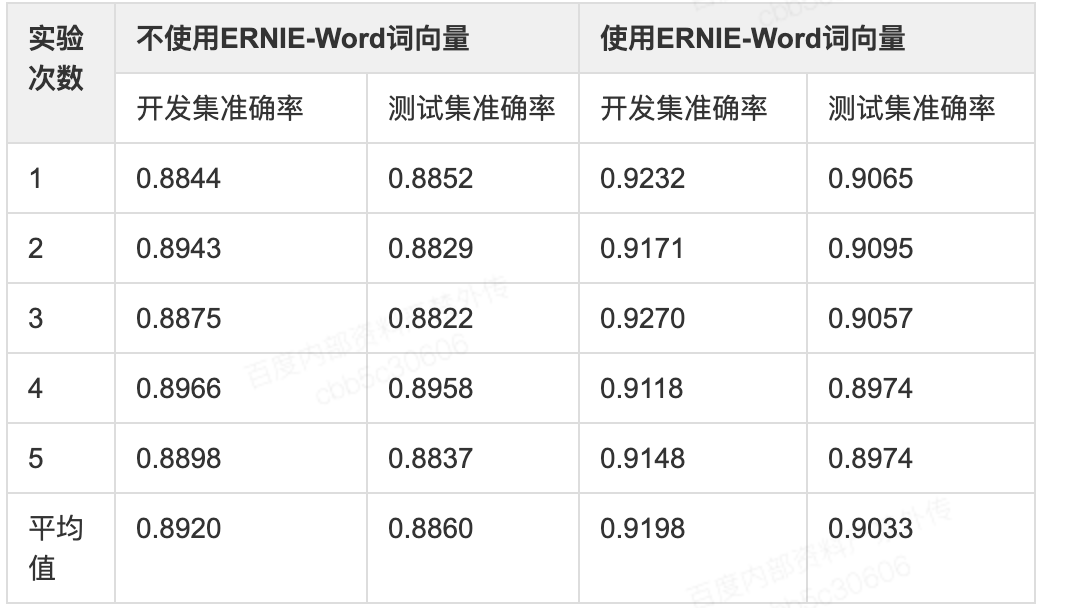
- 可以看到使用ERNIE-Word有较稳定的提升,在开发集上平均提升2.78%,在测试集上平均提升1.73%,因此建议开发者在训练数据量较少的情况下尝试使用预训练ERNIE-Word词向量。
- 模型效果

ERNIE-Health
基本介绍
- 为提升ERNIE在医疗文本领域的效果;在海量医疗文本数据上进行有效预训练,并且在现有ERNIE预训练策略上增加了针对医疗问答匹配任务与定制医疗词汇Mask策略,并在部分开源医疗数据进行了验证
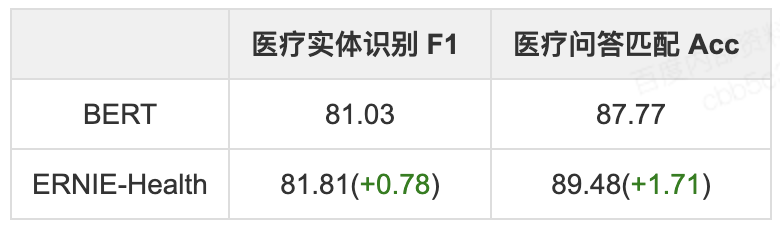
- 医疗实体识别:CCKS2019评测任务一,主要目标是对于给定的一组电子病历纯文本文档,任务的目标是识别并抽取出与医学临床相关的实体提及,并将它们归类到预定义类别,比如疾病、治疗、检查检验等。
- 医疗问答匹配:CHIP2019评测任务二,主要目标是针对中文的疾病问答数据,进行病种间的迁移学习。具体而言,给定来自5个不同病种的问句对,要求判定两个句子语义是否相同或者相近。
ERNIE-Sentiment
基本介绍
- 相比于通用预训练中主要关注事实型文本(如新闻、百科 等),情感分析更侧重于分析主观型文本中蕴涵的情感和观点,因此有必要专门面向情感分析研发情感预训练模型。
- 为此,我们提出了基于情感知识增强的情感预训练算法 SKEP。此算法采用无监督方法自动挖掘情感知识,然后利用情感知识构建预训练目标,从而让机器学会理解情感语义。该方法被NLP会议ACL 2020收录,论文地址[SKEP: Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis](https://arxiv.org/abs/2005.05635]。
ERNIE-Law
基本介绍
- 为提升ERNIE在法律文本领域的效果,我们基于通用ERNIE训练了法律领域ERNIE;
- 法律文本一般可分为刑事类和民事类两大类,因此我们分别训练了刑事法律模型(ERNIE_Law_penal)与民事法律模型(ERNIE_Law_civil);
- 其相关训练与预测性能指标与ERNIE-Base相同。
- 在法律模型的训练过程中,我们在通用ERNIE的基础上新增多粒度案由分类预训练任务等,进一步提高了ERNIE在法律文本领域的效果。
效果验证
- 模型在评测数据上效果如下:

- 罪名预测:CAIL2018评测任务一
- 法条推荐:CAIL2018评测任务二
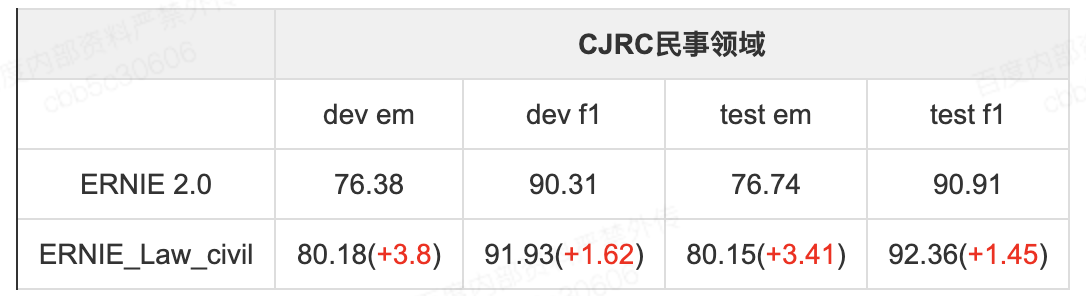
- CJRC民事领域:CAIL2019评测任务一(阅读理解)选取民事领域(domain=civil)且qa类型非是否类语料部分
ERNIE-IE
基本介绍
ERNIE-IE预训练模型将人工构造的大规模知识图谱中蕴含的知识注入ERNIE预训练模型,使模型不仅可以学习到文本中蕴含的语义信息,还可以记住更多的事实知识,提高ERNIE预训练模型对知识的敏感度,在知识类任务上获得显著收益
原理介绍
- 为了使得ERNIE可以学习到图谱中的结构化信息和实体语义信息,我们将采样的的图谱子图序列化为文本,生成对应的的Mask矩阵和相对位置矩阵(以便控制ERNIE学习结构信息),共有两类隐式图(二叉树,线性表)
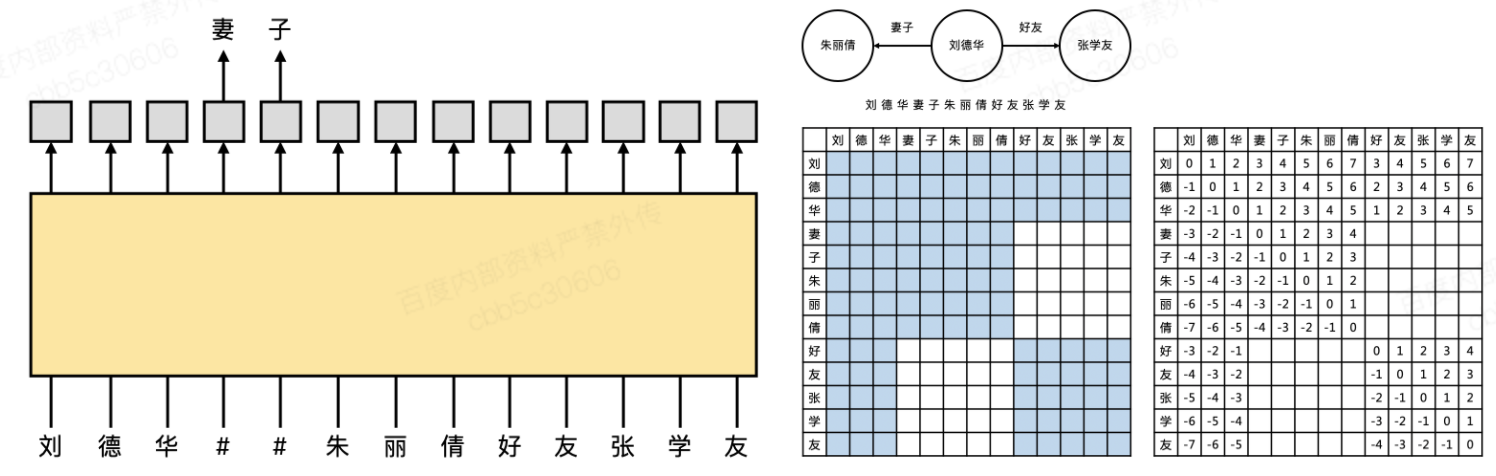
- 另外为了使模型获取文本信息和结构信息的对齐,我们设计了知识抽取任务将三元组与相关文本对齐
- 为了使得ERNIE可以更加清晰的学习结构信息,我们设计了双向相对位置编码及层次编码,使模型可以更清晰的学习知识
模型效果

ERNIE-ErrorCorrection
基本介绍
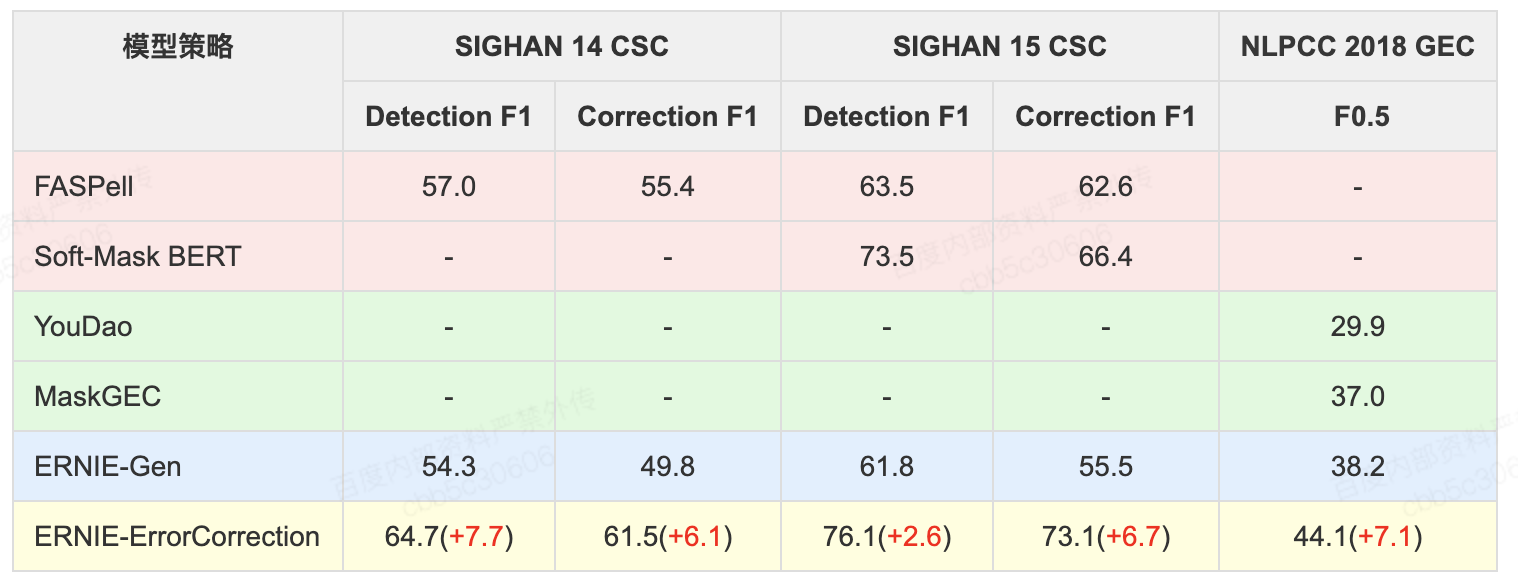
- 文本错误在人们的日常工作中是常见,有效识别和纠正这些错误,对于理解语言非常重要;ERNIE-ErrorCorrection基于大规模预训练模型ERNIE强大的语言理解能力,创新性的引入了针对文本纠错场景的训练任务和特征,在多个纠错任务上效果显著
原理介绍
- ERNIE-ErrorCorrection
- 基于大规模预训练模型ERNIE强大的语言理解能力;设计了文本纠错预训练任务(对训练样本中人为引入字音字形相近的错误或者错误表述,使模型进行纠错恢复);除此之外,我们还设计了针对纠错任务的字音字形特征,进一步提升模型的文本纠错能力
模型效果
ERNIE使用
- ernie网络配置超参数说明
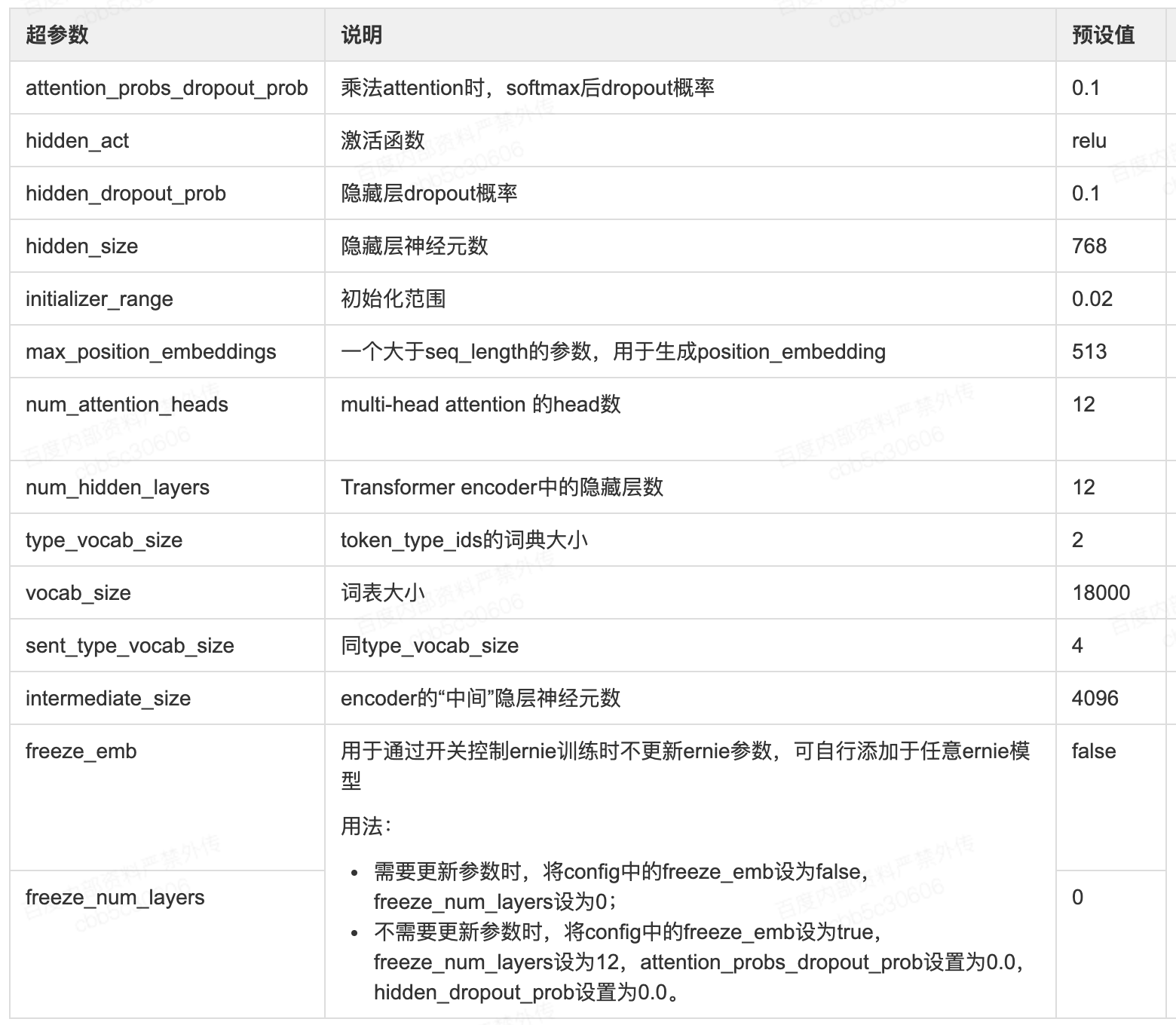
-
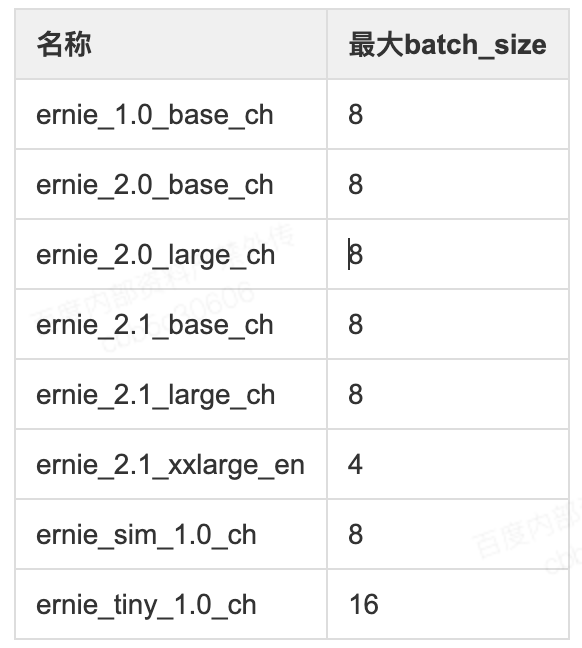
不同版本ERNIE建议的batch_size大小
- 以v100机器为例,不同版本ernie所推荐的最大batch_size如下所示。