

8.明厨亮灶厨师帽识别
项目说明
业务背景
近年来,为了提升厨房管理水平,降低食品安全隐患,各地都在开展“明厨亮灶”行动,由餐饮服务提供者采用透明玻璃、视频等方式,向社会公众展示餐饮服务相关过程,从而引导公众参与到厨房监督中来,加强餐饮从业人员对于厨房工作规范的重视程度。
业务难点
基于摄像头监控和实时视频实时展示的厨房管理透明化只是“明厨亮灶”第一步。食品安全管理者还希望升级版的“明厨亮灶”能够基于摄像头来全面识别并纠正厨房中的不规范操作。对餐饮服务企业而言,雇用全职食品安全监督员的成本很高;即便安排了专人看管,也无法做到面面俱到,难以对全部不规范行为进行识别和纠正。 通过引入AI模型进行智能分析,从而让布设在厨房中的摄像头“聪明”起来,能够自动识别分析出厨房中的人员穿戴是否规范、操作是否正确、卫生是否良好等信息,并加以告警、记录,从而满足上述升级版“明厨亮灶”需求。然而,对于餐饮服务企业而言,招募专业算法工程师、采购GPU服务器、招募部署运维工程师的成本会更高,还会存在研发时间长,模型效果难以保障的问题。
解决思路
为帮助企业快速、低成本的将AI技术应用于升级版“明厨亮灶”,飞桨EasyDL提供了零门槛、高精度的AI建模能力,帮助企业轻松构建AI模型,并快速部署至多种运行环境。基于飞桨EasyDL,企业仅需安排一名普通业务人员,利用业余时间,即可在2-3周内从0到1训练出可用于升级版“明厨亮灶”的厨师帽识别模型,并应用到厨房场景的智能视频分析业务中。
在模型训练方面,上述业务对应图像领域的物体检测AI模型。在训练之前,先基于真实场景下的摄像头获取视频,通过抽帧方式采集足量图片样本,并进行正确标注。数据集准备完毕后,使用EasyDL进行物体检测模型训练,并根据评估结果持续优化模型,最终达到应用需求。
在模型部署方面,可集合视频路数、网络带宽、业务实时性要求、经费预算等因素来选择合适的部署方式。如果是小型餐饮服务企业、本地视频路数较少、业务实时性要求一般等情况,可采用公有云API的部署方式,直接将AI模型部署在公有云上,实际业务应用时可将本地视频进行抽帧采样后调用云端API,并获取分析结果。如果是大型餐饮服务企业、本地视频路数较多、业务实时性要求高等情况,可采用端云协同的部署方式,将AI模型部署在智能摄像头、边缘计算盒等设备上,摄像头采集的视频可直接进行处理和分析,并将分析结果及少量视频、图片传回云端。
在智能应用方面,企业可基于AI模型建设“明厨亮灶”的智能应用。以公有云API部署形式为例,该智能应用一般包括监控视频采集、视频处理、模型调用、实时告警、视频留存、统计分析等模块功能,并通过调用公有云AI模型服务来实现AI智能应用。智能应用可部署在本地,也可部署在公有云。下图是智能应用部署在本地的系统架构示意。
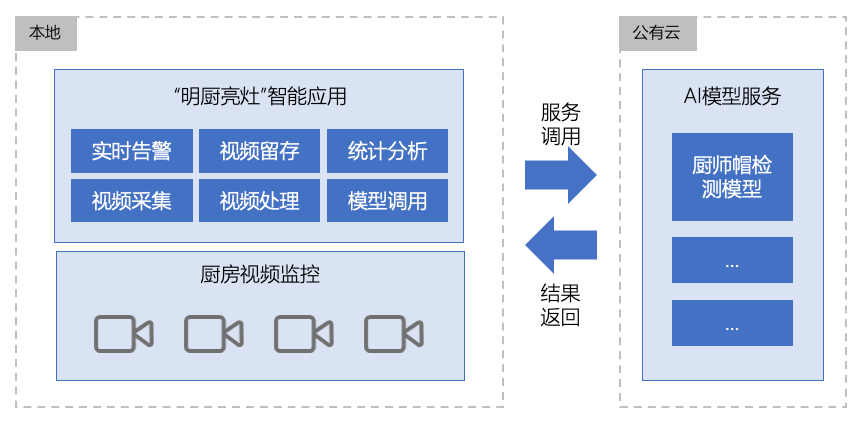
数据准备
数据采集
客户的实际场景是基于厨房摄像头视频数据来进行厨师帽佩戴行为识别。因此,前期采集训练数据时,需要从厨房摄像头视频数据中获取样本,需包含厨师帽佩戴、未佩戴情况下的足量图片,尽量覆盖不同类型的厨师帽,且尽量覆盖不同角度、距离、光照等条件,与厨房的实际摄像条件相符,这样才能保证训练出来的模型真实可用。网络图片与真实场景差异较大,一般情况下不建议采用。
厨师帽正常佩戴的图片示例如下:

数据导入
采集完毕可以根据您的使用习惯选择不同的导入方式来上传数据。可直接上传图片;也可将图片打包成zip压缩包上传;还可先将图片上传到其他网络地址(例如:百度网盘),然后拷贝链接上传。
数据标注
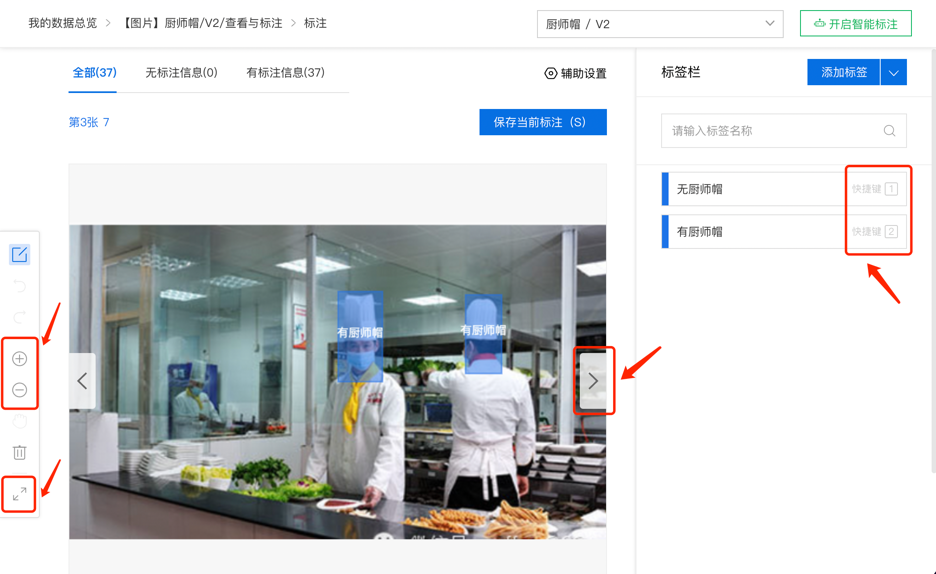
厨师帽识别模型输出的信息是图片中是否有佩戴、未佩戴厨师帽的行为,以及具体的人体头部位置,对应物体检测任务。因此,需选择图像-物体检测标注模板,并使用矩形框对佩戴、未佩戴厨师帽的人体头部位置进行标注。示例如下:
 在标注过程中,可充分利用EasyData数据服务所提供的各类功能来提升标注效率。可使用左侧工具栏的放大/缩小工具,并可点击全屏按钮,以变化可视范围,便于进行大/小目标的标注。不同标签都会默认生成数字快捷键,画框后点击数字即可完成标签选定。标注完成后可直接点击键盘右向肩头按键,将会自动保存并切换至下张图片。
在标注过程中,可充分利用EasyData数据服务所提供的各类功能来提升标注效率。可使用左侧工具栏的放大/缩小工具,并可点击全屏按钮,以变化可视范围,便于进行大/小目标的标注。不同标签都会默认生成数字快捷键,画框后点击数字即可完成标签选定。标注完成后可直接点击键盘右向肩头按键,将会自动保存并切换至下张图片。
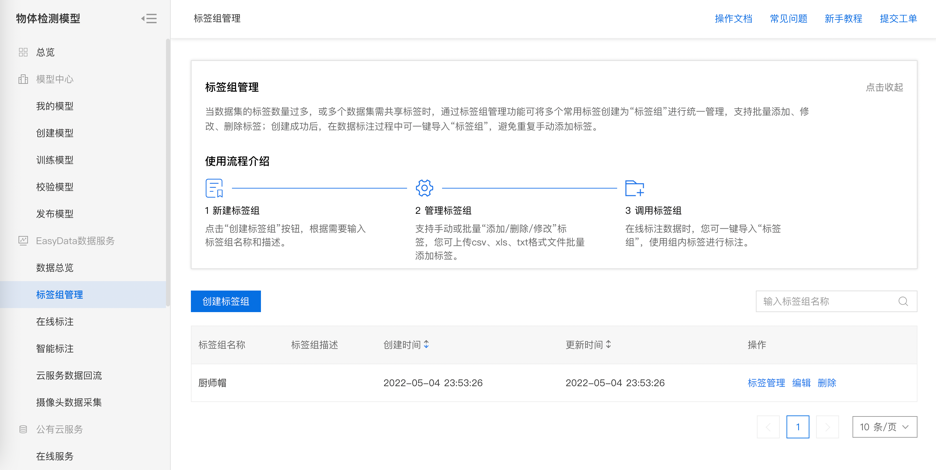
 对常用标签,可在标签组中进行管理,并在多次标注中重复使用。
对常用标签,可在标签组中进行管理,并在多次标注中重复使用。
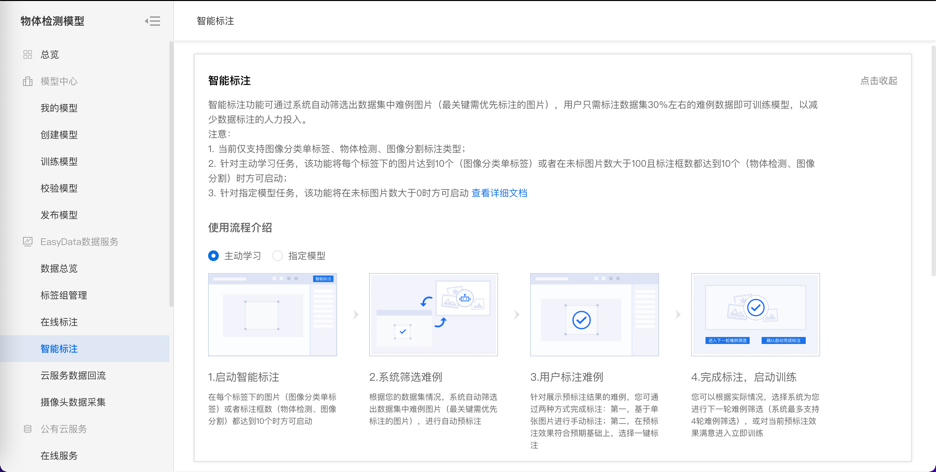
 如果标注图片较多,还可使用智能标注功能,可通过系统自动筛选出数据集中难例图片(最关键需优先标注的图片),用户只需标注数据集30%左右的难例数据即可训练模型,以减少数据标注的人力投入。
如果标注图片较多,还可使用智能标注功能,可通过系统自动筛选出数据集中难例图片(最关键需优先标注的图片),用户只需标注数据集30%左右的难例数据即可训练模型,以减少数据标注的人力投入。
模型训练
选择任务类型并创建模型
厨师帽识别对应物体检测模型,因此需选择物体检测任务类型。点击创建模型,根据您的业务需要来为模型自定义命名,如:厨师帽识别。
选择部署方式
如果您的业务模式是将视频上传至云端进行推理分析,则部署方式可选择公有云部署或EasyEdge本地部署-服务器。公有云部署的优势是部署较为便利,可一键发布为公有云服务;EasyEdge本地部署-服务器的优势是可下载部署包并部署至本地服务器,实现私有云服务;这两种部署方式共同的劣势是需要占用较大带宽用于视频传输,且推理计算将集中在公有云或私有云服务器,计算负荷较大。
对于智能视频分析业务而言,如果存在视频路数较少、业务实时性要求低的情况,可采用公有云部署或本地服务器部署的形式。在更多情况下,我们建议智能视频分析采用端云协同模式,也就是在边缘节点上直接进行视频分析,并将分析后的结构化数据回传至云端,则部署方式可选择EasyEdge本地部署,并根据您所使用的硬件设备来进一步选择通用小型设备或专项适配硬件。该部署方式的优势在于无需将视频回传至云端,可直接在边缘侧进行推理计算,不仅带宽占用低,计算压力也分散至各边缘节点,业务实时性更佳。

选择算法
可以选择高精度、均衡或高性能算法。其中,高精度算法侧重于保障模型效果,可通俗理解为模型更准,但模型体积相对更大,计算速度相对更慢,资源消耗也相对更多;而高性能算法侧重于保障模型性能,可通俗理解为模型体积更小、速度更快,或模型所占用的资源更少;均衡算法则介于两者中间。如果您更关注模型准确性,或硬件资源较为充足,建议选择高精度算法;如果您的硬件资源较为紧张,或更关注模型速度、计算资源利用效率,则建议选择高性能算法。

效果优化
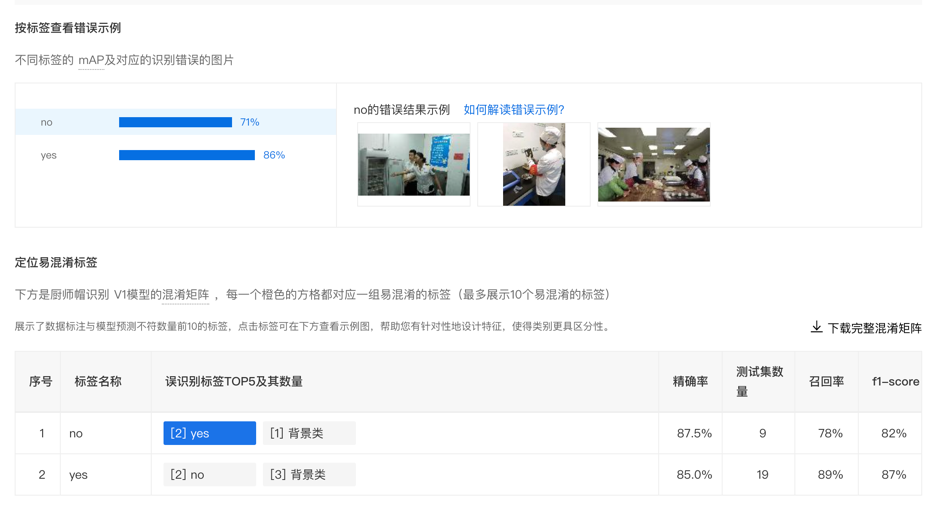
如果训练得到的模型效果未达到预期,可通过查看模型评估报告来进行分析,并针对性进行效果优化。在本例中,初次训练的模型mAP较低,不满足业务要求。
 通过进一步查看模型评估报告中的错误示例和混淆矩阵,可以对模型效果进行剖析,从而寻找到优化路径。
通过进一步查看模型评估报告中的错误示例和混淆矩阵,可以对模型效果进行剖析,从而寻找到优化路径。
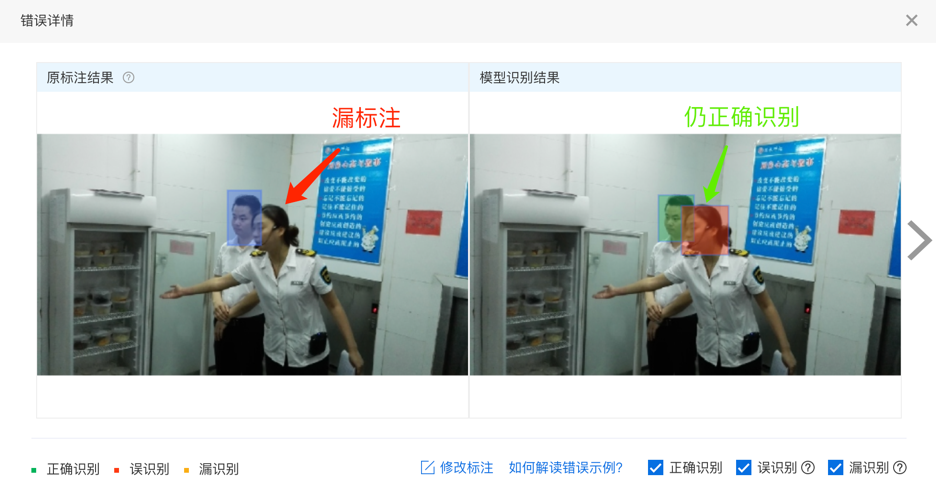
在错误示例中,可尝试找出模型错误结果中存在的规律,并通过优化数据集及标注的方式来提升模型效果。一般而言,数据集层面可能出现的情况有:错标注、漏标注、标注框不准确、样本不平衡(有的标签数据量多)、标签数据量过少等。在本例中,通过查看错误示例,我们发现了一些错标注、漏标注的情况。比如下图中有一张图片漏标了一个标签为“无安全帽”的矩形框。虽然在本张图片中的模型识别结果未受到影响,但仍会导致模型效果的降低,并且影响模型评估结果的准确性。
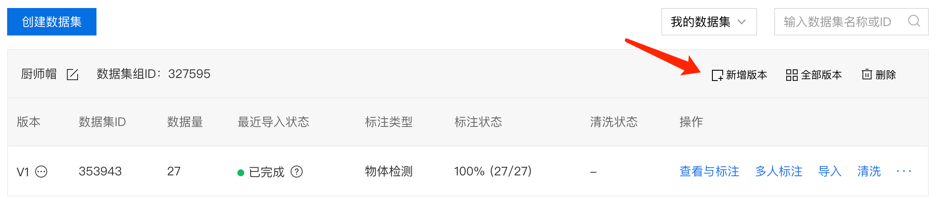
 根据错误示例中发现的问题,我们对标注框进行修正。建议使用新增版本功能为数据集增加一个V2版本,便于后续对模型进行回溯、对比。
根据错误示例中发现的问题,我们对标注框进行修正。建议使用新增版本功能为数据集增加一个V2版本,便于后续对模型进行回溯、对比。
 补充更多图片样本并对标注结果进行修正后,重新训练模型,发现模型的mAP和精确率均到了提升,其中mAP提升明显;但模型的召回率同时也有比较显著的下降。
补充更多图片样本并对标注结果进行修正后,重新训练模型,发现模型的mAP和精确率均到了提升,其中mAP提升明显;但模型的召回率同时也有比较显著的下降。
再次查看错误示例,可以发现新版模型漏检较多,主要集中在小目标物体上。因此,后续有条件的话建议继续补充小目标物体的样本数量,尝试提升模型召回率。
模型部署
在本例中,以餐饮小店等小型餐饮企业为例,厨房监控的视频路数一般不会太多。因此,为降低部署复杂度和硬件成本,可采用公有云API的部署模式,也就是将模型部署在公有云上,可按需调用模型,获取分析结果。
为部署至公有云,首先在“我的模型”中点击“申请发布”按钮。
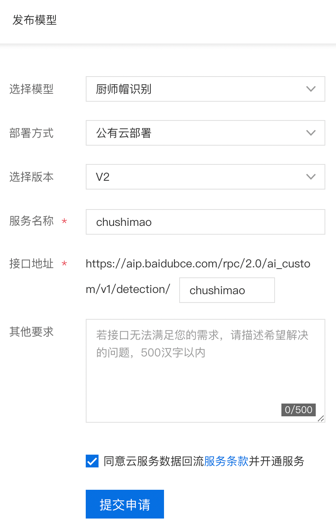
 然后填写发布模型所需的信息,点击“提交申请”。
然后填写发布模型所需的信息,点击“提交申请”。
 然后就可在公有云服务-在线服务中查看待发布的模型,当服务状态变为“已发布”后即可调用。
然后就可在公有云服务-在线服务中查看待发布的模型,当服务状态变为“已发布”后即可调用。
常见问题
问题1:我应该采集多少数据?这些数据有什么要求?
在数据采集数量上,一是要保证每个标签的数据量不低于50,理论上标签量越多,模型效果更好;二是尽量保证各个标签的数据量不要差异太大,也就是要具有一定的均衡性。在数据采集方式上,要尽量采集真实场景图片,不用使用非真实场景图片,如网络图片。 在本案例中,建议基于厂区摄像头视频数据来抽帧得到图像数据,建议包含至少100张具有抽烟标签的图片,有条件的情况下可进一步增加图片样本量。
问题2:公有云API部署后,为何是未发布状态? 模型申请发布后,后台将进行模型审核,通常的审核周期为T+1,即当天申请第二天可以审核完成。如果模型效果较差,发布可能会被拒绝。如果需要加急或遇到莫名被拒的情况,请在百度智能云控制台内提交工单反馈。
问题3:公有云API部署后,调用模型如何收费?
在线服务里列表中将展示模型的调用单价,单位为“点数/次”,其中1点=0.001元。例如,调用单价为17点/次,意味着模型的每次调用需花费0.017元。