

数据蒸馏
更新时间:2022-01-25
任务简介
- 在ERNIE强大的语义理解能力背后,是需要同样强大的算力才能支撑起如此大规模模型的训练和预测。很多工业应用场景对性能要求较高,若不能有效压缩则无法实际应用。
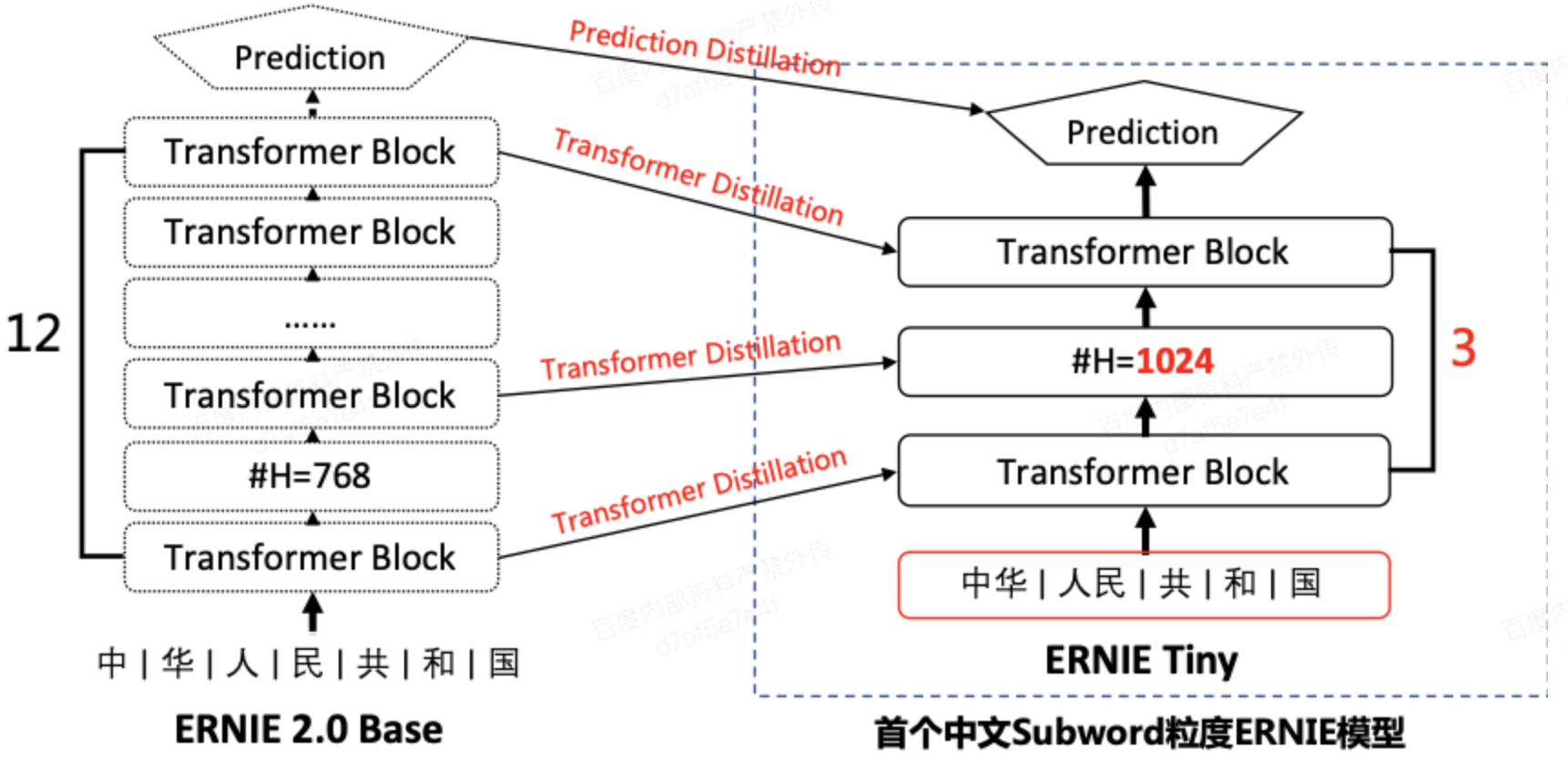
- 因此,如上图所示,我们基于数据蒸馏技术构建了ERNIE Slim数据蒸馏系统。
- 其原理是通过数据作为桥梁,将ERNIE模型的知识迁移至小模型,以达到损失很小的效果却能达到上千倍的预测速度提升的效果。
ERNIE数据蒸馏三步
- Step 1. 使用ERNIE模型对输入标注数据对进行fine-tune,得到Teacher Model
-
Step 2. 使用ERNIE Service对以下无监督数据进行预测:
(1)用户提供的大规模无标注数据,需与标注数据同源
(2)对标注数据进行数据增强,具体增强策略见下节
(3)对无标注数据和数据增强数据进行一定比例混合
- Step 3. 使用步骤2的数据训练出Student Model
数据增强
-
目前采用三种数据增强策略策略,对于不用的任务可以特定的比例混合。三种数据增强策略包括:
- (1)添加噪声:对原始样本中的词,以一定的概率(如0.1)替换为”UNK”标签
- (2)同词性词替换:对原始样本中的所有词,以一定的概率(如0.1)替换为本数据集中随机一个同词性的词
- (3)N-sampling:从原始样本中,随机选取位置截取长度为m的片段作为新的样本,其中片段的长度m为0到原始样本长度之间的随机值
快速开始
- 代码路径:
textone-public/tasks/ernie_slim - 代码结构说明
以下是本项目主要代码结构及说明:
.
├── __init__.py
├── env.sh ## 环境变量配置脚本
├── run_with_json.py ## 只依靠json进行模型训练的入口脚本
├── run_infer.py ## 只依靠json进行模型预测的入口脚本
├── run_distill.sh ## 离线蒸馏的入口脚本
├── download_data.sh ## chnsenticorp的增强数据下载脚本
├── examples ## 各典型网络的json配置脚本
│ ├── ernie1.0_config.json
│ ├── model_cnn.json
│ ├── model_ernie1.0_infer.json
│ └── model_ernie1.0.json
└── dict ## 示例词表文件夹
├── vocab_cnn.txt
└── vocab_ernie1.0.txt数据准备
- 我们采用上述3种增强策略制作了chnsenticorp的增强数据。
- 注:数据集(包含词表)均为utf-8格式。
- 增强后的数据为原训练数据的10倍(96000行),可以从这里下载,或者运行下面的脚本进行下载。
sh ./download_data.sh- 下载后的数据目录结构如下所示:
.
└── chnsenticorp
├── student ## 学生模型数据集
│ ├── dev
│ │ └── part.0
│ ├── teacher_vocab.txt
│ ├── train
│ │ └── part.0
│ ├── unsup_train_aug ## 未标注增强训练数据
│ │ └── part.0
│ └── vocab.txt
└── teacher ## 教师模型数据集
├── dev
│ └── part.0
├── train
│ └── part.0
└── vocab.txt学生模型数据集
训练集/验证集
- 学生模型训练集和验证集的数据格式相同,如下所示。数据分为两列,列与列之间用\t进行分隔。第一列为文本,第二列为标签。
房间 太 小 。 其他 的 都 一般 。 。 。 。 。 。 。 。 。 0
LED屏 就是 爽 , 基本 硬件 配置 都 很 均衡 , 镜面 考 漆 不错 , 小黑 , 我喜欢 。 1
差 得 要命 , 很大 股霉味 , 勉强 住 了 一晚 , 第二天 大早 赶紧 溜。 0未标注增强训练数据
- 未标注增强训练数据无需进行标签预占位,其格式如下所示:
USB接口 只有 2个 , 太 少 了 点 , 不能 接 太多 外 接 设备 ! 表面 容易 留下 污垢 ! USB接口 只有 2个 , 太 少 了 点 , 不能 接 很多 外 接 设备 ! 表面 容易 留下 污垢 !
平时 只 用来 工作 , 上 上网 , 挺不错 的 , 没有 冗余 的 功能 , 样子 也 比较 正式 ! 平时 只 用来 工作 , 上 上网 , 挺好 的 , 没有 多余 的 功能 , 样子 也 比较 正式 !
还 可以 吧 , 价格 实惠 宾馆 反馈 2008年4月17日 : 谢谢 ! 欢迎 再次 入住 其士 大酒店 。 还 可以 吧 , 价格 便宜 宾馆 反馈 2008年4月17日 : 谢谢 ! 欢迎 再次 入住 其士 大酒店 。词表
- 学生模型词表为一列词。若用户自备词表,需保持前七项与示例词表一致。部分词表示例如下所示:
[PAD]
[UNK]
[SEP]
[MASK]
[UNK]
[CLS]
[UNUSED]
,
的
。
了教师模型数据集
训练集/验证集
- 学生模型训练集和验证集的数据格式相同,如下所示。数据分为两列,列与列之间用\t进行分隔。第一列为文本,第二列为标签。
房间 太 小 。 其他 的 都 一般 。 。 。 。 。 。 。 。 。 0
LED屏 就是 爽 , 基本 硬件 配置 都 很 均衡 , 镜面 考 漆 不错 , 小黑 , 我喜欢 。 1
差 得 要命 , 很大 股霉味 , 勉强 住 了 一晚 , 第二天 大早 赶紧 溜。 0词表
- 教师模型词表为一列词。若用户自备词表,需保持前六项与示例词表一致。部分词表示例如下所示:
[PAD]
[UNK]
[SEP]
[MASK]
[UNK]
[CLS]
,
的
、
一训练第一个模型
离线蒸馏
- 离线蒸馏指的是先通过训练好的ERNIE模型预测出无监督数据的label,然后student模型去学习这些label。
- 若希望通过开关控制ernie训练时不更新ernie参数,请参考ernie网络配置超参数说明中关于freeze_emb和freeze_num_layers的说明。
-
以本任务提供的示例配置为例,离线蒸馏分为以下几个步骤:
- 请使用以下命令在../model_files/中通过对应脚本下载ernie_1.0_base模型参数文件,其对应配置文件ernie_1.0_base_ch_config.json和词表vocab_ernie_1.0_base_ch.txt分别位于../model_files/目录下的config/和dict/文件夹,用户无需更改;
# ernie_1.0_base 模型下载 # 进入model_files目录 cd ../model_files/ # 运行下载脚本 sh download_ernie_1.0_base_ch.sh- 请在./env.sh中根据提示配置相应环境变量的路径
- 基于示例的数据集,可以运行以下命令开始离线蒸馏;
# ERNIE Slim 离线蒸馏 # 需要提前参照env.sh进行环境变量配置,在当前shell内去读取 source env.sh # 基于ernie_1.0_base的离线蒸馏。 sh ./run_distill.sh- 训练运行的日志会自动保存在./log/test.log文件中。
蒸馏过程说明
run_distill.sh脚本会进行前述的三步:
- 在任务数据上Fine-tune;
- 加载Fine-tune好的模型对增强数据进行打分;
- 使用Student模型进行训练。脚本采用hard-label蒸馏,在第二步中将会直接预测出ERNIE标注的label。
run_distill.sh脚本涉及两个 json 文件:
- ./examples/model_ernie1.0.json,该文件负责 finetune 以及预测 teacher 模型。
- ./examples/model_cnn.json,负责student模型的训练。
- 事先构造好的增强数据放在./distill/chnsenticorp/student/unsup_train_aug
- 在脚本的第二步中,使用 ./examples/model_ernie1.0_infer.json 进行预测:脚本从标准输入获取明文输入,并将打分输出到标准输出。用这种方式对数据增强后的无监督训练预料进行标注。最终的标注结果放在 ./distill/chnsenticorp/student/train/part.1文件中。标注结果包含两列, 第一列为明文,第二列为标注label。
- 在第三步开始student模型的训练,其训练数据放在 distill/chnsenticorp/student/train/ 中,part.0 为原监督数据 part.1 为 ERNIE 标注数据。
- 注:如果用户已经拥有了无监督数据,则可以将无监督数据放入 distill/chnsenticorp/student/unsup_train_aug 即可。
效果验证
- 我们将实际应用场景分类为两种:用户提供“无标注数据”和用户未提供“无标注数据”(通过数据增强生成数据)。
Case#1 用户提供“无标注数据”
| 模型 | 评论低质识别【分类|ACC】 | 中文情感【分类|ACC】 | 问题识别【分类|ACC】 | 搜索问答匹配【匹配|正逆序】 |
|---|---|---|---|---|
| ERNIE-Finetune | 90.6% | 96.2% | 97.5% | 4.25 |
| 非ERNIE基线(BOW) | 80.8% | 94.7% | 93.0% | 1.83 |
| + 数据蒸馏 | 87.2% | 95.8% | 96.3% | 3.30 |
Case#2 用户未提供“无标注数据”(通过数据增强生成数据)
| 模型 | ChnSentiCorp |
|---|---|
| ERNIE-Finetune | 95.4% |
| 非ERNIE基线(BOW) | 90.1% |
| + 数据蒸馏 | 91.4% |
| 非ERNIE基线(CNN) | 91.6% |
| + 数据蒸馏 | 92.4% |
| 非ERNIE基线(LSTM) | 91.2% |
| + 数据蒸馏 | 93.9% |